













The demand for real-time insights has transformed how businesses approach data architectures. Over the last decade, the Kappa Architecture has evolved significantly to address modern scalability, efficiency, and real-time analytics requirements. However, while Kappa may be able to streamline handling event-driven applications and continuous data streams, it also has inherent limitations, including the inability to integrate historical data processing.
The next evolution to emerge is the data Lakehouse, which offers structured and transactional data processing in addition to the flexibility of traditional Data Lakes. However, as real-time data demands continue to grow, efforts to extend Lakehouse capabilities into streaming-first scenarios raise additional concerns, including gaps in latency, efficiency, and the seamless integration of both.
Ververica’s Streamhouse is the newest concept that combines the real-time, low-latency capabilities of streaming systems with Lakehouse's robust analytics and flexibility. Helping to drive this shift are technologies like Apache Paimon and Fluss, which integrate perfectly with Apache Flink® and Flink CDC, enabling businesses to unify real-time and historical data processing in a single, efficient solution.
In this post, we’ll discuss the evolution from Kappa to Lakehouse and the emergence of Streamhouse, exploring how they help address modern data challenges and how Streamhouse unlocks the potential of unified batch and stream processing systems.
The Starting Point
Several innovative data architectures have been introduced over time. In this section, we’ll focus on Lambda and Kappa.
Lambda Architecture
Emerging in the early 2010s, the Lambda architecture addresses several big data processing challenges. Lambda features a dual-layer design:
- Batch Layer: Processes large historical datasets accurately using tools like Apache Hadoop®.
- Speed Layer: Focuses on low-latency, real-time data processing with systems like Apache Flink or Spark Structured Streaming.
While Lambda was an effective solution at the time of its invention, this approach has significant drawbacks, including:
- Complexity: Maintaining separate codebases for batch and streaming layers increases development and operational overhead.
- High Latency: The reliance on the batch layer for completeness delays the integration of historical data with real-time results.
- Resource Intensive: Operational inefficiencies make scaling difficult.
Kappa Architecture
In response to these drawbacks, the Kappa Architecture appeared in 2014 as an alternative that emphasizes real-time streaming over batch processing (ie: it adopts a streaming-first strategy). Kappa simplifies data architectures by eliminating the batch layer, using a single immutable log as the source of truth, and is often implemented with Apache Kafka® for storage and Apache Flink for real-time processing. This design offers several advantages:
- Simplicity: No duplicate codebases are needed for batch and streaming processing.
- Low Latency: Optimizes real-time stream processing, and is ideal for event-driven applications.
- Scalability: Enables replaying streams for debugging and reprocessing.
Despite these benefits, Kappa also faces limitations as data processing demands continue to grow, including:
- Limited Batch Integration: Kappa struggles to handle hybrid use cases that require batch processing.
- Costly Reprocessing: Replaying entire streams to manage historical data is very resource-intensive.
- Challenging Analytics: Log-based streaming systems lack support and optimization for ad hoc queries and complex analytical workloads. This requires integrating external systems to offload and inspect real-time data, which are often more batch-oriented and can’t cope with the demand of real-time data analysis.
Figure 1 depicts a streaming-first Kappa Architecture. Note that intermediate results are written into Kafka topics, but those results can’t be reused or queried, only consumed.

Figure 1: Streaming-First Kappa Architecture
The Rise of the Lakehouse
The Lakehouse concept, introduced circa 2017, combines the scalability of Data Lakes with the transactional guarantees of data warehouses. Technologies like Apache Iceberg™, Delta Lake, and Apache Hudi™ help to bring order and structure to Data Lakes, making it easier to organize, manage, and query data. These table formats address long-standing challenges such as consistency, transactional integrity, and query performance.
While these technologies introduce significant innovations, they are fundamentally designed with predominantly batch processing workflows in mind:
- Designed for Batch Processing: These formats excel at batch processing by optimizing queries over large, static datasets.
- Streaming Capabilities: Although some of these table formats incorporate streaming features, (Hudi, for example, can support some streaming use cases and CDC data) they often fall short of the high-performance demands of streaming-first architectures.
- Latency Challenges: Achieving real-time updates and second-level query freshness is challenging, especially when working with large streaming datasets.
These table formats display several shortcomings when integrated with streaming engines like Apache Flink. As a whole, the Flink connectors for Apache Iceberg, Delta Lake, and Apache Hudi struggle to meet the stringent requirements of streaming-first engines and fail to address many of the use cases that Flink aims to support. This limits the ability for businesses to achieve the low-latency, high-throughput, unified batch and stream processing capabilities they increasingly demand.
One architecture that is commonly used today involves streaming data into Apache Iceberg tables to enable analytical systems to query these tables efficiently. While effective for certain scenarios, this approach still presents several limitations:
- Limited Streaming Use Cases: Current implementations focus on streaming ingestion only, leaving significant gaps in achieving end-to-end streaming pipelines. As a result, expanding the scope of use cases remains challenging.
- High Resource Demand: The absence of streaming materialized views within the Lakehouse architecture leads to frequent recomputation of queries, which is computationally intensive and resource-heavy.
- Pipeline Fragmentation: Integrating streams and tables often necessitates using disparate systems, resulting in complex and fragmented pipelines that increase operational complexity and reduce overall efficiency.
These challenges highlight the need for more integrated solutions that seamlessly support advanced streaming use cases while maintaining the flexibility and performance expected in modern Lakehouse environments.
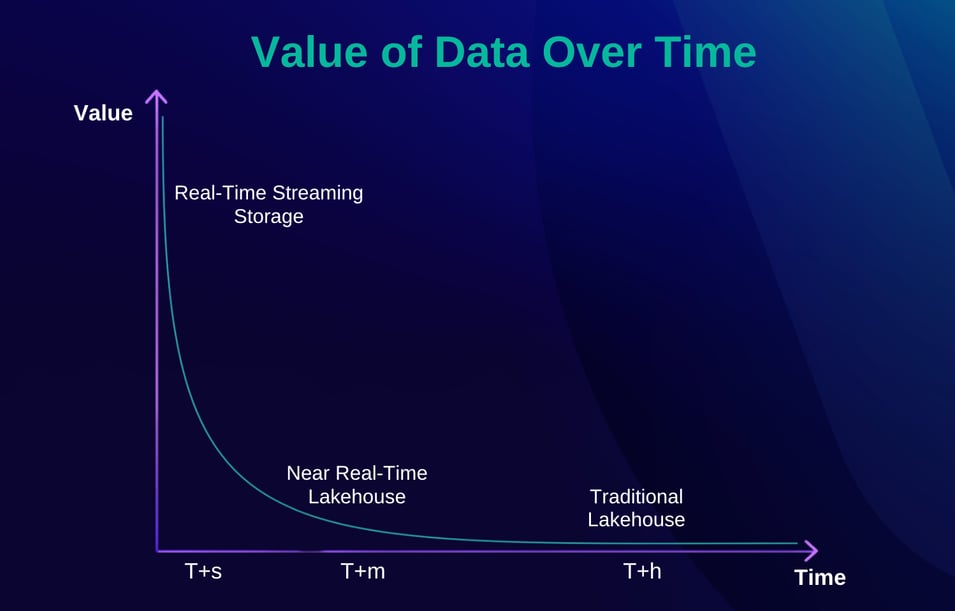
Figure 2: Value of Data Decreases Over Time
As organizations increasingly demand real-time insights and the seamless integration of batch and streaming workloads, the limitations of these predominantly batch-oriented approaches become more apparent. To bridge these gaps, Streamhouse is designed explicitly to prioritize streaming-first use cases, while preserving the flexibility and structural advantages of the Lakehouse.
Streamhouse and Real-Time Streaming Storage for Data Analytics
Streamhouse unifies streaming and the Lakehouse, (much like the Lakehouse unifies Data Lakes and data warehouses). As the next evolution, Streamhouse combines the real-time capabilities of data streaming with the flexibility and structure of the Lakehouse, offering a single solution that seamlessly integrates both real-time and batch workloads.
Streamhouse not only enables organizations to achieve streaming-first architectures without compromising on batch efficiency and scalability, but it also enables stream/table duality within the same system. Technologies like Apache Paimon and Fluss support both streams (append-only data) and tables (updates), offering different table types that meet diverse user needs and use cases. This convergence delivers an integrated, efficient, and flexible solution that exceeds modern data processing demands.
In the next two sections, we’ll explore how these adjacent technologies support Streamhouse, and provide a cost-effective solution that prioritizes stream processing, while continuing to support batch use cases.
Apache Paimon: Near Real-Time Lakehouse Storage
Apache Paimon is an evolution of traditional Lakehouses, designed specifically to address the needs of real-time, streaming-first workloads. While there are attempts to introduce more support for streaming use cases in Lakehouses like Apache Iceberg, Lakehouses are still fundamentally built to address batch processing. Alternatively, Paimon enables an architecture that is optimized for streaming and excels in low-latency, high-throughput scenarios.
Key Advantages of Apache Paimon
- Optimized for Streaming: Paimon is built to handle high-frequency data updates and real-time queries efficiently, making it ideal for modern applications with lower latency requirements.
- Native CDC Support: Paimon natively ingests Change Data Capture (CDC) streams, ensuring real-time updates for dynamic and evolving datasets.
- Cost-Effective Alternative to Message Queues: With built-in support for strong ordering guarantees and integration with tools like Flink CDC, Paimon serves as a cost-effective alternative to projects like Kafka for certain workloads, trading minimal latency increases for significant cost savings.
- Iceberg Interoperability: Paimon supports Iceberg snapshots, enabling seamless integration with existing Lakehouse ecosystems, while concurrently offering unique benefits for streaming workloads.
Apache Paimon addresses many of the challenges associated with traditional batch-first Lakehouses, (including Lakehouse’s higher latencies and inefficiencies in solving real-time scenarios) by focusing on streaming-first use cases. Paimon is particularly well-suited for businesses seeking a unified platform to handle both real-time and historical data processing.
Paimon’s origination and design began with the desire to bring streaming and stream processing with Apache Flink to the Lakehouse, essentially unlocking the ability to implement the Kappa Architecture directly on the Lakehouse.
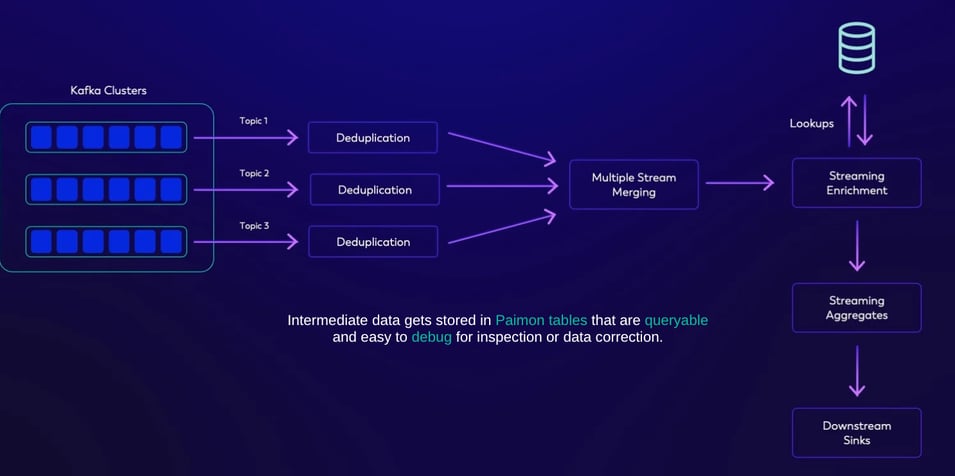
Figure 3: Revisit Kappa Architecture
Revisiting Figure 1, this architecture can be implemented with an alternative approach that replaces Kafka entirely with Paimon (provided minor additional latency is acceptable for the required use case). Paimon inherently offers all the necessary properties required for this architecture, and this substitution results in a significantly more cost-effective solution. Furthermore, this architecture enhances transparency and flexibility by utilizing intermediate tables instead of topics. These tables are also directly queryable, which simplifies inspection and debugging processes and enables seamless integration with analytical engines for direct queries.
Paimon is a great fit for creating streaming-first architectures directly on the Lakehouse. However, as it interacts directly with files on object storage, the latency is near-time (typically to ~1minute) for large scale updates that can handle TBs of real-time data.
Next, let’s dive into Fluss, which is a real-time streaming storage for sub-second-level latencies.
Fluss: Real-Time Streaming Storage
Fluss is a streaming storage built for real-time analytics which can serve as the real-time data layer for Lakehouse architectures. Fluss solves the limitations that log-based streaming storage solutions like Kafka have regarding data analytics, and helps users refine the implementation of the Kappa Architecture. With its columnar stream and real-time update capabilities, Fluss integrates seamlessly with Apache Flink and enables high-throughput, low-latency, cost-effective streaming data warehouses tailored for real-time applications.
Key Features and Benefits of Fluss
The key features and benefits of Fluss for streaming data analytics include:
- Sub-Second Latency: Fluss ensures sub-second latency streaming reads and writes, enabling immediate read and write operations for fast, actionable insights. Ideal for time-sensitive applications like monitoring and financial platforms, Fluss delivers data as soon as it's ingested.
- Updates and Changelogs - Stream/Table Duality: Fluss supports stream-table duality, allowing efficient updates with comprehensive changelogs. This ensures consistent data flow, providing full visibility into stream changes for accurate real-time and historical insights within the same system.
- Ad-Hoc, Interactive Queries: Fluss is fully queryable, enabling direct data inspection without extra processing layers. This reduces development complexity, simplifies debugging, and allows immediate access to live data insights.
- Unified Batch and Streaming: Fluss offers a unified batch and streaming data system, enabling efficient historical processing alongside live streams. This seamless integration optimizes infrastructure for AI, ML, and analytics workloads.
- Column Pruning: Fluss uses column pruning to optimize streaming reads, fetching only the necessary fields for queries. This reduces data transfer, improving performance up to 10x and lowering network costs.
- Columnar Streaming Reads: With columnar streaming reads, Fluss enhances performance by storing data in a columnar format. This improves compression and speeds up analytics, making it perfect for data-heavy, real-time applications.
Named after the German word for “river,” Fluss symbolizes the continuous flow of data into unified storage and redefines real-time analytics with exceptional performance, scalability, and flexibility, making it an important enablement piece for the next generation of streaming storage solutions.
Fluss and Paimon: Complementary Pillars of Streamhouse
While both Fluss and Paimon are Streamhouse technologies, they serve complementary roles:
- Fluss is a real-time streaming storage layer, optimized for data analytics and sub-second query freshness.
- Paimon is a near real-time Lakehouse format with native support for large-scale updates and CDC ingestion, while also offering Iceberg compatibility to ensure harmony with the current Lakehouse ecosystem.
They enable businesses to build robust, scalable, and cost-efficient data platforms that unify batch and streaming workloads. The future is streaming-first, but not at the expense of batch processing. Instead, the focus is on unifying the two paradigms to support diverse workloads with a single architecture. As the ecosystem matures, businesses can benefit from adopting Streamhouse.
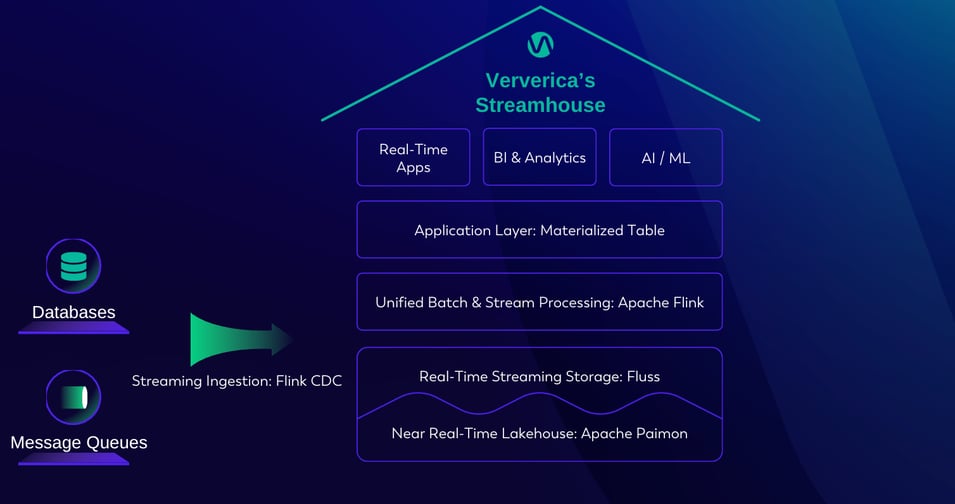
Figure 4: Ververica’s Streamhouse
Benefits of Ververica's Streamhouse
- Real-Time Decision Making: With real-time analytics, businesses can respond quickly to market changes, customer needs, and operational challenges, driving competitive advantage in industries like e-commerce, finance, and logistics.
- Unification of Batch and Streaming Workloads: By integrating batch and streaming capabilities, Streamhouse eliminates silos between the two, enabling seamless data processing within a single architecture. This reduces operational complexity and enhances flexibility.
- Simplified Data Systems: Streamhouse replaces fragmented pipelines with a cohesive framework, lowering infrastructure costs and simplifying data operations while reducing the total cost of ownership.
- Scalability and Performance: Technologies like Fluss and Apache Paimon empower businesses to handle high-throughput workloads with low latency, ensuring seamless scalability as data volumes grow.
- Future Proof Infrastructure: Designed to support both real-time and historical processing, Streamhouse offers the flexibility to adapt to evolving data requirements without rearchitecting pipelines.
For modern enterprises, Ververica’s Streamhouse provides the tools to unlock real-time insights, streamline operations, and build a scalable, cost-efficient data platform.
Conclusion
Streaming data architectures have evolved significantly over time in the relentless pursuit of simplicity, flexibility, and real-time insights in modern data systems. Each new architecture has addressed the challenges of their time, and Streamhouse offers a transformative next step as a unified solution that bridges the gap between real-time and batch workloads.
With supporting technologies like Fluss and Apache Paimon, Streamhouse is much more than an incremental improvement, instead, it represents a paradigm shift in how to think about real-time data processing. By combining low-latency streaming capabilities with the analytical power of the Lakehouse, this new solution enables businesses to extract meaningful insights from their data faster, more efficiently, and at scale.
Looking ahead, Streamhouse offers a robust foundation for businesses to thrive in a real-time, data-driven world. Organizations that adopt strategies that unify streaming and batch processing are better equipped to stay ahead of the curve and can unlock new business opportunities empowered with the data required to make smarter data-driven decisions.
With Streamhouse, the limitations of the Kappa and Lakehouse architectures disappear, allowing businesses to address modern data challenges and unlock the potential of truly unified stream and batch processing systems.
Additional Resources
Learn more about Streamhouse:
Explore Apache Paimon:
Get to Know Fluss:
- Announcement Blog: Introducing Fluss: Unified Streaming Storage For Next-Generation Data Analytics
- Blog: Fluss Goes Open Source
- Flink Forward Berlin 2024 Opening Session Keynote Announcement:The Future - Introducing Fluss
- Flink Forward Berlin 2024 Fluss Breakout Presentation: Is Kafka the Best Storage for Streaming Analytics?
Ready to get started with the power of Streamhouse?
Learn more about Ververica’s Unified Streaming Data Platform, powered by the VERA engine.
You may also like

Your AI Coding Assistant Can't Touch Your Streaming Platform. Until Now

Zero Trust Theater and Why Most Streaming Platforms Are Pretenders

No False Trade-Offs: Introducing Ververica Bring Your Own Cloud for Microsoft Azure
