














Apache Flink: History of Reliability
Every year, Apache Flink® sets new records in its development journey. Standing as a testament to its growing popularity, Flink now boosts over 1.6k contributors, 21k GitHub stars, and 1.4M downloads. In operational environments, Flink clusters are reaching impressive scales, with some individual clusters surpassing 2000 nodes. The largest known Flink infrastructure in production boasts over 4 million CPU cores, processing a staggering 4.1B events per second. If scalability is a concern, Flink has proven itself in the industry and stands as a reliable choice.
Over the past few years, Flink has witnessed widespread adoption across diverse industries, ranging from e-commerce and finance to gaming and healthcare. Mature solutions powered by Flink, such as personalized recommendations and robust risk control systems, now play a pivotal role in shaping the daily experiences of individuals.
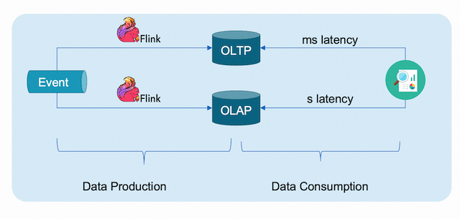
As an industry-proven and de facto standard for streaming data processing, Flink is seamlessly integrated into various scenarios. Whether it's processing data and storing results in OLTP databases for consumption by online applications, or sinking results into OLAP databases for analytics applications, Flink continues to be a driving force behind real-time decision making based on streaming data.
Foundational Architecture
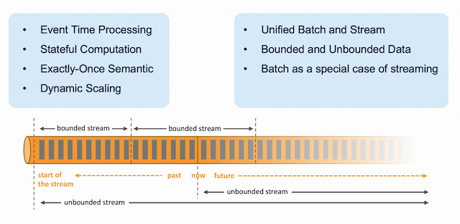
Before delving into the future of Flink, let's explore its foundational architecture. Flink boasts incredible features for streaming data processing, including stateful computation and exactly-once semantics. Of particular interest is its unified approach to batch and stream processing, where batch is treated as a specialized case of streaming. This means a single engine can seamlessly handle both bounded and unbounded data. Given Flink's prowess in streaming data processing, our focus will now shift toward enhancing batch capabilities.
In the realm of batch data processing, data warehouses and data lakes play pivotal roles. Data warehouses process structured data through ETL pipelines, with the results serving as fodder for other applications. As the data landscape evolves, especially with the surge in AI requirements, data lakes have emerged to store raw data of varied structures, including structured, semi-structured, and unstructured.
Enter the Lakehouse, an evolution of the data lake that aims to unify the strengths of data warehouses and data lakes. Lakehouses offers the scalability and flexibility inherent to data lakes, coupled with metadata and table formats.
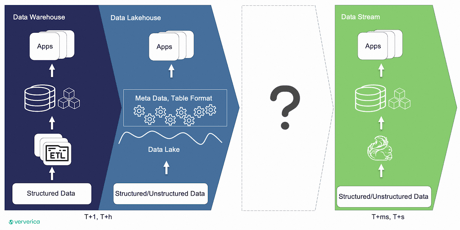
Bringing data streaming processing into the mix with data warehouses and Lakehouses reveals a distinction. Traditional Lakehouses exhibit daily or hourly data latency, while data streaming achieves remarkable second or even millisecond latency. This creates a noticeable gap between them.
Cost and Latency
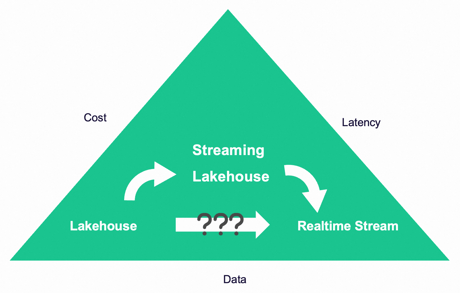
In the realm of data processing, two crucial factors always come into play: cost and result latency. Visualizing this relationship, we can refer to it as the data processing triangle. If cost is a primary concern, the choice leans towards a Lakehouse; if latency takes precedence, real-time streaming becomes the preferred option. Real-time streams are indispensable for specific business cases such as risk control, while Lakehouses, through batch data processing, cater to a myriad of other scenarios and use cases.
As businesses grow and their dynamics become clearer, the need for low-latency data arises. The immediate consideration is often migrating jobs from a Lakehouse to a real-time stream. But does this transition truly make sense?
In large organizations running hundreds of thousands of batch jobs, the scarcity of streaming jobs is questioned. The common response attributes this scarcity to the absence of real-time business requirements. However, this seems paradoxical, as faster decision making inherently accelerates business operations—time is money, after all. An alternative perspective posits that perhaps the lack of readiness in streaming infrastructure is impeding the recognition of real-time business needs. The counterargument to this is that streaming jobs are typically expensive, leading to a dilemma: is it justified to invest significantly in building infrastructure when the business requirement is uncertain?
This predicament resembles a chicken-and-egg scenario: no business requirements, no streaming infrastructure; no streaming infrastructure, no recognition of real-time business needs. The crux lies in Return on Investment (ROI) and managing costs.
The overarching question emerges: is there a more efficient, cost-effective, and consequently, low-risk method to facilitate system upgrades?
Major Disruptor: Introducing Streamhouse
Streamhouse disrupts the deadlock by providing a solution to upgrade high-latency batch jobs to Streamhouse with near-real-time latency. This allows businesses to assess its suitability by running operations and gauging results. After obtaining business outcomes, an evaluation of the ROI becomes feasible. The decision then rests on either adhering to Streamhouse with optimized costs or progressing further to real-time streaming computation. The seamless migration facilitated by the Flink unified engine and Flink SQL minimizes the effort involved.
This approach aligns with the data processing triangle concept, leading to the evolution of a data processing architecture pattern termed LSR (Lakehouse, Streamhouse, and Real-time stream). The cost increment occurs progressively from Lakehouse to Streamhouse and then to real-time streaming.
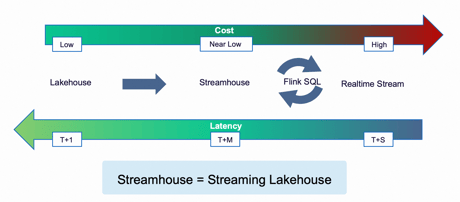
The advantages of utilizing Streamhouse are twofold. Firstly, the significant improvement in latency from days to minutes outweighs the increased cost compared to Lakehouse. Secondly, leveraging Flink SQL provides users with flexibility, allowing them to transition between Streamhouse and real-time stream based on evolving business requirements.
Four Components of a Data Processing Pipeline
In any data processing pipeline, four key components play crucial roles: data ingestion, data computation, metadata, and data storage. Lakehouse and streaming data processing differ in their approaches. Lakehouse relies on batch ETL, batch data processing, and batch table format, saving data in object storage. On the other hand, streaming involves ingesting data in streaming mode, supporting Change Data Capture (CDC). Streaming processing engines like Flink process the data, with additional services like schema registry managing the schema, and data stored in the message system.
Streamhouse: Best of Both Worlds
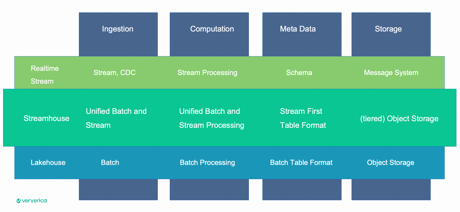
Streamhouse integrates aspects of both approaches. It processes data in both batch and streaming modes, with the table format aligning with streaming concepts. While data can be saved into tiered object storage, cost-effective object storage is typically sufficient for most cases.
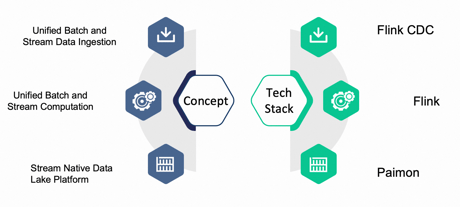
To implement Streamhouse, Flink serves as the ideal computation engine due to its unified batch and stream architecture. We've extended Flink's capabilities by developing Flink CDC, facilitating unified batch and stream data ingestion. Additionally, we've introduced Apache Paimon as the stream-native data lake platform surrounding Flink.
Flink CDC
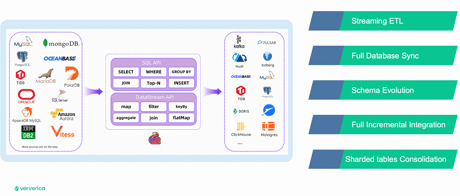
Flink CDC stands as the initial component in the Streamhouse tech stack. Its primary responsibility lies in ingesting data in both batch and stream formats. The transition between batch initial load and incremental load is smooth and devoid of locks. Flink CDC offers compatibility with a majority of mainstream databases and incorporates numerous features crafted in response to real business needs. Examples include full database synchronization and the consolidation of sharded tables.

To propel Flink into the Streamhouse era, our efforts extend beyond refining the core engine; we're dedicated to unifying batch and streaming functionalities.
For instance:
- Elevating SQL capabilities with enhancements such as dynamic partition pruning and runtime filters to minimize redundant data IO and network transmissions.
- Implementing an operator fusion code generator to harness the full potential of modern CPUs.
- Actively constructing APIs to align with the Lakehouse concept.
Let's explore more details about the engine and the improvements made in Flink SQL.
The checkpoint duration plays a crucial role in end-to-end latency. A shorter checkpoint duration translates to lower latencies for transactional sinks, more predictable checkpoint intervals for daily operations, and less data to recover. Improving checkpoint duration involves addressing two major factors: the travel time of barriers through the pipeline and the time taken for checkpoints.
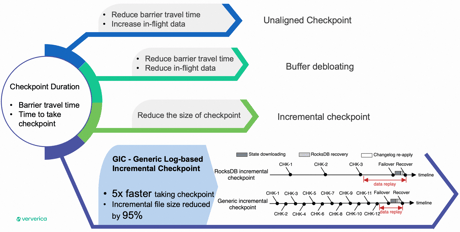
The Flink community has undertaken significant optimization efforts based on these factors. Unaligned checkpoints, while reducing barrier travel time, may increase in-flight data as a side effect. Buffer debloating uses dynamic buffer size management to reduce both barrier travel time and in-flight data. Incremental checkpoints leverage the RocksDB LSM tree to persist only newly created SSTABLE files, thereby reducing checkpoint size.
The GIC (Generic Log-based Incremental Checkpoint) introduces a state changelog, further reducing checkpoint duration and supporting an even shorter checkpoint interval. Statistics indicate that GIC could provide five times faster checkpointing, with the incremental file size significantly reduced by 95%.
Hybrid Shuffle emerges as a pivotal feature in the unification of batch and stream processing. While Pipeline Shuffle offers superior performance, it demands more resources as all interconnected tasks must start simultaneously. The allure of using Pipeline Shuffle in batch execution is tempered by challenges, especially in production environments where resource availability isn't guaranteed. The competition among multiple tasks for resources can even lead to deadlocks.
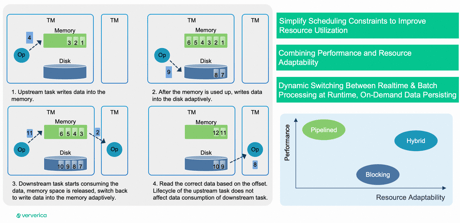
Hybrid Shuffle presents a solution by combining the strengths of Blocking Shuffle and Pipelined Shuffle. Streaming shuffle is employed only when resources are abundant, allowing tasks connected to each other to launch simultaneously. When resources become scarce, it gracefully falls back to batch shuffle. This approach ensures more efficient resource utilization for shuffle acceleration.
Apache Flink 2.0
In Flink 2.0, the community is set to elevate the Flink state storage management system by transitioning to a fully decoupled storage and computation architecture, aligning with the demands of a cloud-native environment.
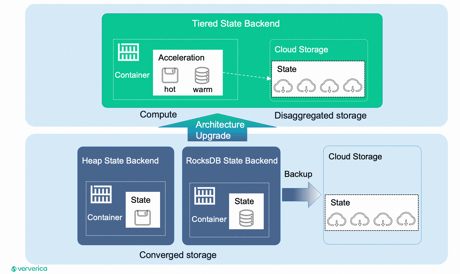
Currently, Flink's state storage system doesn't fully embody a storage-computation separation architecture. All state data resides in local RocksDB instances, and only incremental data is transferred to remote storage during distributed snapshots to guarantee complete state data storage remotely. Looking ahead, Flink envisions relocating its state data entirely to remote storage, reserving local disks and memory exclusively for caching and acceleration.
This transformative move will establish a tiered storage system referred to as the 'Tiered State Backend' architecture.
Key Enhancements Envisioned:
- Implementation of a tiered storage system where data with varying temperatures will be stored on different hardware to optimize access performance.
- Introduction of query optimizations such as hash indexing or sorted indexing to further enhance performance.
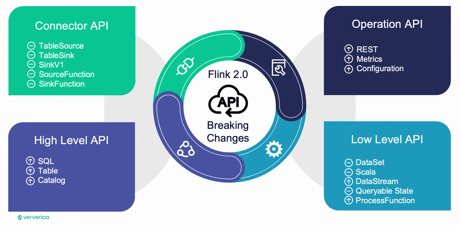
In Flink 2.0, a significant objective is the execution of API Evolution, which involves restructuring the API into four distinct categories:
- Low-Level API: Includes functionalities like processFunction and DataStream.
- High-Level API: Encompasses Table and SQL functionalities.
- Connector API: Covers e.g. Source- and Sink-functions, for example.
- Operation API: Includes metrics, configuration, and RESTful API.
The evolution unfolds in two phases:
- Phase one: Breaking Changes
- Removal of legacy API elements like DataSet, SourceFunction and SinkFunction, TableSource, and TableSink.
- Cleanup of deprecated classes, methods, fields in the Java API, along with deprecated configuration options, metrics, and REST API endpoints.
- Phase two: API Redesign:
- Introduction of a new queryable state API post the implementation of Disaggregated State.
- Refactoring the DataStream API with a new ProcessFunction, eliminating internal dependencies and preventing the exposure of internal APIs.
- Introduction of a new, clean configuration layer.
Flink, renowned for its prowess in streaming data processing, offers a robust framework for low-level data stream manipulation. However, for the majority of end users, Flink SQL is the recommended approach. Why SQL? Because it provides a high-level, declarative API that allows users to concentrate on their specific business logics, leveraging domain expertise in areas like feature engineering in AI, user behavior in e-commerce, and clinical research in the medical field. In these scenarios, where strong domain expertise is crucial, users prefer not to grapple with the intricacies of the underlying technologies.
By adopting SQL as the abstraction layer, Flink creates a symbiotic relationship. Users can focus solely on their business requirements, while Flink relentlessly concentrates on data processing and continuous optimization.
Regarding SQL capabilities, Flink already offers an extensive set of syntax, including DDL, DML, aggregation, joins, and more. Yet the full potential of Flink SQL is often underestimated. It can be categorized into four main types:
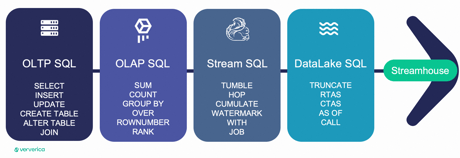
- OLTP SQL: for traditional data manipulation and querying.
- OLAP SQL: for data warehouse ETL processes.
- Stream SQL: for unique streaming data processing logic, such as tumble or hop windows.
- Data Lake SQL: for executing common lake house tasks, like creating a table as select.
With these powerful SQL capabilities, users can accomplish a wide array of tasks.
Apache Paimon
Having delved into Flink CDC and Flink, let's explore the storage platform integral to the Streamhouse - Apache Paimon. Born as a Flink sub-project under the moniker "Table Store," Paimon has evolved into an Apache incubator project.
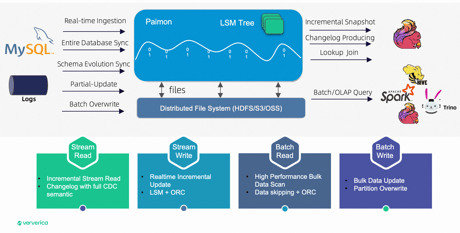
While the internal table format draws strong inspiration from Apache Iceberg, incorporating concepts like snapshots and manifest files, its underlying data structure aligns with log-structured merge-trees (LSM), tailor made for streaming.
This architecture positions Paimon as a unified batch and stream data lake platform, boasting various exciting features:
- Adept support for both batch read/write and stream read/write operations.
- Provision of scalable metadata by leveraging cost-effective data lake storage.
- Enhanced versatility, through the use o rich merge engines, such as deduplication (retraining the last entry), partial update, and aggregation.
- Simplified construction of streaming pipelines through Changelog producers, offering various patterns like 'input,' 'lookup,' and 'full-compaction.' This ensures easy creation and management of changelogs for your data.
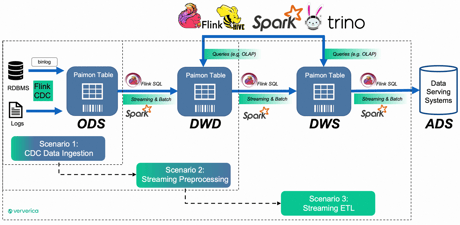
Examining common data processing pipelines involving ODS ingestion, DWD transformation, and DWS, several intriguing scenarios emerge:
- Scenario 1: Solely leverage Flink CDC and Paimon for CDC data ingestion. Continue utilizing Spark to read operational data from ODS and execute Spark batch processing.
-
Scenario 2: Deploy Flink SQL for streaming or batch ETL from ODS to DWD. Allow OLAP engines to consume DWD, resulting in a significant reduction in end-to-end data latency.
-
Scenario 3: Utilize Flink SQL to construct end-to-end streaming mixed ETL processing (streaming and batch). Employ a unified technology for diverse data processing tasks, effectively reducing both development and operational costs.
The Flexible FFP Architecture empowers you to enhance end-to-end data latency at your own pace, aligning with real business requirements. The beauty lies in the graceful progression within your existing Lakehouse, allowing step-by-step improvements that generate tangible business value. This approach instills confidence, making it easier to venture into more advanced stages.
Welcome to Streamhouse!
The Streamhouse concept was introduced as a result of recognizing the gap between Lakehouse and real-time streaming data processing. Streamhouse was implemented by reshaping Flink and introducing tools like Flink CDC and Paimon. The result is a comprehensive evolution of the LSR data processing architecture—one driven by business value.
The architecture's flexibility shines when cost considerations take center stage, a crucial aspect in the current global economy. While there are use cases justifying direct investment in real-time streaming, the majority of batch data processing scenarios find effective solutions in the Lakehouse. Illustrating this point with examples like Iceberg and Spark, it's apparent that you might have your own tech stack for the Lakehouse.
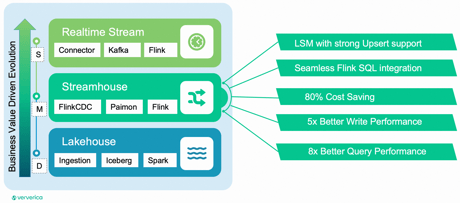
As your business expands and the need for fresher data grows, the Streamhouse becomes an appealing choice to improve data latency from a daily to a minute-by-minute scale. Every element, from conceptual understanding to real tech stacks, is readily available. Importantly, leveraging the same Flink technology ensures smooth upgrades to real-time streaming with minimal effort.
The work accomplished at Ververcia demonstrates that, with an acceptable minute data latency, Streamhouse can significantly cut costs by 80% compared to real-time streaming. Employing streaming preprocessing within the Streamhouse yields five times better write performance and eight times better query performance when contrasted with traditional batch Lakehouses.
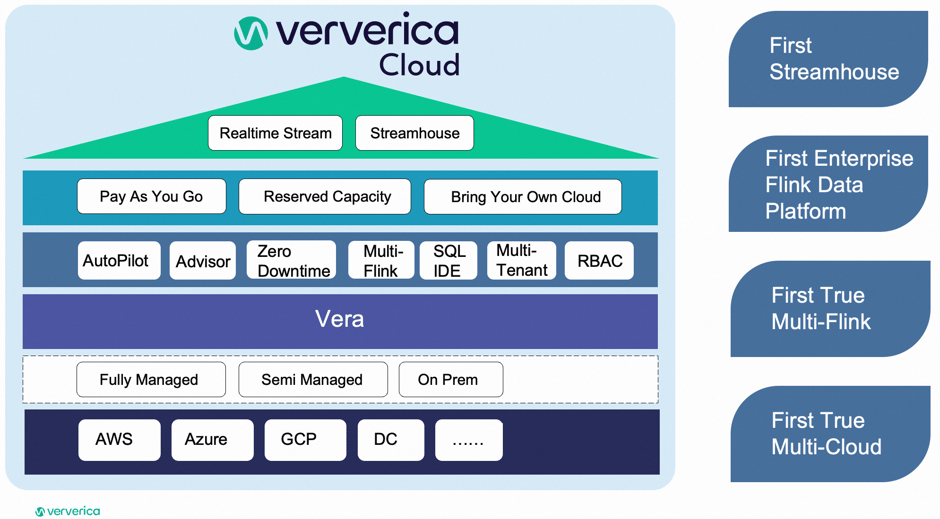
Ververica Cloud
Based on these insights, Ververica built the next-generation data platform, Ververica Cloud, with a vision to empower customers to run their jobs anywhere, enhancing both development and operational efficiency. Ververica Cloud's architecture is open and flexible, supporting fully managed, semi-managed, and on-premises deployment modes. This architecture abstracts the diversity of cloud providers, allowing users to execute jobs directly in any cloud where their data is stored.
Ververica Runtime Assembly (VERA), the enterprise engine, is 100% Flink compatible and offers superior performance. Certain features of VERA will be contributed back to the open-source community in the future. At the platform level, Ververica Cloud introduces services like Autopilot, which leverages user data to train AI models for automatic resource scheduling, and Advisor, a repository of troubleshooting knowledge providing hints and suggestions for Flink job issues.
As a cost-effective product, Ververica Cloud offers flexible pricing options, including Pay-As-You-Go (PAYG) and Reserved Capacity (RC), tailored to diverse business requirements. Larger companies even have the option to bring their own cloud (BYOC) and integrate it with the Ververica ecosystem.
Additionally, at the conceptual level, Ververica Cloud is the first and only platform that supports both real-time streaming and Streamhouse. As customers, you will have the flexibility to start with Streamhouse and then decide to upgrade to real-time streaming or simply kick off with real-time streaming directly.
Lastly, at Ververica, we will continue our efforts on Streamhouse, both within Ververica Cloud and open-source Apache Flink, to support a broader range of business scenarios, consistently optimizing costs and improving value.
Ready to reach speeds of up to 2x faster than open source Apache Flink? Sign up for Ververica Cloud for free and receive $400 cloud credit.
More Resources
- See all the highlights from Flink Forward Seattle 2023 in this short blog.
- To explore the most recent updates and features, please visit Ververica Documentation.
- Learn more about Ververica Cloud.

You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
