














VERA: The Cloud Native Engine Revolutionizing Apache Flink® Blog Series
Welcome to part two of our three-part blog and video series that introduces Ververica Runtime Assembly (VERA), the cloud-native, ultra-high performance engine that powers Ververica’s Streaming Data Platform.
Under the Hood: VERA's Three Core Pillars
In the first blog of this series we discussed the creation of VERA, including the challenges that helped to drive the development of this powerful streaming data engine that powers Ververica’s Streaming Data Platform. In this blog, we’ll dive into the technical capabilities of the Three Core Pillars that comprise the VERA engine.
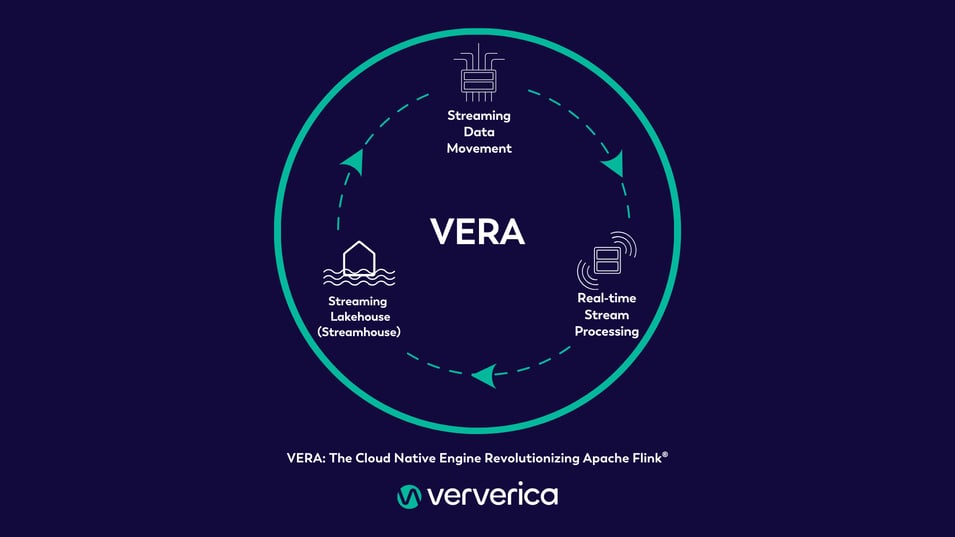
Figure 1: VERA AND THE THREE CORE PILLARS
VERA’s power comes from the Three Core Pillars:
- Streaming Data Movement
- Real-time Stream Processing
- Streaming Lakehouse (Streamhouse).
When combined, VERA and the Three Pillars provide a one-stop shop for all your data streaming needs, whether you are processing, storing, or moving data. Let’s take a closer look at each of these pillars and the benefits they offer.
Core Pillar #1: Streaming Data Movement
Figure 2: VERA CORE PILLAR: STREAMING DATA MOVEMENT
From Source to Sink
The first Core Pillar of VERA is Streaming Data Movement.
All data lives in different places, meaning your business decisions are also spread out over your architecture. Data lives in postgres. It lives in a MYSQL. It lives in any number of other operational data sources, and this has a huge effect on your tactical decisions.
Streaming Data Movement is the end-to-end process of utilizing Flink Change Data Capture (Flink CDC) to move data and events through VERA. This is accomplished by loading data generated from various applications and systems (often in different formats and volumes) and transforming it into a uniform type, then continuously processing that data in real time. This is followed by consuming the processed data and finally putting it into destination systems for potential later use, all while maintaining data lineage and security.
In essence, VERA absorbs data into a unified format, regardless of where it originated, and makes the data easily accessible and actionable. By seamlessly connecting, processing, and analyzing data throughout the data lifecycle, events are transformed into a uniform data set that you can then use to make data-driven decisions.
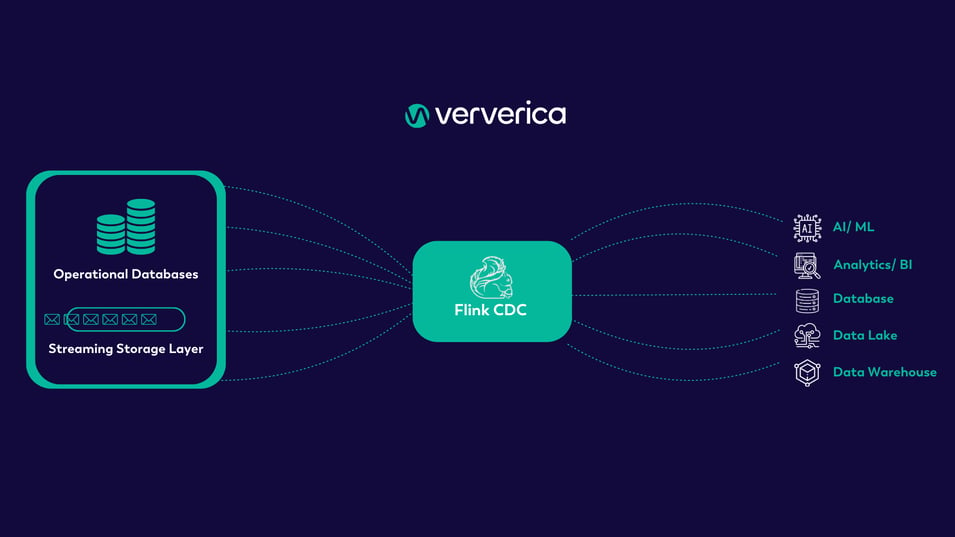
Figure 3: STREAMING DATA MOVEMENT - SOURCE TO SINK
Benefits For Users
Regardless of where your data originates, and no matter how much it grows over time, with VERA, you can easily access and format that data, run it through time-based processing, and then store it for later use and safekeeping. In addition, you can potentially use that data for future decisions that are on a slower timeline, or for use cases that require historical context.
VERA allows you to move all of your data and events into a common stateful processing layer, and provides you with a unified, 365-degree, real-time view and processing window into that data. In addition, VERA doesn’t care if you prefer developing apps with Java, Python, or SQL, as it offers all three options out-of-the-box. All of this functionality is available without compromising the performance, security, or reliability of your underlying systems.
In short: Streaming Data Movement makes all of your data easily available, so you can take action faster and make better-informed business decisions using that data.
Learn More About Flink CDC
Ververica is proud to have contributed Flink CDC to the Apache Software Foundation in early 2024. To learn more about Flink CDC, check out this blog post.
Core Pillar #2: Real-time Stream Processing
Figure 2: VERA CORE PILLAR: REAL-TIME STREAM PROCESSING
Get the Power of Now
The second Core Pillar of the VERA engine is Real-time Stream Processing.
Processing and acting on your data in real time allows you to extract immediate meaning and insight from data, and removes the historical lag and wait time of batch processing. In fact, the vast majority of today’s successful online real-time experiences are powered by Apache Flink.
Consumers may not realize what is happening under the hood, but Flink underpins nearly every real-time transaction, be that an instant review, travel booking, an online purchase, a delivery or transportation service, an instant insurance claim, or notifications of identity fraud or credit card protection alerts. In addition, countless financial and banking interactions happen thanks to Flink, along with massive online multiplayer gameplay, social media applications, and any services that use the conventional concept of “streaming”. Of course, this only scrapes the surface of the use cases that Flink helps to solve.
Simply put: our lives without Flink would be very different.
Listen as Ben Gamble, Ververica Field CTO briefly explains the Power of Now in the 40-second video:
>You can also watch the entire short video playlist: "Introducing VERA The Engine Revolutionizing Apache Flink"> available now on YouTube, during which Ben shares his thoughts on the creation of VERA and digs further into each of the core pillars.
Enter Scalable, Flexible VERA
While OS Flink can solve an abundance of use cases, it is not without some challenges. VERA solves Flink’s limitations, (as discussed in the first blog in this series,) including the costs incurred when trying to dramatically scale Flink applications.
VERA is highly scalable and stable, thanks to the decoupling of the storage and compute layers, and is optimized to deliver both stream processing and batch processing capabilities that allow for stateful computations over data streams. VERA manages the execution of Flink applications and seamlessly integrates with Flink and Flink APIs, which in turn allows developers to process and analyze large amounts of data to extract insights in real time.
Since data and traffic demands can fluctuate wildly, having the ability to easily and elastically scale capacity to any size; whether up or down, side to side, and back again, is paramount. For example, if one of your posts goes viral, or a huge number of consumers suddenly flock to your ticketing website, you don’t want that system to suddenly go down because of your sudden popularity and success. Utilizing open core VERA, built with Flink, gives you a safety net complete with built-in scalability, that also provides more flexibility, better performance, and lower overhead than traditional deployments.
Because VERA is designed for stateful stream processing and streaming analytics, in addition to processing data in real time, it inherently supports both data at rest (batch data pipelines and data stored in object stores), and data-in-motion (streaming pipelines and real-time use cases). Simply put, whether you need real time streaming or batch processing to solve a business need, VERA supports both.
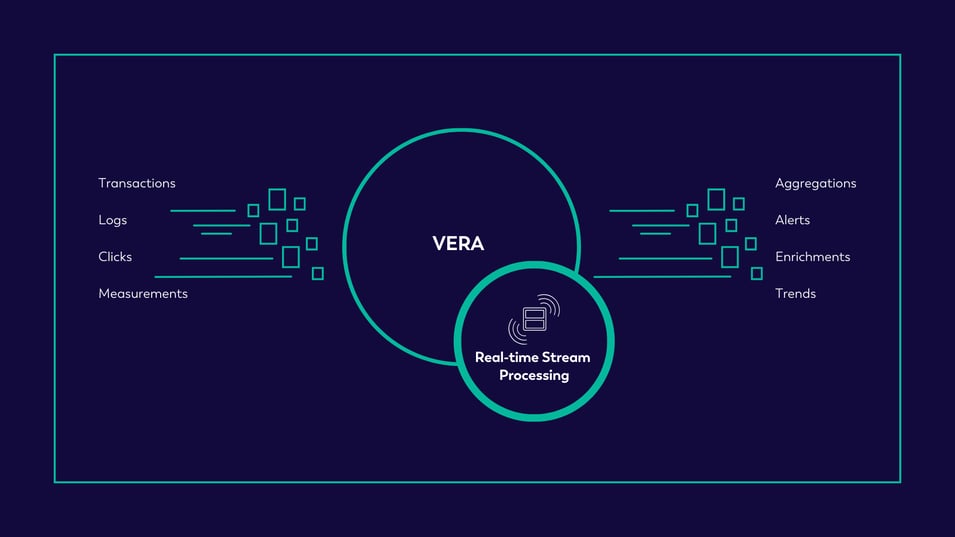
Figure 5: REAL-TIME STREAM PROCESSING EMPOWERING BUSINESSES WITH REAL-TIME DATA INSIGHTS (THE POWER OF NOW)
Benefits For Users
For many modern use cases, failing to provide immediate transactions that execute flawlessly can result in unhappy customer experiences, reduced security, and any number of other negative business outcomes. Because VERA allows users to act on data as it arrives, and is continuously processing that data, you can stop waiting for data to catch up, and instead make fast, reliable decisions using the freshest information available.
In short, any piece of data that is inherently time-bound, whether happening asynchronously, or subject to an absolute time window guarantee, requires the highly scalable, elastic, and more stable real-time processing that VERA offers.
Here are a few more examples of the infinite use cases that can benefit from VERA’s real-time stream processing abilities:
- Providing up-to-date travel, weather, or fire warnings – because map updates using data from a quiet afternoon drive while you’re in the middle of a morning rush hour aren't relevant or helpful.
- Making a trade on a Stock Exchange – time is most definitely of the essence for any use case in which time=money.
- Scanning tickets for concert entry – nobody wants to be denied access to an event for which they have a ticket.
- Giving movie recommendations – late recommendations for a movie on a streaming app several weeks after your last venture into that specific genre aren’t necessarily high-risk, but they also aren't as meaningful as immediate suggestions that keep a consumer engaged and watching.
The VERA engine handles these situations with ease, boosting your business relevance by giving you the ability to make instantaneous decisions, with highly relevant and current data, and allowing you to act with Power of Now. The Power of Now means that you can take action on your data as it arrives, in whatever format it arrives, and use it to make immediate decisions.
Core Pillar #3: Streaming Lakehouse (Streamhouse)
%20(2)-1.png?width=955&height=537&name=NEED%20Streamhouse%20Push%20(WIP)%20(2)-1.png)
Figure 6: VERA CORE PILLAR: STREAMING LAKEHOUSE (STREAMHOUSE)
Who Said Data Lakes Have to be Slow?
The third Core Pillar of the VERA engine is Streaming Lakehouse.
VERA combines Apache Flink for stream processing with Apache Paimon on the streaming storage layer. At Ververica, we call this Streamhouse, and it delivers stream processing capabilities while maintaining near-real-time results on the Data Lake.
The Alternatives
In order to understand why Streaming Lakehouse architecture was created, and why it’s so powerful, let’s take a quick look at the alternatives.
In the past, when mainframes were predominant, storage was incredibly expensive and, as a result, Data Warehouses were created. Data Warehouses are great for storing and managing large volumes of structured data using predefined, fixed schema, but you already need to know ahead of time what outcomes you might want from any data you keep before you place it in a Data Warehouse. In addition, Data Warehouses are also still quite expensive, particularly once you begin to scale your data volume, and you run the potential risks of storing expensive data you’ll never use, or missing important data entirely due to budget constraints.
It didn’t take long for storage and bandwidth to begin to drop in cost, and at that point it became more cost effective to keep every last piece of data, transferring and placing it all into the next evolution: the Data Lake. Data Lakes are huge libraries (akin to our kitchen junk drawers) of both structured and unstructured data, which allow a business to store all of their data in raw, original formats. Data Lakes make it easier to store large amounts of data without having to maintain structure, and allow access to that data to make future decisions.
With Data Lakes, it became possible to keep every piece of data, whether or not it would prove to be useful or usable in the future, and then put it through a query engine to pull relevant decisions at a later time.
What became very clear, very quickly, is that data is extremely valuable, and the value of data (often) depreciates over time. Relying on predefined outcomes or bulk data collection with exact-transform-load (ETL) solutions fails to address the speed and accuracy requirements of modern decision-making processes. While both Data Warehouses and Data Lakes each solve part of a larger challenge, neither solution gives us a truly fast, accurate, and cost-effective way to act on our data.
Balancing Act
Data Warehouses are expensive, because you pay for the index, you pay for a query engine that you may or may not be using, and you pay for reformatting.
Meanwhile, Data Lakes are a much less expensive place to store immense amounts of data, but their accuracy is measured in hours, not seconds, making them far from real-time. This is great if you have a use case that can wait, but not good when you’re faced with a tight timeline and the need for immediate analytics.
What if you could get the best of both worlds? Imagine a Data Lake that is accurate in seconds, and the richness of queries from your Data Warehouse, all at the cost of your Data Lake?
This is where Streaming Lakehouse (Streamhouse) was born.
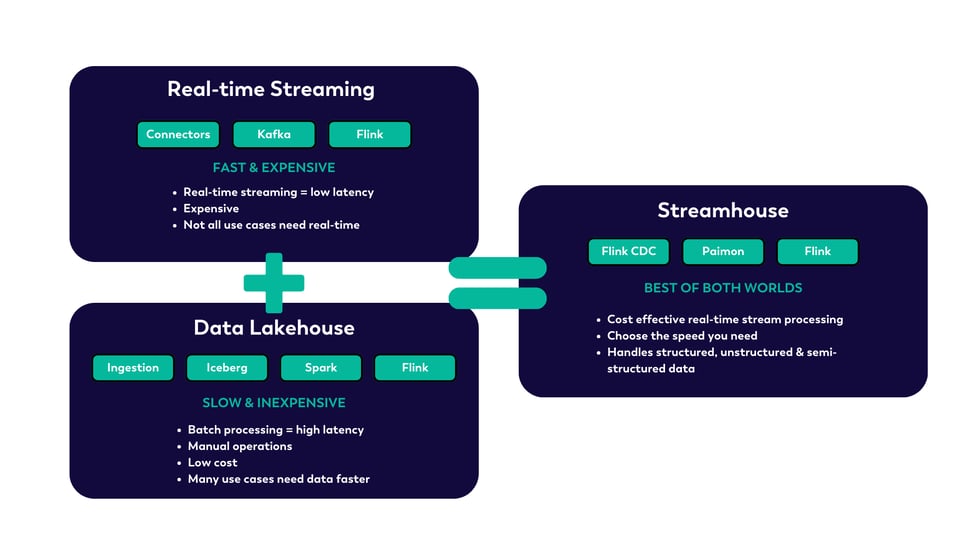
Figure 7: REAL-TIME STREAMING + DATA LAKEHOUSE = STREAMHOUSE
The Streaming Lakehouse (Streamhouse)
Streamhouse is stream processing on the Lakehouse. It’s the next big thing in streaming analytics that combines streaming with the Lakehouse, making stream processing cost efficient and easily accessible to everyone.
%20%20(1).png?width=955&height=537&name=NEED%20Streaming%20Lakehouse%20(Streamhouse)%20%20(1).png)
Figure 8: STREAMHOUSE
Jing Ge, Ververica CTO and Apache Flink Committer and PMC Member, first introduced the concept and coined the name "Streamhouse" at Flink Forward Seattle in 2023, which you can read more about in his blog: Streamhouse Unveiled.
At its essence, Streamhouse provides Flink with a storage layer that leverages a table format to make data in dynamic tables directly accessible. Let’s take a quick look at how Streamhouse achieves this:
- Flink CDC handles data ingestion and adds the lake entries.
- Flink SQL performs streaming and batch ETL, and ad-hoc analysis.
- A set of engines completes data entry, analysis, and queries.
Benefits For Users
We, (both humans and now AI,) generate A LOT of data, much of which we’ve placed in relatively cheap storage options, without necessarily giving much thought to how and why we might want to access and use that data in the future. Streamhouse navigates the fine line between two existing worlds: historically, real-time streaming is super low latency but very costly, while traditional Lakehouse batch processing may be inexpensive, but is also very slow.
VERA provides the best of both worlds: nearly unlimited storage inside your streaming compute engine means you can run queries across petabytes (or exabytes!) of data without having to compromise your ability to store it in a cost-effective manner.
In addition, with Streamhouse, you can run real-time and near real-time stream processing from one powerful engine, giving you the ability to make informed decisions leveraging both current and historical data.
Learn More About Streamhouse
Curious to learn more about Streamhouse? In addition to Jing's blog, here are a few recommended resources:
- Streamhouse: Data Processing Patterns
- Stream Processing & Apache Flink - News and Best Practices
- Apache Paimon: The Streaming Lakehouse
- Building Real-time Data Views with Streamhouse
Start Your Engine: What Do You Want From Your Data?
In this blog, we’ve introduced the Three Core Pillars of VERA, the engine that powers Ververica’s Streaming Data Platform, which allows you to connect, process, analyze, and govern your data in one streaming data solution.
When combined, VERA's Streaming Data Movement, Real-Time Stream Processing, and Streamhouse provide powerful technical capabilities and allow you to further explore what you require from your data.
Quick Exercise & Conclusion
Ask yourself:
What do you want from your data?
I want data that…
- Moves beyond analysis into action.
- Allows me to make informed decisions using both current and historical events.
- Answers complicated questions and use cases, even those with multiple components.
- Can scale from zero to infinity, and back again.
- Runs in real-time and supports batch.
- Processes data while streaming, without being cost-prohibitive.
- Is available in an easy-to-use, consistent, and unified format.
- Resolves conflicts and allows roll-backs in time.
- Provides the best of Flink and data streaming, without having to run and build the solution, architecture or infrastructure myself.
If your answers align with the above, and you are ready to talk about what you want from your data, Ververica can help. Contact us to see a demo, or spin up a deployment of Ververica Cloud and get started using VERA with $400 free credits.
Up next, in part three of this blog series, we’ll take an even deeper look at VERA’s features and benefits, as well as share some of the performance metrics real users are experiencing using VERA today. We’ll also peek into the future of Ververica’s Streaming Data Platform.
Available now! VERA: The Cloud Native Engine Revolutionizing Apache Flink® Blog Series:
- Part One: From Stream to Stream
- Part Three: Full Stream Ahead: The Capabilities and Benefits of VERA
More Resources
- Learn more about VERA.
- Watch more of the interview with Ben Gamble discussing VERA on YouTube.
- Access the VERA docs.
- Ready to get started? Take VERA for a test run by spinning up your own Ververica Cloud deployment.
- Have questions? Our team can help! Contact us.
- Join the Apache Flink Community at Flink Forward Berlin 2024, filled with Flink training courses, expert speakers, networking, an entire track dedicated to Flink use cases, and much more.
Thanks!
This blog series wouldn't be possible without the contributions of the many PMC Members, engineers, Ververicans and community members who’ve spent long days creating VERA, in addition to contributing to the Apache Flink project and repo, and supporting additional projects including Apache Paimon and Flink CDC.
In addition, special thanks to Dawn Leamon for her editing expertise and the video content (in addition to her many other talents).
You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
