














VERA: The Cloud Native Engine Revolutionizing Apache Flink® Blog Series
Welcome to part one of a three-part blog series that introduces Ververica Runtime Assembly (VERA), the cloud-native, ultra-high-performance engine that powers Ververica’s Streaming Data Platform. In this first piece, we'll discuss the drivers behind the evolution and creation of the VERA engine.
From Steam to Stream: Introduction to VERA
Stream processing enables the handling of continuous data streams from an array of sources, including, (but in no way limited to) financial transactions, website analytics, and data from IoT devices. While this technology is not new – the ability to send data over the wire and act on it has been available for a long time now – the ever-increasing number of sources and the sheer scale of data being created makes for an extremely complicated and resource-hungry task. As a result, stream processing on a single machine is usually no longer feasible for businesses and organizations that now process massive data sets across distributed systems consisting of thousands of distributed machines.
While an open-source solution might seem like an attractive proposition, most companies lack the internal resources or expertise required to build the supporting architecture and infrastructure necessary to run complicated solutions using purely open source technologies. That’s precisely why Ververica, (the original creators of Apache Flink®, the open source toolkit that can harness data and analyze it in real time) offers our Streaming Data Platform. Ververica’s Streaming Data Platform handles the complexity of streaming data solutions for businesses looking to quickly and easily harness the power of their data. We do this by unifying the operational, tactical, and strategic decisions required to process distributed data streams in the modern world.
Meet VERA
Ververica Runtime Assembly (VERA) is the ultra-high performance, cloud-native engine that optimizes Apache Flink and powers Ververica’s Streaming Data Platform. VERA solves the challenges that come with managing large volumes of distributed data, by allowing you to quickly make mission-critical, data-driven decisions. Rather than having to wait for data to be collected and processed before you can act on it, you can analyze and use data in real time. This means you have an immediate realization of value, making your decisions with the most up-to-date information possible. Built to revolutionize Apache Flink, VERA is the stream data processing engine of the future, designed to unify both batch processing and real-time stream processing use cases within one powerful solution.
But what does it mean to say that VERA is revolutionizing Flink? Simply put, VERA is a combination of breakthrough technologies that supply dramatic improvements in efficiency, speed, and scalability when compared to other streaming solutions, including Open Source Apache Flink.
VERA functions as the heart of Ververica’s Streaming Data Platform, and combines the power of three technologies into a singular engine that allows you to connect, process, analyze, and govern your data in one unified streaming data solution. We call these technologies the Three Core Pillars of VERA, and they are:
- Streaming Data Movement
- Real-time Stream Processing
- Streaming Lakehouse (Ververica’s Streamhouse).
Working together, these pillars provide seamless support for data ingestion, stream processing in real time, and streaming Lakehouse architectures. As a result, VERA democratizes stream processing and allows you to choose the functionalities you need to solve an infinite number of streaming data use cases.
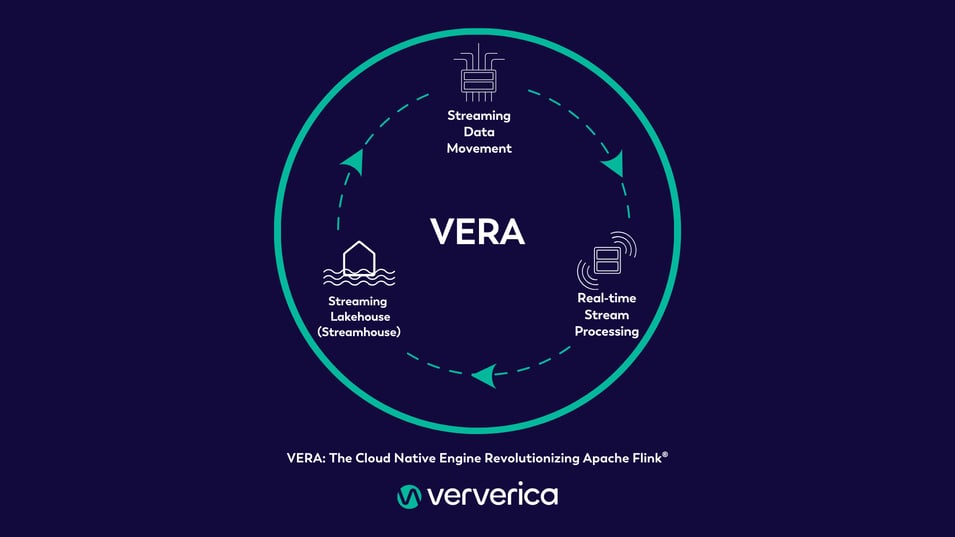
Figure 1: VERA AND THE THREE CORE PILLARS
In the second blog in this series, we deep dive into the technology behind each of the three core pillars that comprise the VERA engine. For now, let’s explore why VERA was created in the first place.
The Evolution of VERA: Why Do You Need VERA?
While VERA is an integral part of Ververica’s Streaming Data Platform, it is the engine that powers the Streaming Data Platform, rather than a stand-alone product. Understanding why VERA was built, and the challenges it helps to solve provides clarity into the business advantages it offers and the astonishing number of streaming data use cases it can solve.
For those who want to self-manage their data stream processing systems, VERA doesn’t displace open-source Apache Flink. In fact, Ververica continues to contribute heavily to the Apache Flink community and OS project. Intentionally, VERA, and Ververica’s Streaming Data Platform, are open-core technologies, built to be 100% compatible with OS Flink, so there is never a worry of vendor lock-in.
"If it says Flink on the outside, it's Flink on the inside."
-Alex Walden, Ververica CEO
The combination of using established Flink technology with the robust additional capabilities available in VERA is what allows Ververica to offer a superior service, boasting phenomenal speed and scalability. Better yet, this service is available in the deployment method of your choice, so whether you want Ververica clusters hosted on Ververica’s public cloud, or clusters deployed and managed on-premise, VERA is full stream ahead.
Hear more about VERA and the 3 Core Pillars in this 1.5 minute video from Ben Gamble, Ververica Field CTO:
You can also watch the entire short video playlist: "Introducing VERA The Engine Revolutionizing Apache Flink" available now on YouTube.
Modernizing Open Source Flink
Let’s take a step back to discuss the circumstances that inspired the development and creation of VERA in the first place. VERA was born out of the necessity to address existing key challenges in stream data processing, including challenges found in OS Apache Flink.
While Flink is considered the de facto gold standard streaming solution for good reason, it’s also had more than ten years of continuous development. The rise in Flink’s popularity and growth over time proves how beneficial and advantageous the technology is, but, like all software, it must continue to adapt to new pressures that evolve naturally over time.
Below are some of the challenges that VERA aims to address in OS Flink today, including:
- Historical single-tenant design and fragmented direction.
- High operational complexity and costs associated with building, running, and managing a deeply technical OS solution.
- Unfriendly “black box” behavior for developers, who would rather spend their time building applications that solve specific use cases.
- Architecture that has not changed or evolved to support today’s workloads, deployment methods, and storage models.
- Operational overhead and additional tech stack requirements to make OS Flink work in modern streaming data use cases, many of which demand both batch and real-time streaming capabilities.
- Inability to run natively in modern cloud environments.
Ververica's Solution
The VERA engine solves all of these key challenges, simultaneously modernizing and merging tried-and-true technologies, including:
- Keeping the best-in-class functionality of OS Flink, while also solving the expected limitations of a 10-year old technology.
- Creating a more developer-friendly experience.
- Reducing operational complexity and cost for users.
- Allowing Flink to run natively in modern cloud environments.
- Handling both batch and streaming use cases, including offering support for high-throughput, low-latency workloads, all without incurring additional significant cost.
VERA's innovative architecture and intelligent resource management provide a robust and scalable platform capable of handling high-throughput, low-latency workloads. Its adaptive capabilities ensure optimal performance under varying conditions, and its ease of use empowers developers to focus on building applications and solving complex streaming data use cases, rather than managing complicated infrastructure.
VERA redefines the possibilities for real-time stream processing by providing a modern cloud-native engine that is both powerful and user friendly. In addition, VERA ultimately democratizes stream processing and revolutionizes Apache Flink.
Check out Ben quickly explaining how VERA is revolutionizing Apache Flink in this 1 minute video:
Stay tuned for part two of this blog series introducing VERA, where we’ll dive into the technical components of the Three Core Pillars of VERA, and discover how VERA provides a one-stop shop for all your data streaming needs, whether you are processing, storing, moving, or using data.
Read the rest of the VERA: The Cloud Native Engine Revolutionizing Apache Flink® Blog Series:
- Part Two: Under the Hood: VERA’s Three Core Pillars
- Part Three: Full Stream Ahead: The Capabilities and Benefits of VERA
More Resources
- Learn about VERA.
- Watch more of the interview with Ben Gamble discussing VERA on YouTube.
- Access the VERA docs.
- Ready to get started? Take VERA for a test run by spinning up your own Ververica Cloud deployment.
- Have questions? Our team can help! Contact us.
- Join the Apache Flink Community at Flink Forward Berlin 2024, filled with Flink training courses, expert speakers, networking, an entire track dedicated to Flink use cases, and much more.
Thanks!
This blog series wouldn't be possible without the contributions of the many PMC Members, engineers, Ververicans and community members who’ve spent long days creating VERA, in addition to contributing to the Apache Flink project and repo, and supporting additional projects including Apache Paimon and Flink CDC.
In addition, special thanks to Dawn Leamon for her editing expertise and the video content (in addition to her many other talents).

You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
