














We are excited to introduce Fluss, a groundbreaking project designed to tackle longstanding challenges in streaming data storage and analytics. Named after the German word for 'river,' Fluss is engineered to offer a high-performance, scalable, and fully integrated solution for real-time data processing with Apache Flink®, driving our vision towards a complete unified batch and streaming data platform.
Streaming Storage for Next-Generation Data Analytics
Apache Flink has become the de facto standard for stream processing and Flink SQL has become an indispensable tool for users to build real-time applications. Typical application scenarios include data cleaning, feature engineering and extraction, transformations, multi-stream merging and joins, aggregations, and more. Flink is often deployed along with a streaming storage layer like Apache Kafka and combined with real-time OLAP systems, such as Clickhouse and StarRocks. This enables the creation of streaming-first architectures that treat all incoming data as unbounded streams, with the ability to process and analyze data as it arrives.
The following figure depicts a streaming-first architecture:
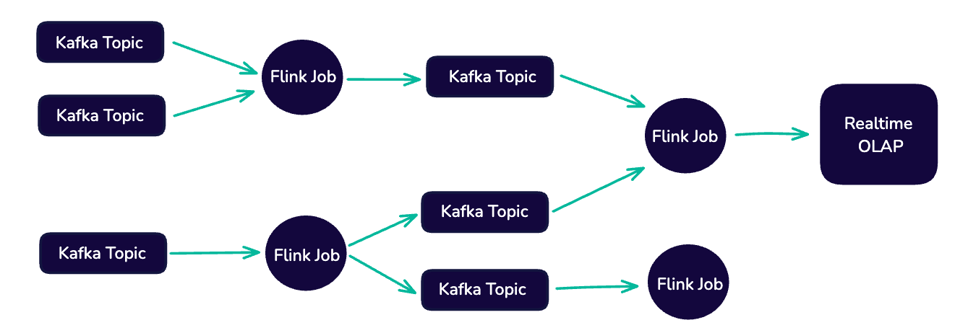
IMAGE 1: STREAMING-FIRST ARCHITECTURE
Apache Kafka plays a central role in such architectures by acting as the backbone for storing and transporting real-time data. It can capture events from multiple sources—applications, sensors, and databases—and stream them in real time to consumers, like analytics platforms, microservices, or machine learning models. Kafka's high throughput, fault tolerance, and scalability make it a popular choice for building large-scale, real-time data pipelines.
On top of Kafka, Apache Flink provides a powerful framework for real-time data processing. Flink’s stream-first architecture allows it to handle continuous data flows, making it an excellent choice for event-driven applications that require sub-second latency. Flink’s support for stateful computations, windowing, and exactly-once processing semantics allows for complex operations such as event-time processing and real-time aggregations.
These capabilities have fueled the adoption of streaming-first architectures, allowing companies to develop solutions for real-time fraud detection, personalized recommendations, monitoring systems, and more.
The Need for Unified Streaming Storage
Although Apache Kafka has excelled as a row-oriented, log-based storage layer, it falls short in certain key areas, especially regarding real-time data analytics. Log-based storage falls short in the following areas:
- Handling Upserts Efficiently: Upserts (Updates and Inserts) are common when working with streaming systems. Kafka doesn’t natively support upserts in the way that stream processors like Flink require. Apache Flink needs to generate changelogs to track updates, which can introduce latency and complexity to ensure state consistency. This results in issues with result correctness, incomplete semantics (PK semantics can not be completely aligned), and slower processing times, particularly for large-scale or high-throughput systems.
- No Direct Query Capabilities: Kafka lacks direct query support, meaning users can’t easily access or extract insights from streaming data without building additional infrastructure layers like stream processors or data stores. This adds complexity and delays in accessing real-time insights as it requires moving the data to an external system, such as a data warehouse or a data lake, to perform complex queries and analytics. Revisiting Image 1, notice that the main reason for the intermediate Kafka topics is to store intermediate results without actual business value, resulting in unnecessary storage amplifications as they can’t be reused.
- Historical Data Processing: To perform historical analysis, Kafka users must replay entire logs, which is not only time-consuming but also computationally expensive. This approach creates a bottleneck for companies that need to analyze large volumes of past data quickly and efficiently.
- Debugging Challenges: Debugging issues within Kafka is cumbersome due to its log-based architecture. Users often have to sift through large logs without the ability to directly query and inspect the data, making troubleshooting inefficient and costly.
- High Network Costs and Bottlenecks: Kafka’s architecture often requires heavy data movement across networks, leading to significant infrastructure costs and performance bottlenecks, especially when scaling for real-time analytics.
Apache Flink’s strength lies in real-time data processing, and it's often paired with Online Analytical Processing (OLAP) systems for deep-dive analysis of aggregated data. However, OLAP introduces its challenges in the architecture, particularly when considering storage costs. OLAP systems are designed to enable fast, multidimensional queries over large datasets, which are particularly useful for reporting, dashboards, and business intelligence use cases. However, this capability comes at a cost—literally.
Apache Flink uses RocksDB to store state, but it lacks a streaming storage layer to provide a database-level experience. Flink needs to stitch multiple upstream and downstream storage components, which increases the complexity of the system and affects the experience (some systems support upserts and some don’t, and primary key constraints are easily broken). There are a lot of variations between different storage layers, and behaviors vary greatly, leading to problems of not knowing what to choose. What is missing is a streaming storage layer that resembles a data warehouse while being native to Flink.
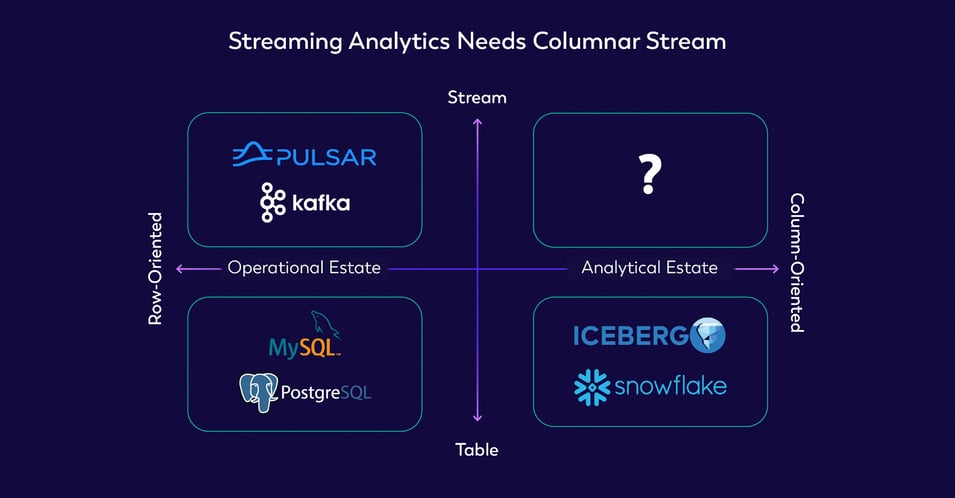
IMAGE 2: COLUMNAR STREAMING STORAGE IS MISSING
It is difficult to transform existing streaming solutions to fit these needs, so we developed a streaming storage designed for real-time analytics. This started the development of Fluss, a purpose-built storage layer optimized for modern stream processing needs.
Introducing Fluss
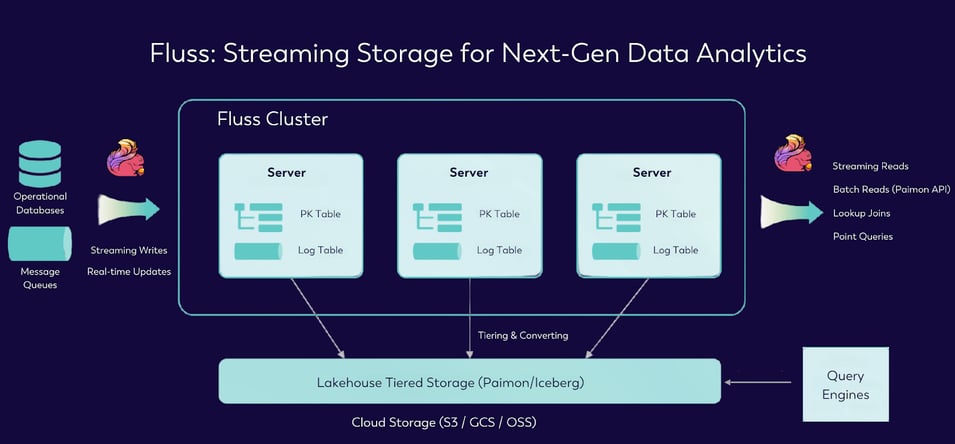
IMAGE 3: ARCHITECTURE OVERVIEW WITH FLUSS
Fluss is designed to provide a unified streaming storage layer that addresses these specific limitations head-on. The key features and benefits of Fluss in the world of streaming data analytics include:
- Sub-Second Latency: Fluss ensures sub-second latency streaming reads and writes, enabling immediate read and write operations for fast, actionable insights. Ideal for time-sensitive applications like monitoring and financial platforms, it delivers data as soon as it's ingested.
- Updates and Changelogs - Stream-Table Duality: Fluss supports stream-table duality, allowing efficient updates with comprehensive changelogs. This ensures consistent data flow, providing full visibility into stream changes for accurate real-time and historical insights within the same system.
- Ad-hoc, Interactive Queries: Fluss is fully queryable, enabling direct data inspection without extra processing layers. This reduces development complexity, simplifies debugging, and allows for immediate access to live data insights.
- Unified Batch and Stream: Fluss offers a unified platform for batch and streaming data, enabling efficient historical processing alongside live streams. This seamless integration optimizes infrastructure for AI, ML, and analytics workloads.
- Projection Pushdown: Fluss uses projection pushdown to optimize streaming reads, fetching only the necessary fields for queries. This reduces data transfer, improving performance up to 10x and lowering network costs.
- Columnar Streaming Reads: With columnar streaming reads, Fluss enhances performance by storing data in a columnar format. This improves compression and speeds up analytics, making it perfect for data-heavy, real-time applications.
It also provides lakehouse tiered storage such as Apache Paimon and Apache Iceberg, allowing bi-directional communication with lakehouses. This allows a streaming job to load state from batch sources, enabling seamless state initialization and synchronization between batch and streaming data.
Fluss has been running in production for the last few months. It will be open-sourced and donated to the Apache Software Foundation (ASF) at the end of the year.
The Future of Real-Time Data Analytics
In the age of AI and machine learning, where data must be both accessible and immediately actionable, Ververica provides a solution for businesses looking to harness real-time and historical data together. Whether you're building advanced analytics pipelines, monitoring real-time events, or implementing AI-driven insights, Ververica’s Streaming Data Platform provides the flexibility, speed, and efficiency you need to succeed.
We hope that the idea of streaming storage for Apache Flink that can be shared across multiple systems holds the potential to significantly reshape the landscape of real-time data processing and analytics. By integrating a native, purpose-built storage system within Flink, organizations can achieve a unified architecture that seamlessly supports both real-time and long-term data processing. This would eliminate the current need for intermediate Kafka topics or separate stream processing tools, simplifying data pipelines and reducing operational complexity.
More Resources
- Get started unlocking the full power of Apache Flink with Veverica’s Streaming Data Platform by contacting us.
- Learn more about VERA, the engine powering Ververica's Streaming Data Platform, in a 3-part blog series.
- Explore Apache Paimon: The Streaming Lakehouse

You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
