














Introduction
Since its inception, Apache Flink has undergone significant evolution. Today, it not only serves as a unified engine for both batch and streaming data processing but also paves the way toward a new era of streaming data warehouses.
Apache Flink has the concept of Dynamic Tables, which bear resemblance to materialized views in databases. However, unlike materialized views, Dynamic Tables are not directly queryable. Recognizing the need to support querying of intermediate tables, progress towards streaming warehouses, and broaden the horizons for data teams, the community proposed FLIP-188: Introduce Built-in Dynamic Table Storage.
This initiative subsequently evolved into what is now known as Apache Paimon.
Why Apache Paimon?
The idea is simple yet powerful; Provide Apache Flink with a storage layer that leverages a table format, so intermediate data in dynamic tables is directly accessible. This storage design, known as the Lakehouse paradigm, is not new and is already established in the industry. It combines the flexibility and scalability of data lakes on cheap storage like S3 with the optimization and structured queries data warehouses offer. Technologies like Apache Iceberg, Delta Lake, and Apache Hudi already provide that.
So why create a new project from scratch? The vision was clear and a solution was needed that would be a good fit for high-speed data ingestion, fast analytical queries, strong upsert support, and a strong integration with Flink and Flink CDC. Flink needed to be a first-class citizen to unlock its full potential. The community evaluated solutions already established in the industry, like Apache Iceberg and Apache Hudi, but there were a few limitations in order for them to be used as the streaming storage layer for Flink. Going through the details is beyond the scope of this blog post. Still, with these challenges in mind, Flink Table Store was born under the Apache Flink project umbrella and later became its own project, entering the Apache Incubator as Apache Paimon.
If you look into the official documentation, you will see the following about Paimon.
A streaming data lake platform that supports:
- high-speed data ingestion
- change data tracking
- and efficient real-time analytics
Paimon offers the following core capabilities:
- Unified Batch & Streaming: Paimon supports batch read and writes, as well as streaming write changes and streaming read table changelogs.
- Data Lake: As a data lake storage, Paimon has the following advantages: low cost, high reliability, and scalable metadata.
- Merge Engines: Paimon supports rich Merge Engines. By default, the last entry of the primary key is reserved. You can also use the “partial-update” or “aggregation” engines.
- Changelog producer: Paimon supports rich Changelog producers, such as “lookup” and “full-compaction”. The correct changelog can simplify the construction of a streaming pipeline.
- Append Only Tables: Paimon supports Append Only tables, automatically compacts small files, and provides orderly stream reading. You can use this to replace message queues.
All these properties enable the Lakehouse to evolve with a streaming-first design, resulting in the Streamhouse.
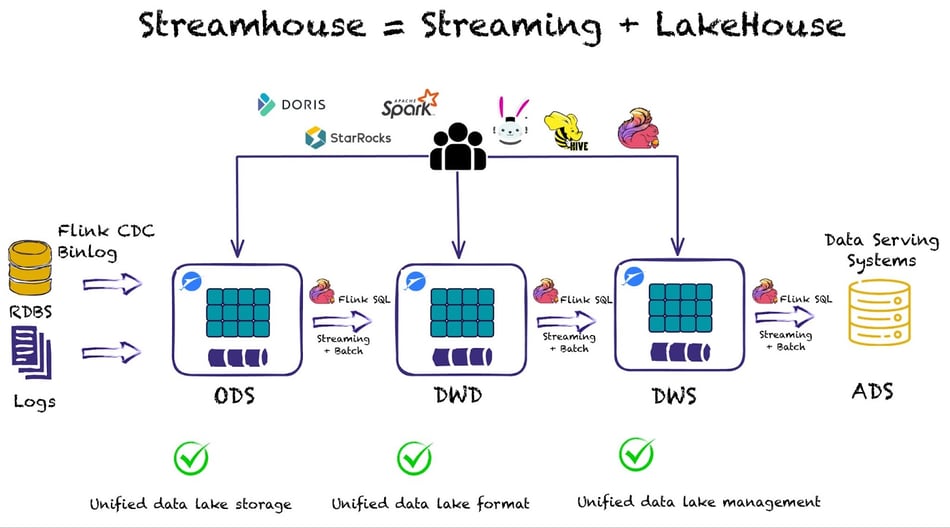
The Streamhouse architecture combines Apache Flink for Stream Processing and Apache Paimon as the streaming storage layer.
The core idea of the Streamhouse is streaming ETL and data ingestion from CDC or log data into cheap storage, like s3, in an easy and simple way using a one-line statement.
When data gets into the data lake users can create different jobs to create different business layers - i.e., ODS, DWD, DWS, and ADS - that take care of updates while data flows.
At the same time, you can add any query engine you want on top as the data is directly accessible - OLAP systems like Apache Doris and StarRocks or query engines like Flink SQL, Spark, Trino, or Hive - to run batch or incremental queries on snapshots of the Dynamic Tables.
Apache Paimon Features
Let’s take a closer look at some basic concepts to help us better understand what Apache Paimon offers.
Paimon Key Concepts
Snapshots
A snapshot captures the state of a table at some point in time. Users can access the latest data of a table through the latest snapshot and leverage time travel in order to access the previous state of a table through an earlier snapshot.
Partitions
Paimon adopts the same partitioning concept as Apache Hive to separate data.
Partitioning is an optional way of dividing a table into related parts based on the values of particular columns like date, city, and department. Each table can have one or more partition keys to identify a particular partition.
By partitioning, users can efficiently operate on a slice of records in the table.
Bucket
Unpartitioned tables, or partitions in partitioned tables, are subdivided into buckets to provide extra structure to the data for more efficient querying.
A bucket is the smallest storage unit for reads and writes, so the number of buckets sets the maximum processing parallelism.
Consistency Guarantees
Paimon writers use the two-phase commit protocol to commit a batch of records to the table atomically. Each commit produces, at most, two snapshots at commit time.
For any two writers modifying a table at the same time, as long as they do not modify the same bucket, their commits can occur in parallel. If they modify the same bucket, only snapshot isolation is guaranteed. The final table state may be a mix of the two commits, but no changes are lost.
Paimon uses snapshots to provide access to different versions of any table, and groups data files into partitions and buckets, with consistency guarantees.
It leverages an LSM (Log-Structured Merge Tree) data structure to achieve performance for streaming data. Each bucket basically contains an LSM tree and its changelog files.
The following figure shows the file layout of Paimon and how everything fits together.
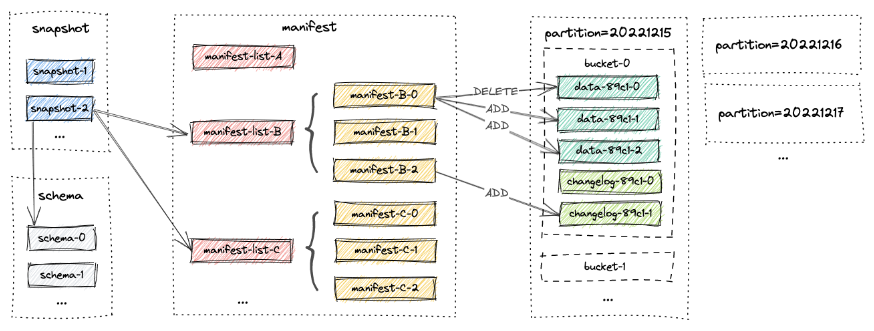
Paimon Table Types
Primary Key Tables
This is basically a changelog table and is the default. Users can insert, update, or delete records in the table.
Primary keys consist of a set of columns that contain unique values for each record. Paimon enforces data ordering by sorting the primary key within each bucket, allowing users to achieve high performance by applying filtering conditions on the primary key.
Since this table is used to store changelog streams, Paimon offers a variety of merge engines when two or more records with the same primary key arrive.
Changelog Producers, also play an important role here, but we will discuss them in detail in a future blog post.
Append-Only Tables
An append-only table is a table without a primary key. This table allows only insert operations. Delete or update operations are not supported. This type of table is suitable for use cases that do not require updates, such as log data synchronization.
External Log Systems
Along with the aforementioned table types, Paimon also supports external log systems. When using external log systems and writing the data on the data lake, the data will also be written to a system like Kafka. If using an external log system, table files and the log system record all writes, but the changes produced by the streaming queries will come from the log system instead of the table files.
Data Lake Ingestion
With some core concepts in place, let’s switch gears and see the core functionality of Apache Paimon.
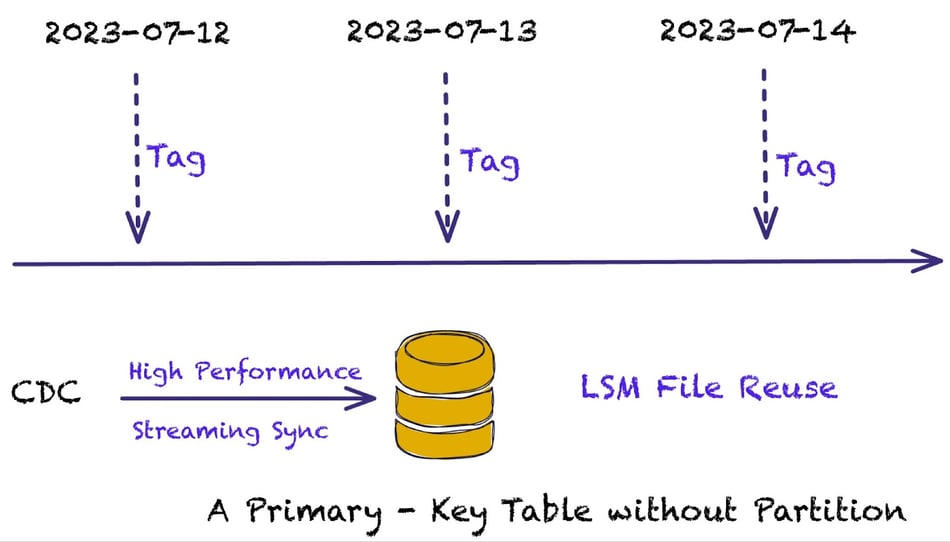
As already mentioned, Paimon writes data in the data lake by leveraging partitions and buckets, where each bucket contains an LSM tree. When data is written, it allows the creation of tags (which we will explain in more detail shortly) and the LSM layered structure allows for file reuse to optimize performance and reduce the creation of many files. Compared to other architectures, it doesn’t require defining a partitioned table, it only requires a primary key.
The tables can be streamed in real-time with low latency and allow real-time queries, batch queries, and incremental queries. There is lots of flexibility in parameter tuning for data lake ingestion, allowing users to balance between write performance, query performance, and storage amplification.
For example, when users know the job is under pressure, they can choose Paimon's dynamic bucket mode or set a suitable bucket size. If the backpressure continues, they can adjust the Checkpoint Interval, or tune the Paimon compaction parameters so doesn’t block, and ensure better write performance.
Overall, Paimon is highly configurable, allowing users to make tradeoffs according to streaming reads, batch reads, and update scenarios.
Tags and Time Travel
Apache Paimon leverages the concept of Tags in order to allow access to different offline views. An offline view is basically a snapshot of the table at some point in time that allows historical data queries. Tags allow users to time travel to previous versions of the table in time.
Tags can be created and expired automatically and they are based on snapshots. The tag will maintain the manifests and data files of the snapshot.
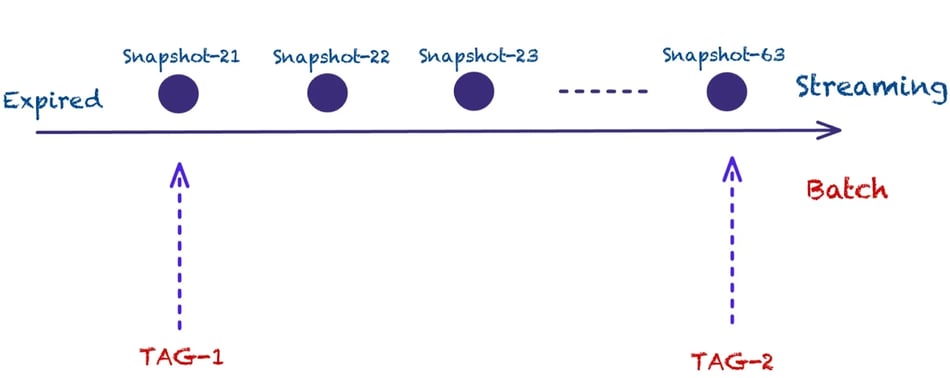
The following code snippet demonstrates that when creating a table, users can specify automatically created tags, for example, per day.
CREATE TABLE MyTable (
id INT PRIMARY KEY NOT ENFORCED,
...
) WITH (
'tag.automatic-creation' = 'processing-time',
'tag.creation-period' = 'daily',
'tag.creation-delay' = '10 m',
'tag.num-retained-max' = '90'
);
INSERT INTO MyTable SELECT * FROM kafkaTable;
-- Read latest snapshot
SELECT * FROM MyTable;
-- Read Tag snapshot
SELECT * FROM MyTable VERSION AS OF '2023-07-26';
-- Read Incremental data between Tags
SELECT * FROM MyTable paimon_incremental_query ('2023-07-25', '2023-07-26');
When these tags are created on snapshots, they remain until the expiration policy takes effect (if specified).
While present, users have the ability to run queries on streaming data, on historic data by specifying previous snapshots, and also incremental changes between different snapshots.
Change Data Capture
One of the most essential aspects of Apache Paimon is data lake ingestion through Change Data Capture. Paimon integrates with Flink CDC, which is an open-source CDC technology that supports a large variety of data sources.
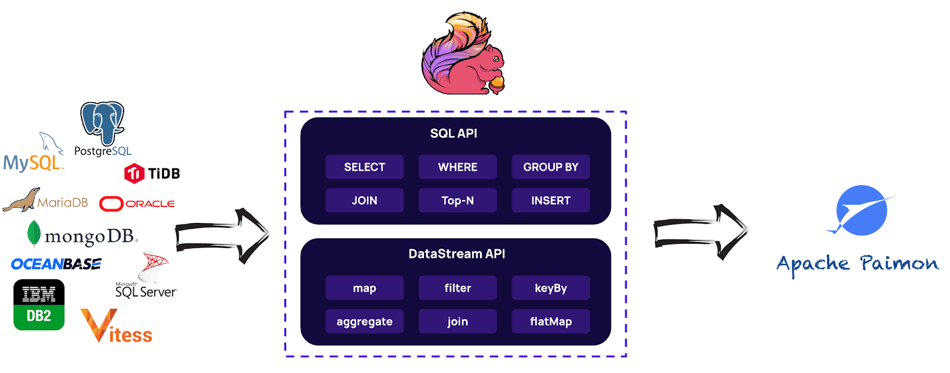
When dealing with change data capture technologies, it’s hard to read large tables with historical data and start reading the incremental data afterward.
At the same time, we need a way to read large tables incrementally and, when the database contains hundreds or thousands of tables, minimize the open connections to the database and not put too much pressure on the system.
Flink CDC can achieve this by leveraging an Incremental Snapshot Algorithm that is unique to the project.
The Incremental Snapshot Algorithm sits at the heart of Flink CDC.
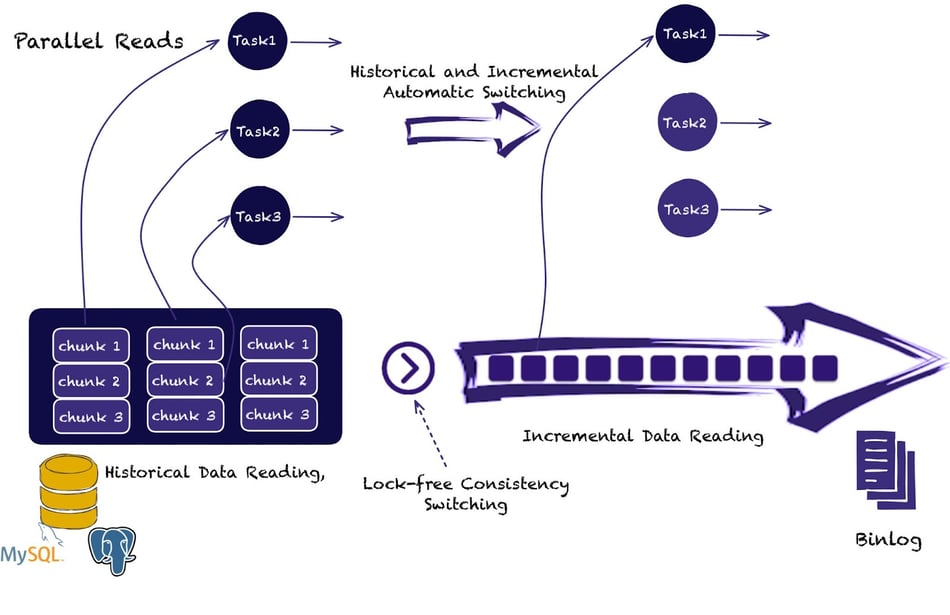
It reads the historical data, and then, automatically without locking the database, continues to read the incremental changes from the Binlog. As depicted in the illustration, the Incremental Snapshot Algorithm allows splitting large tables into smaller chunks and read them in parallel. When the automatic switching occurs, only one task is required in order to read the incremental changes.
Currently, Paimon is in the 0.5 release and supports CDC with MySQL and MongoDB, with more databases (like Postgres) to be supported soon.
Kafka CDC is also supported and if the users need to integrate with other CDC source systems they can leverage the RichCdcRecord.
LSM and Hierarchical File Reuse
Next, we will take a look at the multiplexing of Paimon LSM file storage.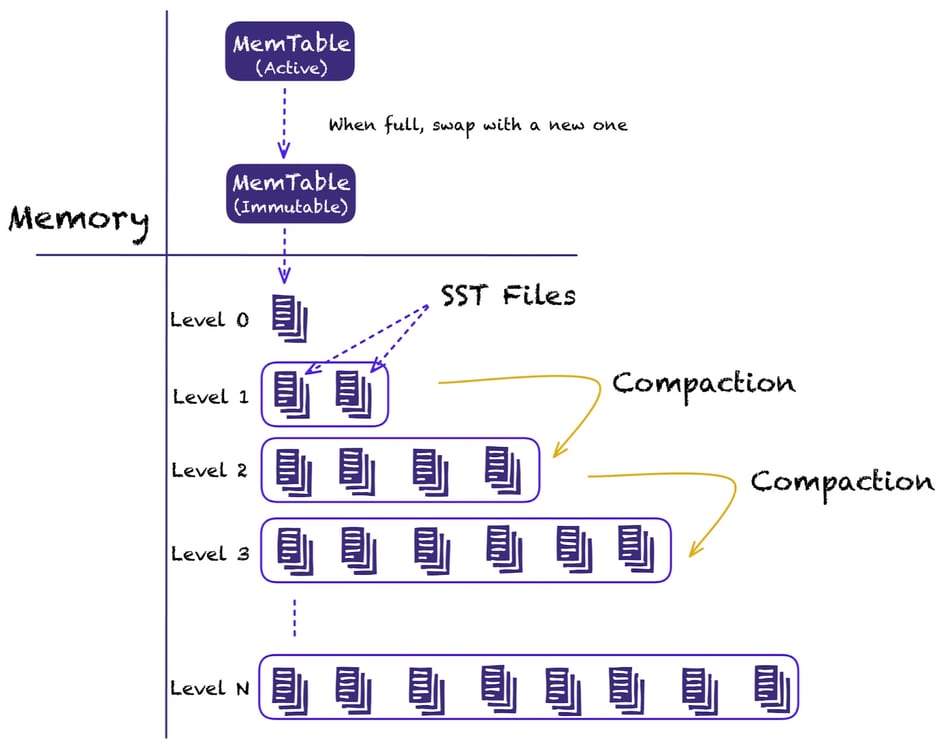
Paimon leverages LSM (Log Structured Merge trees) for file storage and uses leveled compaction similar to RocksDB. One feature of the LSM data structure is that when incremental data arrives, it does not necessarily need to be merged into the lower levels.
This allows lower-level files to be reused between two tags as they don’t always get affected by compaction.
Stream Processing Use Cases
Streaming Joins
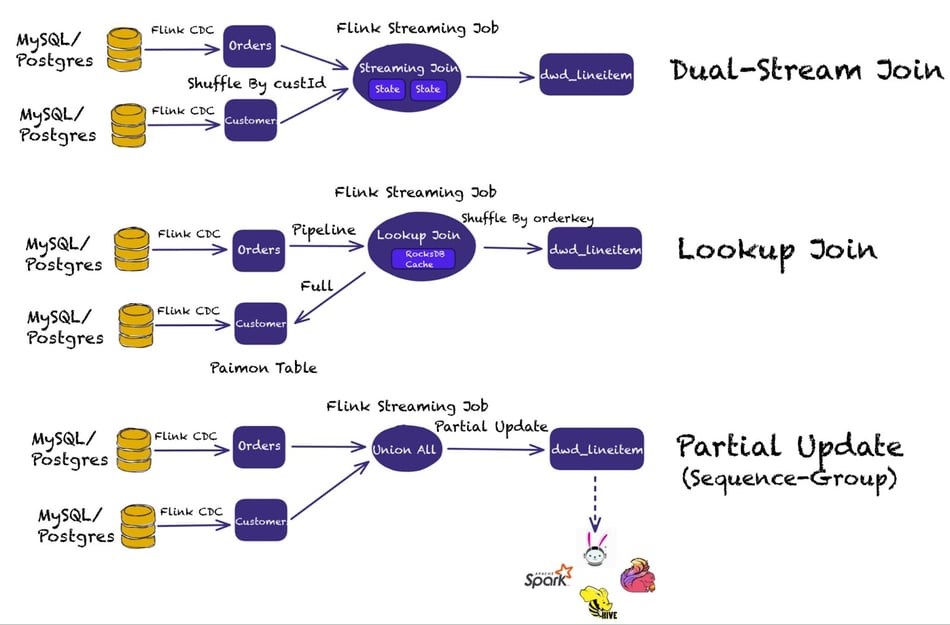
Table data widening (for use cases like data enrichment) is quite common in streaming ETL. Paimon supports Dual-Stream Joins (or regular joins), Lookup Joins, and Partial Update (leveraging Sequence-Groups).
Dual-stream joins require both sides of the streaming join query to be kept in memory. As the state grows too large, the cost of running joins increases as well. Paimon allows querying data directly from the data lake storage.
Lookup Join allows performing the lookup of Paimon tables through the Flink Lookup Join. One thing to keep in mind with the Lookup Join is that when the dimension table is updated, changes are not reflected downstream.
Partial Update is a method for updating the same component. It uses Sequence-Groups, which enables each field to use a different update method, and it also supports various merge engines. It provides high throughput and near-real-time level latency.
For example, suppose Paimon receives three records:
- <1, 23.0, 10, NULL>
- <1, NULL, NULL, 'This is a book'>
- <1, 25.2, NULL, NULL>
Assuming that the first column is the primary key, the final result would be:
<1, 25.2, 10, 'This is a book'>
In addition to the above, Paimon does a lot of work to provide users with the ability to operate on foreign keys in the future, which should help address even more use cases efficiently.
Paimon as a Message Queue
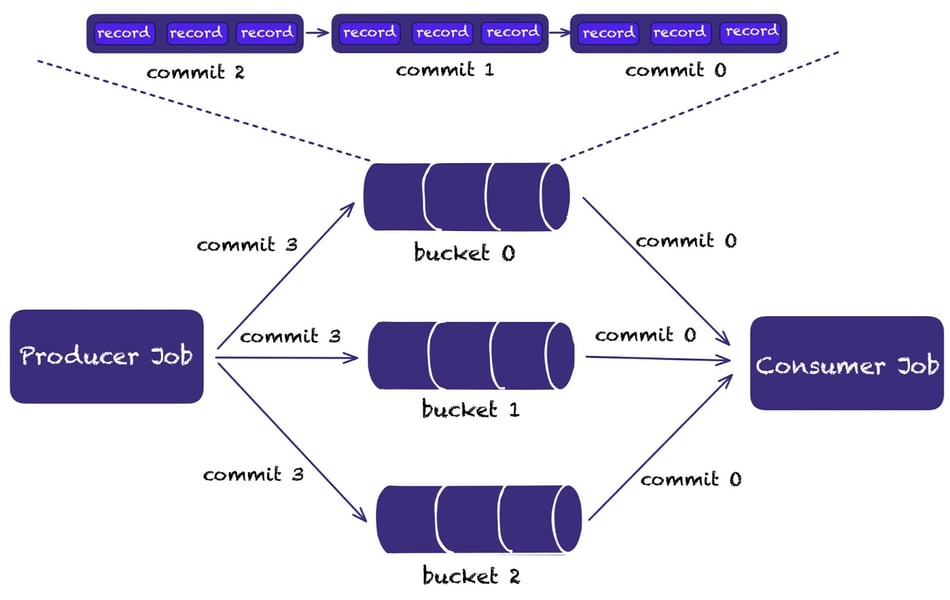
Since Paimon is oriented towards real-time processing, some people will inevitably compare Paimon and Kafka architectures, as Paimon has done a lot of work here.
For example, it supports Append-only tables, which allows creating a table without a primary key, only specifying the bucket number.
Buckets are similar to partitions in Kafka. They provide strict order preservation, which is the same as Kafka's message ordering, but they also support Watermarks and Watermark alignment. At the same time, there is also support for Consumer IDs.
During the writing process, small files can be automatically merged.
Therefore, it can be seen from the illustration above that its overall architecture, allows users to replace Kafka with Paimon for certain use cases.
Kafka's real ability is to provide latency on the order of seconds. When the business use cases don’t require second-level latency, you can consider using Paimon to achieve message-queue functionality.
Apache Paimon typically operates on minute-level latency, as writing to the data lake depends on the checkpoint interval. The recommended checkpoint interval is typically one minute in order to avoid generating many small files that affect the read query performance.
If you don’t care about read performance you can consider setting lower-level checkpoint intervals, by also leveraging newer Flink versions that support new features like the changelog state backend.
Summary
Apache Flink evolved to be more than compute, and Apache Paimon was born to act as the storage layer. Even though in it’s early days the project has seen lots of adoption and is already used in production in large-scale companies.
The community embraces the “Streamhouse” and you can keep an eye on the Paimon roadmap and PIPs.
References
More Than Computing: A New Era Led by the Warehouse Architecture of Apache Flink
Generic Log-based Incremental Checkpoint --- Performance Evaluation & Analytics

You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
