














PyFlink serves as a Python API for Apache Flink, providing users with a medium to develop Flink programs in Python and deploy them on a Flink cluster.
In this post, we will introduce PyFlink from the following aspects:
- The structure of a fundamental PyFlink job and some basic knowledge surrounding it
- The operational mechanisms of PyFlink jobs, the high-level architecture, and its internal workings
- Essential performance optimization strategies for PyFlink
- Future projections for PyFlink
By the end of this article, you should have a firm grasp on PyFlink and its potential applications.
If you find yourself needing real-time computing solutions, such as real-time ETL, real-time feature engineering, real-time data warehouse, real-time prediction, and you're comfortable with the Python language or want to use some handy Python libraries in the process, PyFlink is an excellent starting point as it merges the worlds of Flink and Python.
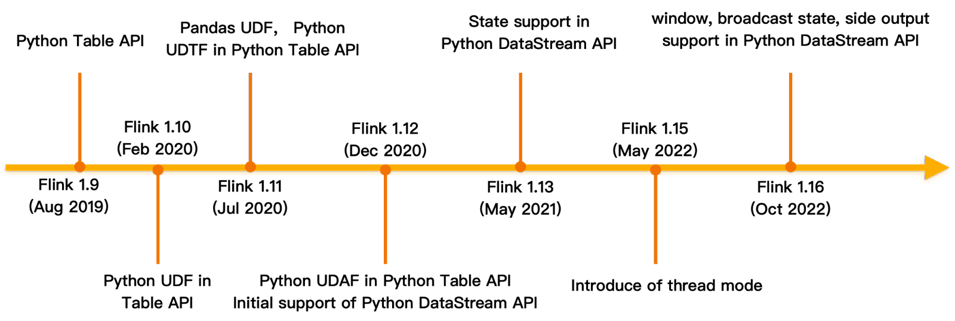
PyFlink was first introduced into Flink in Flink 1.9, dating back to 2019. This inaugural version offered only limited functionalities. Since then, the Flink community has strived to continually enhance PyFlink. After nearly four years of diligent development, it has become more and more mature. Currently, it encompasses most functionalities found in the Flink Java API. Additionally, PyFlink exclusively provides several features, like Python user-defined function support, among other functionalities.
Getting Started with PyFlink
PyFlink is integrated into current versions of Ververica Platform. If you want to get a feel for PyFlink’s capabilities and are working in a Kuberbetes capable environment, you can download Community Edition for free and spin up a minikube playground in minutes.
If you prefer to work with vanilla Flink, then you can install PyFlink from PyPI:
$ pip install apache-flinkFor the latest Flink 1.17 you’ll need a Python version later than Python 3.6, up to and including Python 3.10; Flink 1.16 supports Python versions from 3.6 to 3.9. Note that Python/PyFlink must be available to each node in the cluster. The most flexible way to do this is to pass in a Python environment when you submit a PyFlink job, but if you have many deep Python dependencies it may be simpler just to preinstall the Python environment to each cluster node.
You can alternatively build PyFlink from source, which you may want to do if you maintain your own fork of Flink or need to cherry-pick commits which are still not released.
Flink Basics for PyFlink
If you are new to Flink, there are a few basic concepts it’s good to understand and which are relevant also to PyFlink:
- Flink offers two different APIs, the procedural and relatively low level DataStream API and the relational/declarative Table API. Don’t be misled by their names: both APIs can be applied to either stream or batch processing, and both have PyFlink APIs.
- Flink is a distributed computing engine. It has no storage besides the state which provides the immediate context during processing. Data is assumed to flow from an external data source to (typically, but it’s not required) an external data sink. A Flink/PyFlink job needs at least a data source.
- At the heart of any Flink/PyFlink application are the data transformations that compute the desired results from the source data – which can involve reshaping or sampling data, merging and enriching, comparing or modeling, processing transactions, or any of the countless other ways you might want to perform computations over unbounded data streams or massive data sets.
Define Data Source and Sink
The first step for any PyFlink job is to define the data source, and optionally the data sink to which the execution results will be written.
PyFlink fully supports both the Table API and the DataStream API. Both APIs provide many different ways to define sources and sinks, and a single job can combine both APIs, for example converting between Table API reads and DataStream API writes, or DataStream API reads and Table API writes.
Below is a typical read and write example for each API. The examples assume Kafka streams provide the source/sink.
Reading from Kafka using Table API:
env_settings = EnvironmentSettings.in_streaming_mode()
t_env = TableEnvironment.create(env_settings)
t_env.create_temporary_table(
'kafka_source',
TableDescriptor.for_connector('kafka')
.schema(Schema.new_builder()
.column('id', DataTypes.BIGINT())
.column('data', DataTypes.STRING())
.build())
.option('properties.bootstrap.servers', 'localhost:9092')
.option('properties.group.id', 'my-group')
.option('topic', 'input-topic')
.option('scan.startup.mode', 'earliest-offset')
.option('value.format', 'json')
.build())
table = t_env.from_path("kafka_source")Reading from Kafka using DataStream API:
source = KafkaSource.builder() \
.set_bootstrap_servers("localhost:9092") \
.set_topics("input-topic") \
.set_group_id("my-group") \
.set_starting_offsets(KafkaOffsetsInitializer.earliest()) \
.set_value_only_deserializer(
JsonRowDeserializationSchema.builder()
.type_info(Types.ROW([Types.LONG(), Types.STRING()]))
.build()) \
.build()
env = StreamExecutionEnvironment.get_execution_environment()
ds = env.from_source(source, WatermarkStrategy.no_watermarks(), "Kafka Source")Writing to Kafka using Table API:
env_settings = EnvironmentSettings.in_streaming_mode()
t_env = TableEnvironment.create(env_settings)
t_env.create_temporary_table(
'kafka_sink',
TableDescriptor.for_connector('kafka')
.schema(Schema.new_builder()
.column('id', DataTypes.BIGINT())
.column('data', DataTypes.STRING())
.build())
.option('properties.bootstrap.servers', 'localhost:9092')
.option('topic', 'output-topic')
.option('value.format', 'json')
.build())
table.execute_insert('kafka_sink')Writing to Kafka using DataStream API:
sink = KafkaSink.builder() \
.set_bootstrap_servers('localhost:9092') \
.set_record_serializer(
KafkaRecordSerializationSchema.builder()
.set_topic("topic-name")
.set_value_serialization_schema(
JsonRowSerializationSchema.builder()
.with_type_info(Types.ROW([Types.LONG(), Types.STRING()]))
.build())
.build()
) \
.set_delivery_guarantee(DeliveryGuarantee.AT_LEAST_ONCE) \
.build()
ds.sink_to(sink)Refer to the Apache Table API documentation for more details about Table API connectors, and to the Apache DataStream API documentation for more about DataStream API connectors. The Apache API conversion documentation shows how to combine Table API/DataStream API reads/writes.
There are a few things to notice:
- The Table API examples define source/sink properties as key/value pairs. All Table API connectors follow that pattern To use a different connector, or to define a new connector that is not officially supported in PyFlink, just configure appropriate key/value pairs.
- The DataStream API connectors are less regular; each connector provides a stack of completely different APIs. Refer to the specific connector page to see which APIs are provided. To use a connector not supported by PyFlink you need to write a Python wrapper for the corresponding Java API, see the supported connectors for examples.
Transformations
Both APIs support a wide range of transformations.
The DataStream API includes the following functionality:
- map: Convert one element into another
- flat map: Takes one element as input and produce zero, one, or more elements
- filter: Evaluates a boolean function for each element and filter out the ones which return false
- aggregation: Accumulating multiple elements
- windowing: Group elements into different windows and perform calculations for each group
- connect: Connect two different streams, allows sharing state between two streams
- process: Similar to flat map, however, is more flexible as it allows access to low level operations, e.g. timer, state, etc.
- broadcast: Broadcast one stream to all the subtasks of another stream
- side output: In addition to the main stream, produce additional side output result stream
- async io: This is still not supported in PyFlink.
The Table API is a relational API with a SQL-like flavor. It includes the following functionality:
- projection: Similar to map in DataStream API
- filter: similar to filter in DataStream API
- aggregation: Similar to SQL GROUP BY, group elements on the grouping keys and perform aggregations for each group
- window aggregation: Group elements into different windows and perform aggregations for each window
- regular join: Similar to SQL JOIN, joins two streams
- lookup (stream-table) join: Joins a stream with a static table
- temporal join: Join a stream with a versioned table, similar to lookup join, however, it allows join a table at a certain point in time
- window join: Join elements of two streams belonging to the same window
- interval join: Join elements of two streams with a time constraint
- topn and windowed topn: N smallest or largest values ordered by columns
- deduplication and windowed deduplication: Removes elements that duplicate over a set of columns
- pattern recognition: Detect elements of a specific pattern in one stream
Again there are a few things to notice:
- If you need fine-grained control of the transformations or access to low level functionality, e.g. timer, state, etc, choose the DataStream API. Otherwise, Table API is a good choice in most cases.
- The Table API also supports executing SQL queries directly , providing access to functions not currently available via the API, e.g. deduplication, pattern recognition, topn, etc. Although the API will continue to grow, using SQL provides an immediate solution.
Job Submission
Flink is a distributed compute engine which executes Flink/PyFlink jobs in a standalone cluster.. Flink jobs are executed lazily; you must explicitly submit jobs for execution. This is a little different from the more interactive/exploratory scripting style that many Python users are used to.
For example, if you have a PyFlink job defined by a Python script word_count.py, you can execute it locally via the Flink console with $ python word_count.py or by right clicking and executing in the Flink IDE. Flink will launch a mini Flink cluster which runs in a single process and executes the PyFlink job.
You can also submit a PyFlink job to a remote cluster using Flink’s command line tool.
Here is a simple example that shows how to submit a PyFlink job to an Apache YARN cluster for execution:
./bin/flink run-application -t yarn-application \
-Djobmanager.memory.process.size=1024m \
-Dtaskmanager.memory.process.size=1024m \
-Dyarn.application.name=<ApplicationName> \
-Dyarn.ship-files=/path/to/shipfiles \
-pyarch shipfiles/venv.zip \
-pyclientexec venv.zip/venv/bin/python3 \
-pyexec venv.zip/venv/bin/python3 \
-pyfs shipfiles \
-pym word_countSee the Apache documentation for more about job submission in Flink.
You can read more about how to define and run a Python script as a PyFlink job in the LINK of PyFlink blog post.
Debug and Logging
At the beginning, Python user-defined functions are executed in separate Python processes which are launched during job startup. This is not easy to debug as users have to make some changes to the Python user-defined functions to enable remote debugging.
Since Flink 1.14, it has supported to execute Python user-defined functions in the same Python process on the client side in local mode. Users could set breakpoints in any places where they want to debug, e.g. PyFlink framework code, Python user-defined functions, etc. This makes debugging PyFlink jobs very easy, just like debugging any other usual Python programs.
Users could also use logging inside the Python user-defined functions for debugging purposes. It should be noted that the logging messages will appear in the logging file of the TaskManagers instead of the console.
import logging
@udf(result_type=DataTypes.BIGINT())
def add(i, j):
logging.info("i: " + i + ", j: " + j)
return i + jBesides, it also supports Metrics in the Python user-defined functions. This is very useful for long running programs and could be used to monitor specific statistics and configure alerts.
Managing Dependencies
For a production job you will almost certainly want to refer to third party Python libraries. Possibly you may also need to use data connectors whose jar files are not part of the Flink distribution - for example connectors for Kafka, HBase, Hive, and Elasticsearch are not bundled in the Flink distribution.
Because PyFlink jobs are executed in a distributed cluster, dependencies also need to be managed across the cluster. PyFlink provides a number of ways to manage dependencies.
JAR Files
You can include JAR files with a PyFlink job:
# Table API
t_env.get_config().set("pipeline.jars", "file:///my/jar/path/connector.jar;file:///my/jar/path/udf.jar")
# DataStream API
env.add_jars("file:///my/jar/path/connector1.jar", "file:///my/jar/path/connector2.jar")You must include all the transitive dependencies. For connectors, use the fat JAR whose name usually includes sql, e.g. flink-sql-connector-kafka-1.16.0.jar for the Kafka connector in preference to flink-connector-kafka-1.16.0.jar.
Third-Party Python Libraries
Add the Python dependencies to the PyFlink venv virtual environment:
# Table API
t_env.add_python_file(file_path)
# DataStream API
env.add_python_file(file_path)The environment, with the specified libraries included, will be distributed across the cluster nodes during execution.
Zipped Python Libraries
If you need to include a large number of Python libraries it’s good practice to pass them in archived form to the virtual environment:
# Table API
t_env.add_python_archive(archive_path="/path/to/venv.zip")
t_env.get_config().set_python_executable("venv.zip/venv/bin/python3")
# DataStream API
env.add_python_archive(archive_path="/path/to/venv.zip")
env.set_python_executable("venv.zip/venv/bin/python3")Command Line Configuration
You can also configure dependencies on the command line to give you extra flexibility:
|
Type of dependency |
Configuration |
Command line options |
|
Jar Package |
pipeline.jars pipeline.classpaths |
--jarfile |
|
Python libraries |
python.files |
-pyfs |
|
Python virtual environment |
python.archives python.executable python.client.executable |
-pyarch |
|
Python Requirements |
python.requirements |
-pyreq |
See Python Dependency Management in the Apache PyFlink documentation for more details.
Other tips
Like Python itself, PyFlink offers great flexibility and adaptability. As you explore the APIs, here are some useful tips.
Use Open() for Initialization
If your Python code depends on a big resource, e.g. a machine learning model, use the open()to load it once at during job initialization:
# DataStream API
class MyMapFunction(MapFunction):
def open(self, runtime_context: RuntimeContext):
import pickle
with open("resources.zip/resources/model.pkl", "rb") as f:
self.model = pickle.load(f)
def map(self, value):
return self.model.predict(value)
# Table API
class Predict(ScalarFunction):
def open(self, function_context):
import pickle
with open("resources.zip/resources/model.pkl", "rb") as f:
self.model = pickle.load(f)
def eval(self, x):
return self.model.predict(x)
predict = udf(Predict(), result_type=DataTypes.DOUBLE())This is more efficient than opening it directly in your Python function:
with open("resources.zip/resources/model.pkl", "rb") as f:
model = pickle.load(f)
@udf(result_type=DataTypes.DOUBLE())
def predict(x):
return mode.predict(x)The simplistic approach causes the resource to be serialized and distributed with the Python function itself and loaded with each invocation; using open() ensures it is only loaded once.
Watermarks
Watermarks trigger the calculation of specific operators e.g. window, pattern recognition, etc when event time is enabled. Be sure to define the watermark generator, otherwise your job may have no output.
PyFlink gives you several different ways to define the watermark generator:
- SQL DDL: See Watermark section for more details.
- Table API: Refer to this example for more details.
- DataStream API: Refer to this example for more details.
If your watermark generator is defined correctly but the watermark isn’t advancing as expected, then possibly your job does not have enough data. This can be true during testing if you have a small test sample. Try setting the parallelism of the job to 1 or configure source idleness to work around the problem during the test phase. See ‘Timely Stream Processing’ for more about watermark behavior.
Flink Web UI
The Web UI is a rich source of information – showing how long the job has run, whether there are any exceptions, the number of input / output elements for each operator, etc.
How you access it depends on the deployment mode:
- Local: The web port is set randomly. You can find it in the log file at /path/to/python-installation-directory/lib/python3.7/site-packages/pyflink/log/<deployment>.local.log):
INFO org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint [] - Web frontend listening at http://localhost:55969.
- Standalone: Configured via configuration rest.port which is 8081 by default.
- Apache YARN: From the Web Ui of the YARN Resource Manager, find the application corresponding to the PyFlink job and then click the link under the “Tracking UI” column.
- Kubernetes: The Web UI may be exposed via any of the following: ClusterIP, NodePort and LoadBalancer. See the Kubernetes documentation for more details.
Architecture and Internals
Some background understanding may help you answer questions like:
- What’s the difference between Python API and Java API and which one should I use?
- How to use a custom connector in PyFlink?
- Where to find the logging messages printed in the Python user-defined functions?
- How to tune the performance of PyFlink jobs?
Note that we will not talk about basic Flink concepts here, for example the architecture of Flink, stateful streaming processing, event time and watermark which are described in detail in the official Flink documentation.
Architecture Diagram
PyFlink is composed of two main parts:
- Job compiling: Converts a PyFlink program into a JobGraph
- Job execution: Accepts a JobGraph and converts it into a graph of Flink operators which run in a distributed manner
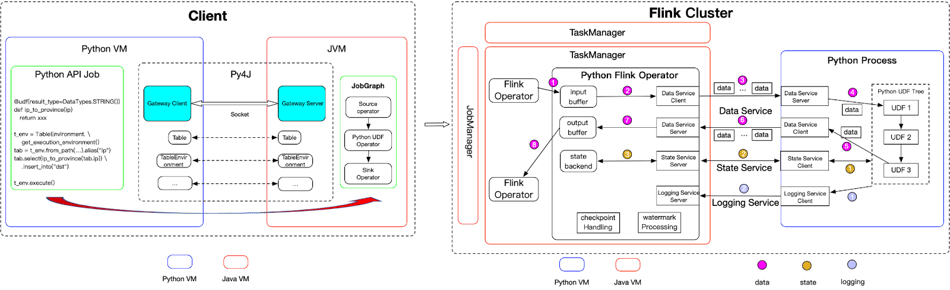
Architecture of PyFlink
Job compiling
Think of JobGraph as the protocol between a client and a Flink cluster. It contains all the necessary information to execute a job:
- A graph of transformations which represents the processing logic the user wants to perform
- The name and configuration of the job
- Dependencies required to execute the job, e.g. JAR files, Python dependencies, etc
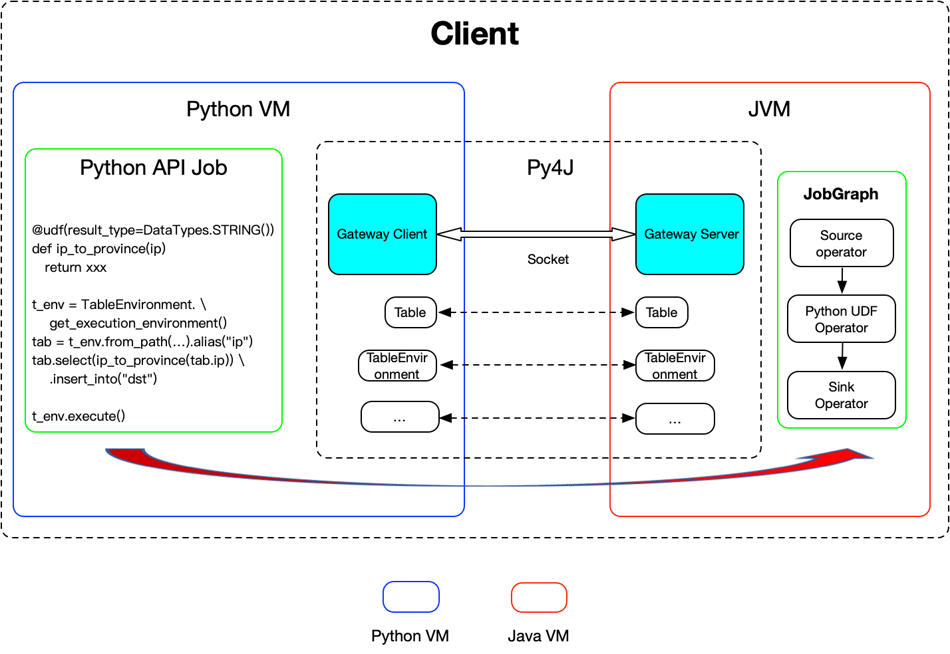
At present, there is no multiple language support for JobGraph, which only supports Java. PyFlink reuses the existing job compiling stack of the Java API by leveraging Py4J to enable Python programs running in a Python process to access the Java objects in a JVM.
Methods are called as if the Java objects resided in the Python process. Each Java API is wrapped by a corresponding Python API. When a Python program makes a PyFlink API call the corresponding Java object is created in the JVM and the method is called on it.
Internally it will create a corresponding Java object in JVM and then call the corresponding API on the Java object. So it reuses the same job compiling stack as the Java API.
This means that:
- If you use the PyFlink Table API but execute only Java code the performance should be just the same as the Java Table API
- If there is a Java class you want to use, e.g. custom connectors, that is not yet supported in PyFlink, you can just wrap it yourself
Job execution
Mostly, wrapping the Java API works well. However, there are some exceptional cases. Let’s look at the following example:
source = KafkaSource.builder() \
.set_bootstrap_servers("localhost:9092") \
.set_topics("input-topic") \
.set_group_id("my-group") \
.set_starting_offsets(KafkaOffsetsInitializer.earliest()) \
.set_value_only_deserializer(
JsonRowDeserializationSchema.builder()
.type_info(Types.ROW([Types.LONG(), Types.STRING()]))
.build()) \
.build()
env = StreamExecutionEnvironment.get_execution_environment()
ds = env.from_source(source, WatermarkStrategy.no_watermarks(), "Kafka Source")
ds.map(lambda x: x[1]).print()
env.execute()Here, all the Python methods can be mapped to Flink’s Java API except for map() which passes a lambda function ds.map(lambda x: x[1]). Java expects a Java MapFunction. To make this work in Java, we need to serialize lambda x: x[1] and wrap it with a Java wrapper object that spawns a Python process to execute it during job execution.
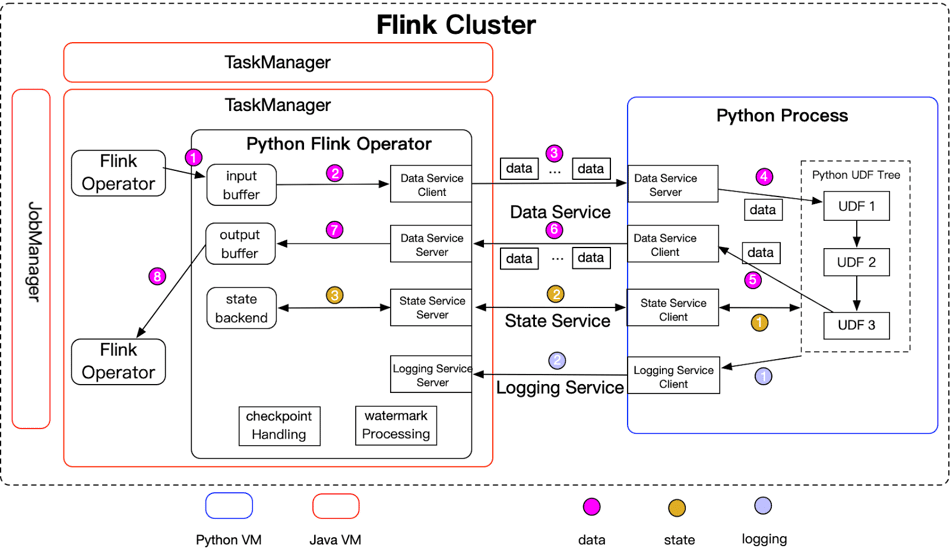
Flink and PyFlink Operators
During execution, a Flink job is composed of a series of Flink operators. Each operator accepts inputs from upstream operators, transforms them and produces outputs to the downstream operators. For transformations where the processing logic is Python, a specific Python operator will be generated:
- During initialization phase, the operator will spawn a Python process and send the metadata i.e. the Python functions to be executed, to the Python process
- After receiving data from upstream operators, the operator will send it to the Python process for execution. The data is sent to the Python process asynchronously; the operator doesn’t wait to receive the execution results for one data item before sending the next one.
- The operator supports access to the Python state, but the Python operator runs in the JVM. Unlike data communication, state access is synchronous. The state may be cached in the Python process to improve the performance.
- The Python operator also supports the use of logging in the Python functions. The logging messages are sent to the Python operator which runs in the JVM, and so the messages will finally appear in the log file of the TaskManagers.
Note that:
- The Python functions will be serialized during job compiling and deserialized during job execution. Keep resource usage light (see the notes on using open() above), and only use instance variables that are serializable.
- Multiple Python functions will be chained where possible to avoid unnecessary serialization/deserialization as well as communication overhead.
Thread Mode
Launching Python functions in a separate process works well in most cases, but again there are some exceptional cases:
- The additional serialization/deserialization and communication overhead can be a problem with large data e.g. image processing where the image size may be very large, long strings, etc.
- Inter-process communication also means the latency may be higher. Additionally the Python operator usually needs to buffer data to improve the network performance which adds more latency.
- The extra process and inter-process communication creates challenges for stability.
To address these problems, Flink 1.15 thread mode is introduced as an option for executing Python functions in the JVM. By default thread mode is disabled; to use it, configure python.execution-mode: thread.
With thread mode enabled, Python functions are executed very differently than in process mode:
- Data is processed one row at a time which increases latency.
- But, serialization/deserialization and communication overhead are removed.
Note that thread mode has specific limitations, which is why it’s not enabled by default:
- It only supports the CPython interpreter because it depends on the CPython runtime to execute Python functions.
- Because the CPython runtime can only be loaded once in a process, thread mode doesn’t support session mode well, where multiple jobs may need to use separate Python interpreters
See the blog post Exploring the thread mode in PyFlink for more details about thread mode.
State Access & Checkpoint
State access is supported for Python functions. This example uses state to calculate the average value of each group:
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment, RuntimeContext, MapFunction
from pyflink.datastream.state import ValueStateDescriptor
class Average(MapFunction):
def __init__(self):
self.sum_state = None
self.cnt_state = None
def open(self, runtime_context: RuntimeContext):
self.sum_state = runtime_context.get_state(ValueStateDescriptor("sum", Types.INT()))
self.cnt_state = runtime_context.get_state(ValueStateDescriptor("cnt", Types.INT()))
def map(self, value):
# access the state value
sum = self.sum_state.value()
if sum is None:
sum = 0
cnt = self.cnt_state.value()
if cnt is None:
cnt = 0
sum += value[1]
cnt += 1
# update the state
self.sum_state.update(sum)
self.cnt_state.update(cnt)
return value[0], sum / cnt
env = StreamExecutionEnvironment.get_execution_environment()
env.from_collection([(1, 3), (1, 5), (1, 7), (2, 4), (2, 2)]) \
.key_by(lambda row: row[0]) \
.map(Average()) \
.print()
env.execute()Here both sum_state and cnt_state are PyFlink state objects. States can be accessed during job execution and also recovered after job failover:
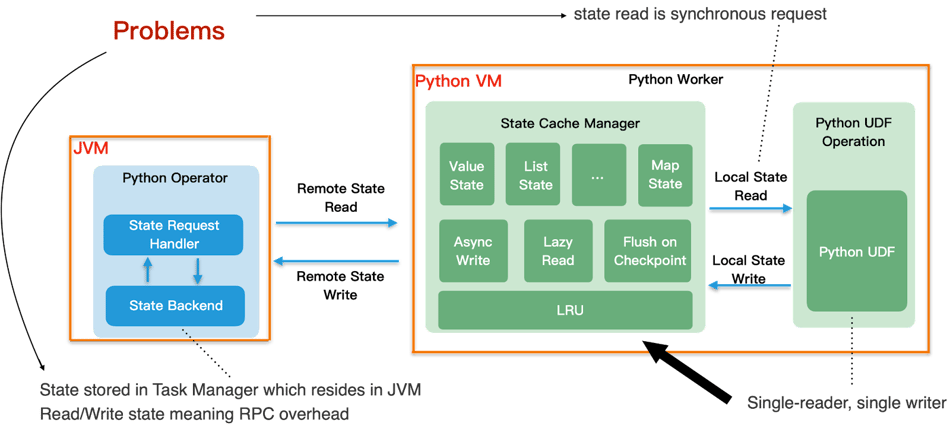
From the above diagram, we can see that:
- The source of truth for state is the Python Operator running in the JVM
- State access is synchronous from the user perspective
The following optimizations have been introduced to improve the performance of state access:
- Async write: Maintains a LRU cache of the latest states and state modifications which is written back to the Python Operator asynchronously
- Lazy read: As well as the LRU cache, MapState is read lazily to avoid unnecessary state requests
Performance Tuning
In general tuning PyFlink jobs is the same as tuning Flink Java jobs. One exception is tuning Python operator performance.
Memory Tuning
Python operators launch a separate Python process to execute Python functions. Python functions that depend on large resources can potentially occupy a lot of memory.If too little memory is configured for the Python process then the stability of the job will be affected.
If a PyFlink job is run in a Kubernetes or Apache YARN deployment which strictly limits memory usage, the Python process may crash because its memory requirement exceeds the limit.
You need to design your Python code carefully. Additionally, use the following configuration options to help tune Python memory usage:
- taskmanager.memory.process.size: Total process memory size for the TaskExecutors.
- taskmanager.memory.managed.fraction: Fraction of total memory to be used as managed memory. (Memory of Python process is also part of managed memory)
- taskmanager.memory.jvm-overhead.fraction: Fraction of total memory to be reserved for JVM Overhead. (Reserved memory which is not used explicitly)
- taskmanager.memory.managed.consumer-weights: Managed memory weights for different kinds of consumers. This configuration can be used to adjust the fraction of managed memory allocated to the Python process.
Bundle Size
In process mode, the Python operator sends data to the Python process in batches. To improve network performance it buffers data before sending it.t.
During a checkpoint, it must wait before all the buffered data is processed. If there are many elements in a batch and the Python processing logic is inefficient then the checkpoint time will be extended. If you notice very long or even failed checkpoints, try tuning the bundle size configuration python.fn-execution.bundle.size.
Execution Mode
Thread mode can improve performance in cases where the data size is large or when you need to reduce latency. Set configuration python.execution-mode: thread to enable it.
What’s Next for PyFlink
PyFlink already has rich functionality. In the next phase of its evolution the community focus will be on:
- Better support for interactive programing, e.g. retrieving only the few leading rows of an unbounded table.
- Improved ease of use, e.g. make the API more Pythonic, improve the documentation, and add more examples.

You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
