














Imagine a photo without its vibrant colors; intriguing but lacking depth. Stream enrichment works similarly for data. It infuses raw data streams with added context, transforming them from grayscale to full color.
Going beyond the simple transmission of information, stream enrichment breathes life into data, augmenting it with additional context and details. By embedding supplementary data into an existing data stream, businesses and organizations can paint a clearer picture, driving enhanced understanding and decision-making. Let's explore this transformative process.
Examples of stream enrichment
| Examples of Primary Data | Examples of Enrichment Data |
| e-commerce transactions | customer account data |
| IoT sensor events | sensor reference data |
| mobile telephone billing records | location data |
| credit card swipes | currency exchange rates |
| online music streaming logs | user preferences and playlists |
Questions to ask yourself before implementing stream enrichment in Apache Flink®
Enrichment is a fundamental task in many data processing pipelines, and Apache Flink provides multiple ways to achieve it. The “best” solution depends on many factors such as data size, throughput, latency, desired output format, and many more.
You should first ask yourself these five questions before you jump into the nuts and bolts of the technical execution of stream enrichment.
- Where is the ground truth for the reference data?
- What sort of load can that database or service handle?
- Is it okay to enrich with stale data?
- What sort of throughput and latency are required?
- Would it make sense to completely mirror the data into Flink state?
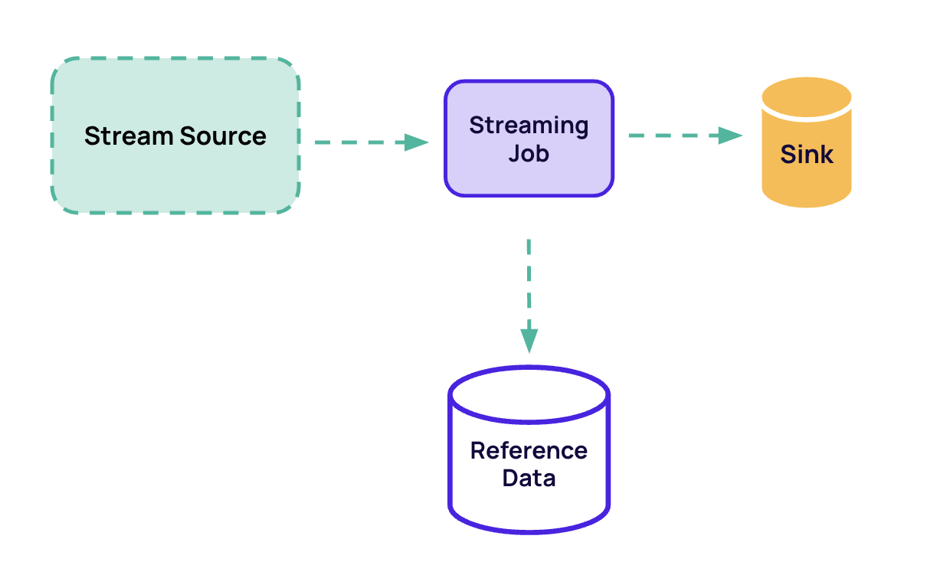
Three ways to access reference data
1. Preload the entire reference dataset into memory on start-up
2. Perform per-record lookups, requesting reference data as needed
3. Stream in the reference data and store it in Flink state
Preloading of Reference Data
Issue at hand: We're uncertain about the specific keys needed for data retrieval.
Enrichment in Apache Flink is challenging when dealing with large reference datasets. When a task requires looking up a large number of values from a reference dataset, preloading the reference data from a database in the open() of a RichFlatMapFunction may be an option.
This approach does have its drawbacks, as it requires knowledge of which keys to look up in advance. Let’s see how we can solve this problem.
Solution 1: Fetch all the data
One solution to the problem at hand is to simply fetch all the data from the reference dataset in the open() of the RichFlatMapFunction. This allows us to look up any key without knowing it beforehand. The downside of this approach is that it can be very inefficient if the reference dataset is large.
public class EnrichmentWithPreloading extends RichFlatMapFunction<Event, EnrichedEvent> {
private Map<Long, SensorReferenceData> referenceData;
@Override
public void open(final Configuration parameters) throws Exception {
super.open(parameters);
referenceData = loadReferenceData();
}
@Override
public void flatMap(
final Event event,
final Collector<EnrichedEvent> collector) throws Exception {
SensorReferenceData sensorReferenceData =
referenceData.get(sensorMeasurement.getSensorId());
collector.collect(new EnrichedEvent(event, sensorReferenceData));
}Solution 2: Use a custom partitioner
Another solution is to use a custom partitioner to determine which task will be responsible for each key. This partitioner will be used to distribute the reference data across the tasks. This approach is more efficient than the first solution, as it only requires fetching the data for the keys that are relevant to the task. Additionally, this approach allows for the data to be processed in parallel, which can result in faster processing times.
public interface Partitioner<K> extends java.io.Serializable, Function {
/**
* Computes the partition for the given key.
*
* @param key The key.
* @param numPartitions The number of partitions to partition into.
* @return The partition index.
*/
int partition(K key, int numPartitions);
}Applying custom partitioning
private static class SensorIdPartitioner implements Partitioner<Long> {
@Override
public int partition(final Long event, final int numPartitions) {
return Math.toIntExact(event % numPartitions);
}
}
public static void main(String[] args) throws Exception {
...
DataStream<Event> events = env.addSource(new SensorEventSource(...));
DataStream<EnrichedEvent> enrichedEvents = events
.partitionCustom(new SensorIdPartitioner(), measurement -> measurement.getSensorId())
.flatMap(new EnrichmentFunctionWithPartitionedPreloading());
public class EnrichmentWithPartitionedPreloading extends RichFlatMapFunction<Event, EnrichedEvent> {
private Map<Long, SensorReferenceData> referenceData;
@Override
public void open(final Configuration parameters) throws Exception {
super.open(parameters);
referenceData = loadReferenceData(
getRuntimeContext().getIndexOfThisSubtask(),
getRuntimeContext().getNumberOfParallelSubtasks()
);
}
@Override
public void flatMap(
final Event event,
final Collector<EnrichedEvent> collector) throws Exception {
SensorReferenceData sensorReferenceData = referenceData.get(sensorMeasurement.getSensorId());
collector.collect(new EnrichedEvent(event, sensorReferenceData));
}Preloading of reference data is only suitable for certain use cases, i.e., rarely changing data that fits in memory. Pros of these solutions include simplicity, high throughput, low latency, and the ability to enrich streaming data with data from databases. Cons include the potential to enrich stale data, the need for the reference dataset to fit in memory, and the inability to use it to bootstrap keyed state.
Per-record Lookup of Reference Data
Per-record lookup of reference data involves looking up related information from a reference dataset for each record of the input data. This approach offers the advantage of having up-to-date data as the reference dataset can be updated independently of the input data. On the downside, this approach can be more resource-intensive and can lead to longer processing times.
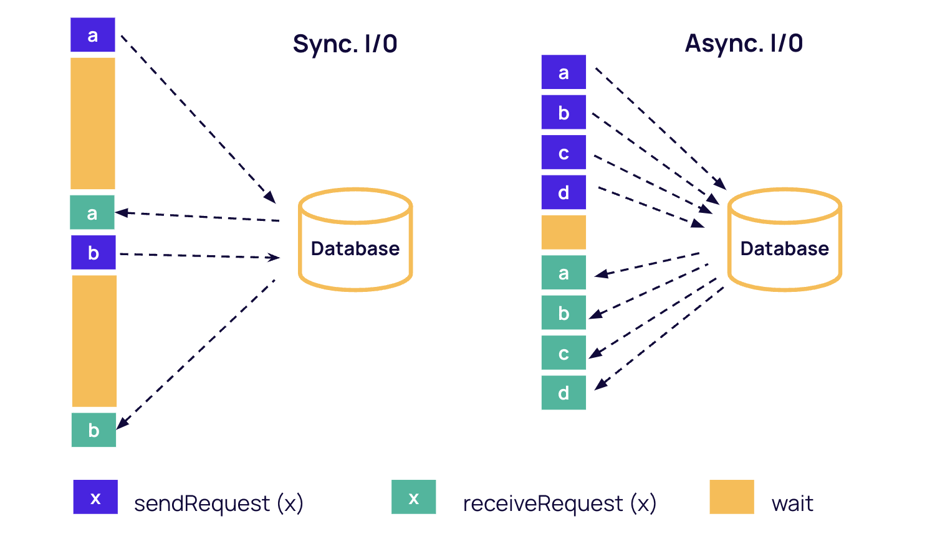
Flink SQL supports both synchronous and asynchronous lookup of reference data, allowing users to select the best approach for their use case. Synchronous lookup is easy to implement using the RichFlatMapFunction, while asynchronous lookup is supported by Flink's Async I/O operator.
Calling an AsyncFunction
Calling an AsyncFunction is another common way of enriching data in Apache Flink. This approach involves calling an asynchronous function for each record of the input data. It provides enhanced throughput since the AsyncFunction can handle multiple records at once. Additionally, it can make use of a configurable timeout and capacity parameters, which allows the user to control the trade-off between latency and throughput.
DataStream<EnrichedEvents> enrichedEvents =
AsyncDataStream.(un)orderedWait(
events,
new AsyncEnrichmentFunction(),
1000, TimeUnit.MILLISECONDS, // timeout
100 // max number of in-flight requests
);Flink avoids potential pitfalls by maintaining correct watermarking. With unorderedWait(), Flink takes care not to allow watermarks to be emitted too early or too late. The out-of-orderness introduced by unorderedWait() is only allowed between watermarks. Flink also stays clear of potential pitfalls by ensuring fault tolerance. The Futures for in-flight requests are stored in state snapshots, and re-triggered during recovery.
public class AsyncEnrichmentFunction extends RichAsyncFunction<Event, EnrichedEvent> {
private ReferenceDataClient client;
@Override
public void open(final Configuration parameters) throws Exception {
super.open(parameters);
client = new ReferenceDataClient();
}
@Override
public void asyncInvoke(final Event event, final ResultFuture<EnrichedEvent> resultFuture) {
client.asyncGetReferenceDataFor(
event.getReferenceId(),
new Consumer<ReferenceData>() {
@Override
public void accept(final ReferenceData referenceData) {
resultFuture.complete(Collections.singletonList(new EnrichedEvent(
event,
referenceData)));
}
});
}
}Capture Reference Data as a Stream
Apache Flink provides multiple ways to join two streams and perform enrichment.
- Key both streams and implement a DIY join with CoProcessFunction
- Key one stream and broadcast the other, using KeyedBroadcastProcessFunction
- The DataStream API offers time-windowed joins
- The SQL/Table APIs provide several types of joins
- regular INNER + OUTER joins
- time-windowed INNER + OUTER joins
- temporal joins with versioned tables
- lookup joins with external databases
Enrichment via lookup
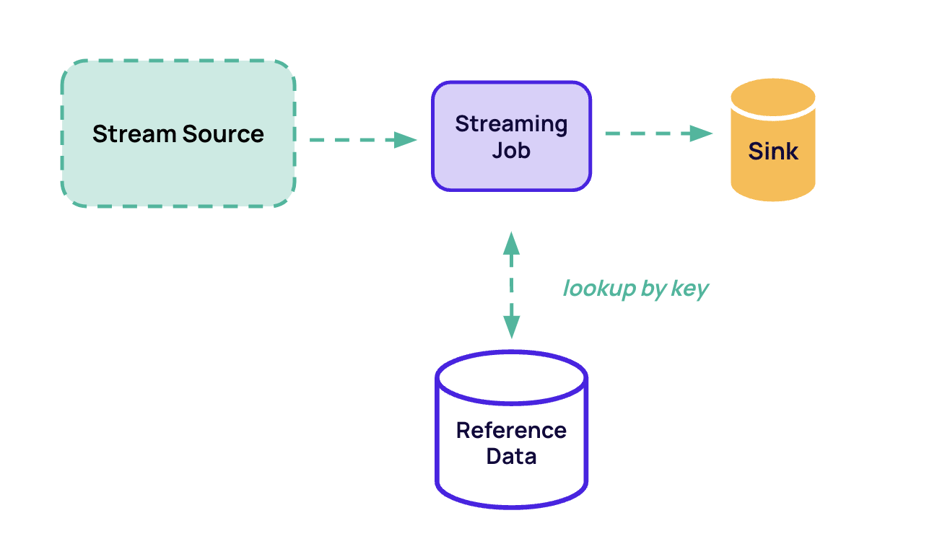
Enrichment via reference data source
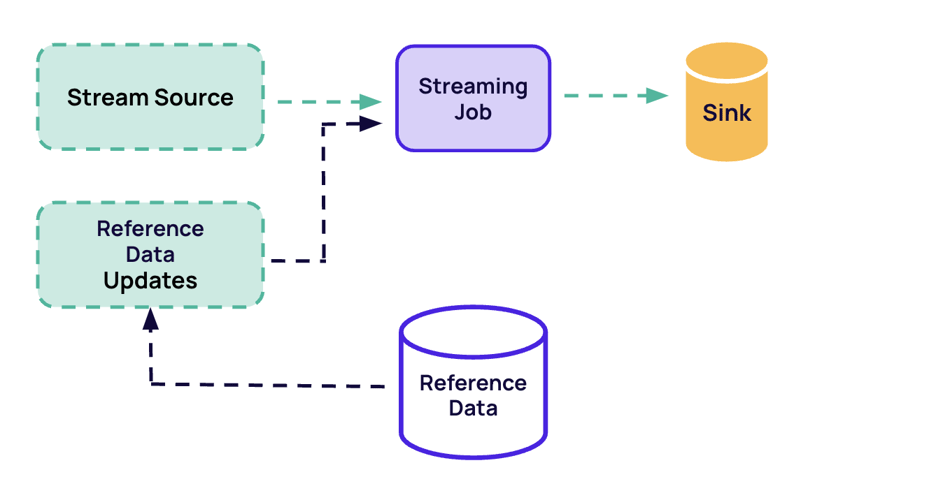
Flink provides connectors for popular streaming sources such as Compacted Kafka Topics, Debezium, Maxwell's Daemon, and Canal.
When working with a bootstrap state, you should use the bootstrap state for enrichment by reading from some stream until it is "caught up". Then, you should begin to process the main stream, using that enrichment state while continuing to receive updates for the enrichment stream.
However, Flink doesn't make this easy but you can use the State Processor API to build an initial savepoint from a DB dump. Also, you can prepare a special bootstrapping version of your job that reads from the enrichment stream until the state is ready. Then, you can create a savepoint, and start your real job from that savepoint making sure the stateful operators in both jobs have matching UIDs.
Conclusion
Overall, Apache Flink is a great choice for stream enrichment and data processing for any application that requires real-time data processing. Stream enrichment is a great way to add context to data streams, enabling better decision-making and deeper insights; ultimately increasing the value of your data.
Make sure to read our previous blog posts about Flink:
- All You Need to Know About PyFlink
- Flink's Test Harnesses Uncovered
- Streaming modes of Flink-Kafka connectors
- Flink SQL Joins - Part 1 (Regular Joins, Interval Joins, Lookup Joins)
- Flink SQL Joins - Part 2 (Temporal Table Joins, N-Way Join)
- Flink SQL: Joins Series 3 (Lateral Joins, LAG Aggregate Function)
- Joining Highly Skewed Streams in Flink SQL

You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
