














A Glimpse Into the House of Streams
In addition to being the heart of Ververica’s Streaming Data Platform, Apache Flink® has been the de facto gold standard for stream processing. Throughout the years, Ververica’s Streaming Data Platform has been deployed in production workloads with impressive scalability, including sustaining processing peaks of up to 7 billion events per second. The need to provide this kind of scalability means we continuously push to make our solutions more performant and cost-efficient.
In the evolving landscape of data infrastructure, businesses are continuously striving to process and analyze vast amounts of data in real time while also retaining the ability to perform deep analytical queries on historical data. Traditionally, organizations have relied on separate architectures for batch and stream processing—batch systems to handle large-scale, offline data analysis, and streaming systems to process real-time data as it flows in. This separation often leads to complex, siloed architectures that are expensive to maintain and difficult to scale.
In this article, we will explore the need for a unified solution that not only delivers the flexibility of stream processing but also brings the robustness of batch analytics into one framework and how Ververica provides such a solution, which is ideal for organizations looking to build a modern, real-time analytical infrastructure.
Current Status Quo of the Data Landscape
In today's rapidly evolving data landscape, two dominant paradigms shape the way organizations process and analyze data: real-time streaming architectures and data lakehouses. Both of these models offer unique advantages, but they also come with inherent trade-offs, leaving many organizations searching for an ideal middle ground.
Real-Time Streaming
Real-time streaming architectures have transformed how businesses handle data by enabling the processing of events as they happen. This real-time approach is crucial for use cases such as fraud detection, pairing an AI chatbot, recommendation engines, online gaming, financial market updates, IoT devices, and monitoring, where low-latency insights are essential. However, the infrastructure required to support real-time systems can be expensive to maintain. The cost of ensuring fault tolerance, processing speed, and data consistency in high-throughput environments is significant, particularly when scaling to accommodate growing data volumes.
Such architectures are often built with Apache Flink and streaming storage layers like Apache Kafka. Streaming storage layers write, read, and store data at high speeds, making them an ideal combo for moving data in real-time (within seconds). However, despite their strength with low-latency streaming, this approach comes with a few drawbacks, including:
- Data is not directly queryable on these streaming storage layers and data reprocessing needs to replay a lot of data.
- These solutions require significant engineering knowledge, and are harder to learn and use for data professionals who might not be familiar with these systems.
- It’s difficult to find data errors and apply corrections.
- Real-time streaming solutions often come with high operational costs, as they require keeping data for longer durations, which can yield unnecessary networking and storage costs.
The Data Lakehouse
On the other hand, the data lakehouse has emerged as a popular solution for handling batch processing and long-term data storage. Compared to the early data warehouses (like Hive), Lakehouse architecture is more than a simple batch solution that requires hour-to-day data delays. Instead, by combining the flexibility of data lakes with the reliability and performance of traditional data warehouses, lakehouses provide a cost-effective solution for managing and analyzing historical data. Their architecture is optimized for large-scale batch processing, which allows for efficient querying of historical data, but they fall short when it comes to delivering real-time insights. As a result, they are often not suited for applications requiring immediate decision-making based on live data streams.
Many users try to leverage Apache Flink in conjunction with a table format. At first, commodity storage was the solution of choice, but has been quickly supplanted by much cheaper cloud alternatives that offer high performance resilient data stores in order to offload data and create a Lakehouse. Compared with a real-time streaming solution, accessing cheap object storage when using a Lakehouse makes that data easily accessible for data professionals via various query engines. This approach also allows for better data transparency, creating a single “source of truth” for your data on the lake and allowing for integration with any query engine.
This creates a gap between the two paradigms. Real-time streaming offers immediate insights but is expensive and resource-intensive to maintain at scale. Data lakehouses provide a more economical approach but are focused on batch processing, limiting their ability to offer up-to-the-minute insights. For many organizations, this trade-off between cost and real-time capabilities presents a significant challenge, as neither solution fully addresses the need for both real-time and historical analysis in an integrated, efficient manner.
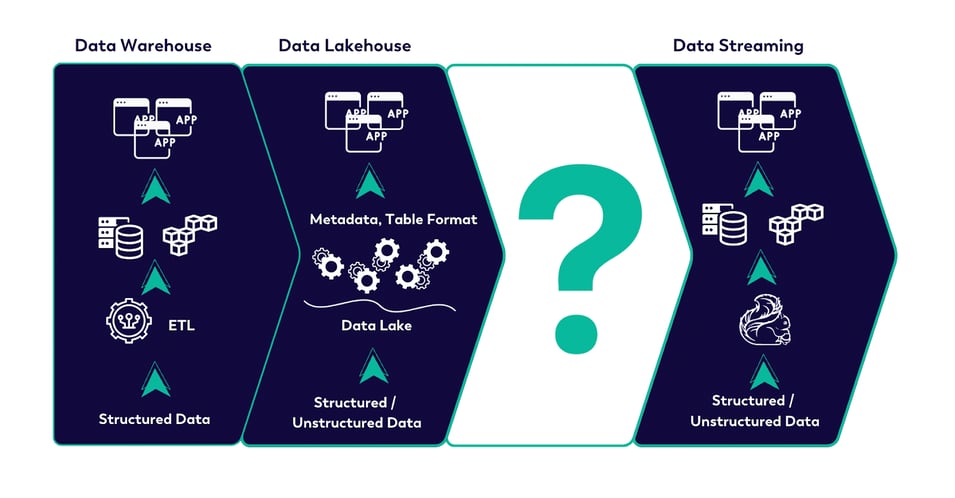
FIGURE 1: THE GAP BETWEEN DATA LAKEHOUSE AND DATA STREAMING SOLUTIONS
The lack of an intermediate solution has left businesses juggling complex, siloed systems to balance these needs. What is required is a solution that seamlessly unifies real-time and batch processing without compromising on performance or cost—allowing organizations to achieve real-time insights while also benefiting from cost-effective storage and long-term data analysis.
Enter Ververica's Streamhouse
While enterprises today widely adopt Lakehouse capabilities, the increasing demand for real-time data processing and up-to-date data (data freshness) conflicts with the limitations of traditional Lakehouses. This increasing need for a solution that provides fast, fresh data, while remaining cost-effective and easy for engineers to implement, is likely driven by several factors, including:
- The recent explosion of machine learning (ML) and artificial intelligence (AI) workloads
- Increasingly strict requirements that demand high-throughput data ingestion
- Use cases that depend on low-latency data processing
- The need for high-performance, real-time queries
- The requirement for mutable data processing
Such requirements can be classified as a Streaming Lakehouse, which is more than just streaming ingestion.
Enter Ververica’s Streamhouse, a groundbreaking approach that unifies batch and stream processing into a single, cohesive solution. Built on the powerful Apache Flink engine, Streamhouse bridges the gap between real-time data processing and historical batch analytics. It offers a seamless way to ingest, process, and analyze both streams of real-time data and large datasets with low latency, providing businesses with a holistic, unified analytical platform. By simplifying the architecture and eliminating the need for separate systems, Streamhouse enables organizations to derive insights faster and more cost-effectively, paving the way for a more integrated, scalable, and efficient data-driven future.
With Streamhouse, organizations can now achieve real-time insights and long-term analytical capabilities in one cohesive platform, powered by Apache Flink’s robust, scalable engine. This convergence reduces operational complexity, cuts down infrastructure costs, and empowers businesses to harness the full potential of their data—whether it’s streaming in real time or being queried from a vast historical dataset. As data continues to play an increasingly critical role in decision-making, Ververica’s Streamhouse represents a critical step forward in modern data architecture, offering a flexible, scalable, and integrated approach for organizations seeking to remain competitive in a data-driven world.
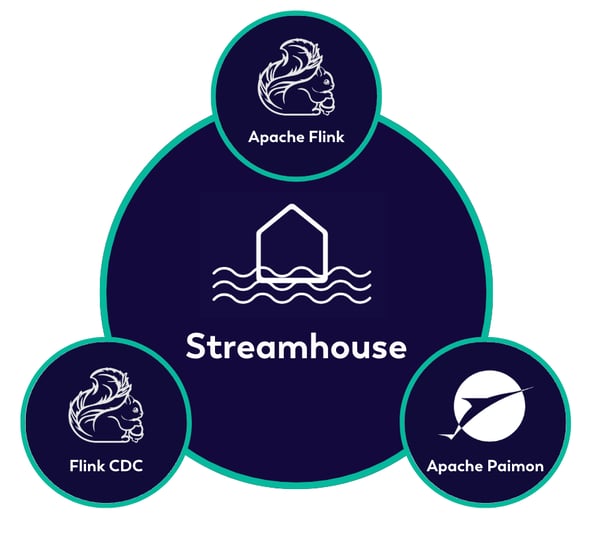
FIGURE 2: THE THREE MUSKETEERS OF THE STREAMHOUSE
Streamhouse is powered by three open-source projects:
- Apache Flink CDC handles Change Data Capture streaming data ingestion.
- Apache Flink offers unified batch and stream processing.
- Apache Paimon provides unified Lakehouse storage for batch, OLAP, and streaming queries.
There are plenty of resources and blogs available for you to explore the capabilities of Apache Flink and Flink CDC, as they are quite popular in modern large-scale production environments. Apache Paimon, however, is a newer addition to the tech stack, functioning as a table format that brings real-time streaming capabilities to the Lakehouse.
While a data Lakehouse is a combination of the best a data lake and a data warehouse have to offer, the Streamhouse is a continued evolution of the Lakehouse, with well-established Apache Flink sitting at its core.
Streamhouse = Streaming + Lakehouse
Essentially, Streamhouse = Streaming + Lakehouse and as discussed it combines the ease and cost of the Lakehouse with the power of real-time streaming to merge the best of both, allowing you to leverage the benefits of the Lakehouse and real-time streaming in one solution.
Unified Batch and Streaming
You may have noticed the term 'unified' used for the trio of projects (Apache Flink, Apache Paimon, and Flink CDC) that work together. While Apache Flink is known for its streaming and batch processing capabilities, in the Streamhouse context, "unified" means that the underlying engine has all the technology required to support both batch and streaming workloads.
As depicted in the illustration below, we can think of batch as a specialized type of stream.
Note: OLAP is also a specialized type of Batch.
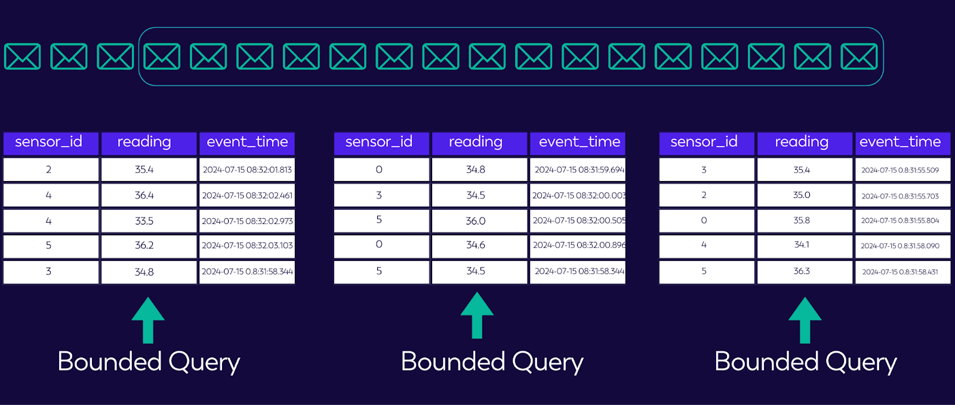
FIGURE 3: BATCH AS A SPECIALIZED STREAM
A stream is an unbounded collection of events, but at any point in time that stream can be broken down into discrete views and then queried, yielding results up to that precise point in time. This highlights that Streamhouse is a one-stop solution that can handle batch and streaming workloads. Overall, the Streamhouse provides a solution boasting three lows (3Ls): low latency, low complexity, and low cost.
Next, let’s explore the three musketeers of the Streamhouse (Apache Flink, Flink CDC, and Paimon).
Apache Flink: Unified Compute
Apache Flink provides capabilities that solve both batch and stream processing use cases. Since its original inception, Flink has evolved significantly and one of its core distinguishing features is a unified batch and streaming API. This API allows users to connect a streaming storage layer and perform queries on both batch and streaming data, as Flink itself does not include a storage layer.
As mentioned, the unified batch and streaming API is a conceptual advantage. Although batch and stream share similarities, they have distinct needs and requirements. An effective engine must support both, and seamlessly switch between the two.
Figure 4 depicts some of the different properties of streaming and batch processing.

FIGURE 4 : STREAMING AND BATCH PROPERTIES
Additionally, to move the Apache Flink project towards a Streaming Lakehouse, is the result of significant effort. It introduces and supports more Lakehouse APIs, including extended DDL (Data Definition Language) support and time travel features.
Apache Flink CDC: Unified Ingestion
With Apache Flink as the engine, the first step is getting data into the lake. Naturally, the next question is, why would you ingest operational data in a data lake in the first place? Business application data is typically stored in operational databases like MySQL or Postgres. Generally speaking, when there is a need to perform data analysis you typically want to avoid querying the database directly. There are two primary reasons for this:
- Querying large tables may cause excessive database load, which can affect business operational workloads negatively. As a result, data scientists and analysts need to have a good understanding of the anticipated data volumes and how their queries will affect the underlying system.
- The query performance might need improvements, as data is not stored in columns.
As discussed above, streaming and real-time data can be moved into a streaming storage layer like Apache Kafka or Apache Pulsar, although each of these solutions may, in turn, have their own limitations based on the scenario.
The above examples help to better understand why it is necessary to synchronize the data on a data lake or data lakehouse for analytical use cases, and a crucial aspect of that is Change Data Capture (CDC) ingestion.
Important Considerations for CDC Ingestion
The Streamhouse aims to provide a seamless CDC ingestion experience. If you are working in large-scale production environments there is a good chance that you have a considerable number of tables within a database, and those tables can undergo numerous schema changes as the business evolves. In addition, new tables might be added to the database as the business grows. Typical user challenges include:
- How to map all of the tables' DDL (Data Definition Language) to Flink DDL?
- How to easily synchronize the full database with all the tables?
- How to make sure all the schema changes are reflected downstream?
- How to deal with scenarios where new tables are added to the database over time?
- How to read all the historical data and then know how to start reading the new changes from the database?
At the same time, the underlying framework should not put too much pressure on the database when doing large-scale CDC ingestion to keep DBAs (Database Administrators) satisfied.
Streamhouse Ingestion for CDC Data
To eliminate the above concerns and allow users to focus on creating data products, Ververica’s Streamhouse provides convenient syntactic sugar via SQL.
More specifically, there are: CREATE TABLE AS (CTAS) and CREATE DATABASE AS (CDAS) statements.
CTAS allows users to move data in real time between upstream and downstream systems, while also handling and synchronizing all the schema changes.
CDAS is a syntax sugar for CTAS that provides access to all the database metadata, allowing multi-table or even full database synchronization.
In addition, source merge optimization is supported. This is particularly applicable to MySQL CDC because it not only reduces the number of database connections, but also avoids repeated pulling of Binlog data to reduce the database reading pressure.
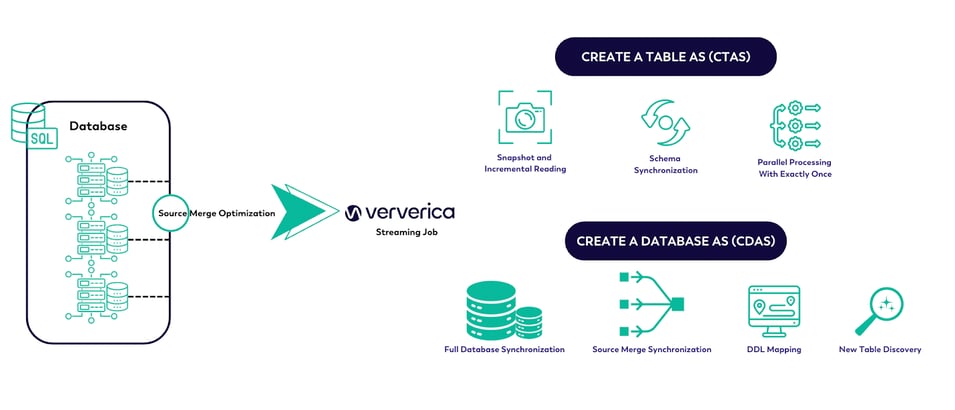
FIGURE 5: DATABASE SYNCHRONIZATION
Now, let’s use an example to demonstrate the simplicity of this process. Imagine there is a large database with multiple tables of sales data that need to be synchronized. In addition, you are required to sync all the schema changes that take place within the database, along with any new tables that are added. Since this impacts CDC (mutable/updates) data, these changes need to be reflected in the ingestion layer tables.
This can all be achieved by leveraging the built-in catalogs and the CDAS SQL abstraction. The following code snippet demonstrates how you can achieve all the requirements listed in the example above with a singular SQL statement.
SET 'table.exec.sink.upsert-materialize' = 'NONE';
SET 'table.cdas.scan.newly-added-table.enabled' = 'true';
CREATE DATABASE IF NOT EXISTS `paimon-catalog`.rds_dw
WITH (
'changelog-producer' = 'input'
) AS DATABASE rdsdb.sales_db INCLUDING ALL tables;
Apache Paimon: Unified Lakehouse Storage
As mentioned previously, Apache Paimon is a fairly new addition to the ecosystem. Paimon is a unified lakehouse storage that relies on a single table abstraction that can handle different use cases, including message queue functionality, range scan queries, and key/value lookups. On the API, a single interface needs to be provided. With Paimon, a single SQL query can operate on batch, OLAP, and streaming data, without any code changes.

FIGURE 6: APACHE PAIMON, UNIFIED LAKEHOUSE STORAGE
Apache Paimon builds on Lakehouse primitives and provides all the required properties, including ACID guarantees, efficient querying, time travel, schema evolution and more. Paimon also takes it one step further, with the ability to bring all the required streaming capabilities onto the lake.
Unified Lakehouse Storage: Features of Apache Paimon
Apache Paimon is built to work seamlessly with Apache Flink, and helps to unlock the full potential of Flink on the Lakehouse.
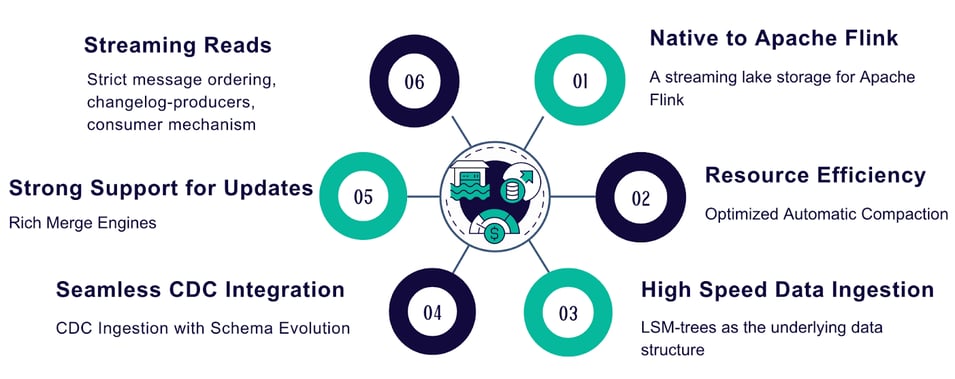
FIGURE 7: PILLARS OF A UNIFIED LAKEHOUSE STORAGE UTILIZING APACHE PAIMON
Let's take a closer look at six key areas that make this possible:
1. Strong Native Flink Integration: Paimon works well with Apache Flink, supporting all the latest versions and features.
2. Resource Efficient Automatic Data Compaction: To best balance read and write speeds, Paimon automatically combines smaller files into larger ones, making data queries faster. It does this via an internal process called compaction. Compaction handles small files by merging them automatically and asynchronously into larger files, resulting in faster querying and performance optimizations.
3. High-Speed Data Ingestion: Paimon uses Log-Structured Merge (LSM) trees, a popular data structure for fast data writing, used by systems like RocksDB, ScyllaDB, Clickhouse, and Cassandra to name a few. Paimon does this efficiently by utilizing low-cost object storage.
4. Seamless CDC Ingestion: Paimon integrates seamlessly with Flink CDC, leveraging the sophisticated features of the framework to handle data changes smoothly and updates effectively, which is crucial for Change Data Capture.
5. Robust Upsert Support: Paimon leverages merge engines to handle updates on the Lakehouse, supporting various methods like deduplication, first-row, aggregation, and partial updates. One of its key strengths is the partial update merge engine, which allows merging multiple streams together, eliminating the need for costly streaming joins on the primary keys. The partial-update can also be combined with the aggregation engine. All merge engines store the state directly on object storage, making streaming ETL more cost-effective.
6. True Streaming Reads: Streaming writers can generate a changelog, similar to a database binlog, which keeps track of all the changes that occur on a table. This is important for the downstream consumers to be able to always see correct results. At the same time table formats have a snapshot management mechanism, which means at any point in time, various data files can expire and be deleted, resulting in FileNotFoundExceptions for consumers. Apache Paimon provides different safeguard mechanisms, along with a consumer-id mechanism, allowing for true streaming reads.
When Should You Consider Adopting Streamhouse?
Vererica’s Streamhouse helps fill the gap between traditional streaming and batch architectures. If you are already invested in or considering Apache Flink and its ecosystem and you want to fully leverage a lakehouse, then adopting this unified solution yields several business benefits. Below, we’ve listed a few use cases highlighting when Streamhouse is worth exploring:
- Data lake entry: If the business has strong requirements for CDC data ingestion.
- Near-real-time: If your real-time SLAs can afford 1-minute latencies, Streamhouse can provide lower operational costs than traditional stream processing.
- Data freshness: When there is a requirement to provide fresh data on your Lakehouse (1-minute interval) Streamhouse can help provide up-to-date data seamlessly.
- Fast writes and Blazing fast OLAP: When there is a requirement for fast writes and blazing fast OLAP queries.
- Streaming Materialized Views: When there is a requirement for streaming materialized views and incremental updates, to avoid recalculating predefined queries.
- Connecting upstream and downstream tables: Anytime there is a need to connect upstream and downstream tables via streaming, you can utilize the Streamhouse. This singular solution includes using an ingestion layer as the source of truth, a processing layer that contains tables for streaming deduplication, multi-stream merging, lookup joins, and aggregations with business aggregates and KPIs, all ready to be served.
- Testing: If your existing data infrastructure is oriented towards batch, and there is a need to introduce streaming, Streamhouse allows you to easily experiment with streaming use cases before making permanent, significant investments.
All the above are a small sampling of business scenarios that can leverage Ververica’s Streamhouse. In addition, Streamhouse makes streaming data accessible to more data professionals, allowing them to leverage and experiment with fresh data for ML and AI applications. The image below represents the single-solution offered by Streamhouse, including ease of use for professionals and a sampling of the many use cases it helps to solve.
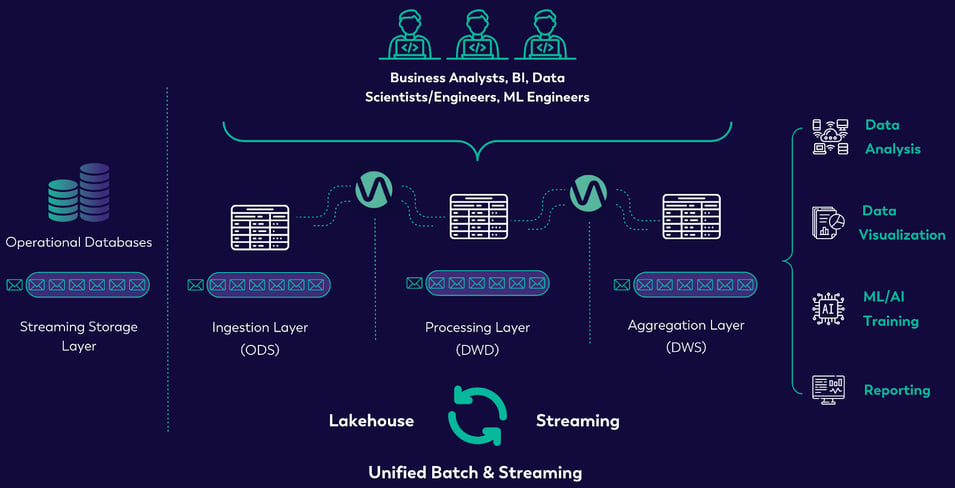
FIGURE 8: UNIFIED BATCH AND STREAMING
Conclusion
Ververica’s Streamhouse offers a transformative solution in today’s data-driven landscape, addressing the critical need for a unified batch and streaming architecture. By seamlessly converging real-time streaming with data lakehouse capabilities, Streamhouse offers businesses the flexibility to process data in real time while also benefiting from the cost-effectiveness and scalability of batch processing. This powerful combination eliminates the need for maintaining complex, separate systems, reducing both operational costs and inefficiencies.
With Streamhouse, organizations can harness the full spectrum of their data—whether streaming for faster insights or leveraging historical datasets for deep analytical purposes—all within a cohesive platform. This approach redefines what’s possible with modern data architectures, enabling businesses to stay agile, scale effortlessly, and derive value from their data faster and more efficiently than ever before. As the demand for real-time insights continues to grow, solutions like Streamhouse are paving the way for a more unified, efficient, and intelligent approach to data processing.
More Resources
Note: In data architectures, there is no one-size-fits-all solution, which is why the community requires transparency, and why integrations are often an important part of any solution.
- Read more about Streamhouse:
- Watch more of the interview with Ben Gamble discussing VERA and Streamhouse on YouTube.
- Access the VERA docs.
- Ready to get started? Take VERA (with Streamhouse) for a test run by spinning up your own Ververica Cloud deployment.
- Have questions? Our team can help! Contact us.
- Join the Apache Flink Community at Flink Forward, filled with Flink training courses, expert speakers, networking, an entire track dedicated to Flink use cases, and much more.
Thanks!
This blog wouldn't be possible without the contributions of the many PMC Members, engineers, Ververicans and community members who contribute to the Apache Flink project and repo, and those who support the Apache Paimon and Flink CDC projects.

You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
