














This blog post will guide you through the Kafka connectors that are available in the Flink Table API. By the end of this blog post, you will have a better understanding of which connector is more suitable for a specific application.
Flink DataStream API provides Kafka connector, which works in append mode and can be used by your Flink program written in the Scala/Java API. Besides that, Flink has the Table API which offers two Kafka connectors:
- Kafka - unbounded source, uses "append mode” for sink
- Upsert Kafka - unbounded source, uses “upsert mode” for sink
This blog post will exclusively concentrate on Kafka connectors for the Table API. I will also attempt to answer the question of when to use a Kafka connector (append) or opt for an Upsert Kafka connector.
Simple Kafka Connector - Append Mode
The following example is copying data from a generated in-memory data stream to an output Kafka topic. In production scenarios, input data can be enriched or aggregated, but we are going to keep this example simple to show Flink’s behavior when it uses the first Kafka connector.
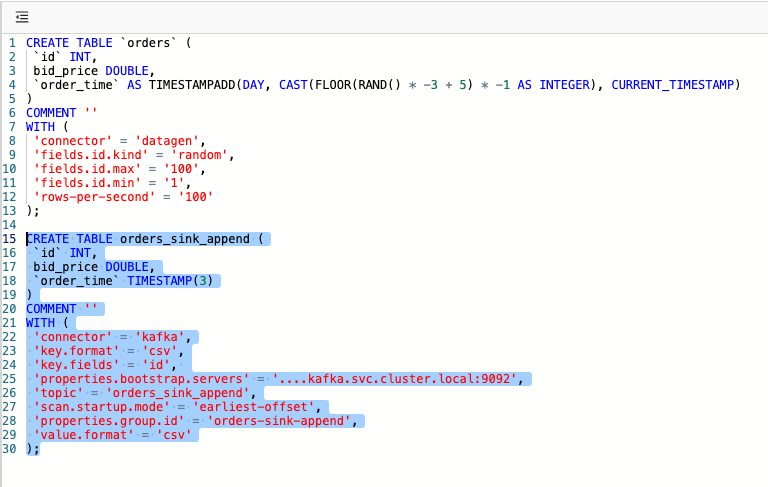
First, create a table with orders as a source of streaming data that are generated by the datagen connector:
CREATE TABLE `orders` (
`id` INT,
bid_price DOUBLE,
`order_time` AS TIMESTAMPADD(DAY, CAST(FLOOR(RAND() * -3 + 5) * -1 AS INTEGER), CURRENT_TIMESTAMP)
)
COMMENT ''
WITH (
'connector' = 'datagen',
'fields.id.kind' = 'random',
'fields.id.max' = '100',
'fields.id.min' = '1',
'rows-per-second' = '100'
);Then, create an output table as a sink to store input data with the kafka connector:
CREATE TABLE orders_sink_append (
`id` INT,
bid_price DOUBLE,
`order_time` TIMESTAMP(3)
)
COMMENT ''
WITH (
'connector' = 'kafka',
'key.format' = 'csv',
'key.fields' = 'id',
'properties.bootstrap.servers' = '....kafka.svc.cluster.local:9092',
'topic' = 'orders_sink_append',
'scan.startup.mode' = 'earliest-offset',
'properties.group.id' = 'orders-sink-append',
'value.format' = 'csv'
);In order to run all Flink code examples in this post, you will need to use Ververica Platform (VVP), which can be easily installed on any Kubernetes cluster:
- VVP Documentation: Installation
- Getting Started with Ververica Platform on Google Kubernetes Engine
- Getting Started with Ververica Platform on Azure Kubernetes Service
- How to get started with Ververica Platform on AWS EKS
Execute above table DDLs to register new tables in VVP’s built-in catalog. This can be done by opening VVP -> SQL -> Editor window. Then select every “CREATE TABLE … ;” statement separately and click “Run Selection” on the right hand-side.
Now we can create and start a Flink SQL Deployment in VVP with the following SQL script. It will store the generated data stream continuously to a Kafka topic with Kafka connector, i.e., running in the append mode. Run below SQL query by selecting it and clicking “Run Selection”.
INSERT INTO orders_sink_append SELECT * FROM orders;VVP will take you through the new VVP Deployment process. Just follow it and click the Start button.
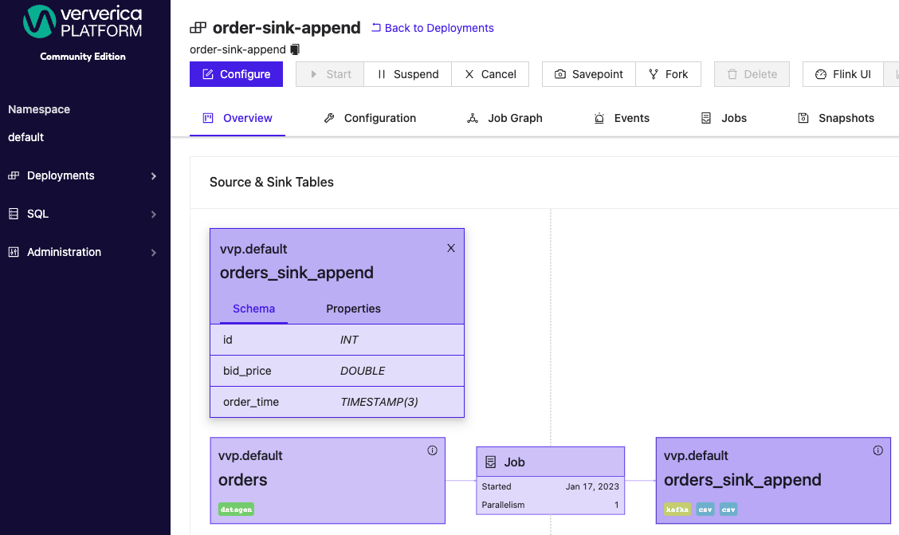
Here is the overview of the VVP Deployment created from the SQL query above:
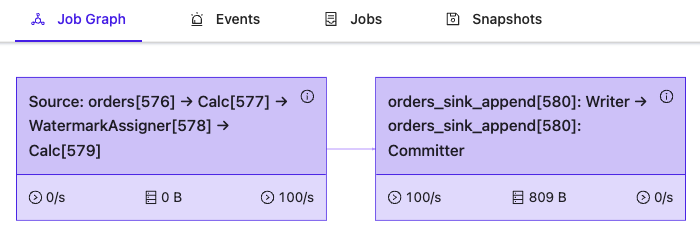
and the Job Graph:
Let’s check how the output from orders_sink_append topic/table looks like:
SELECT * FROM orders_sink_append;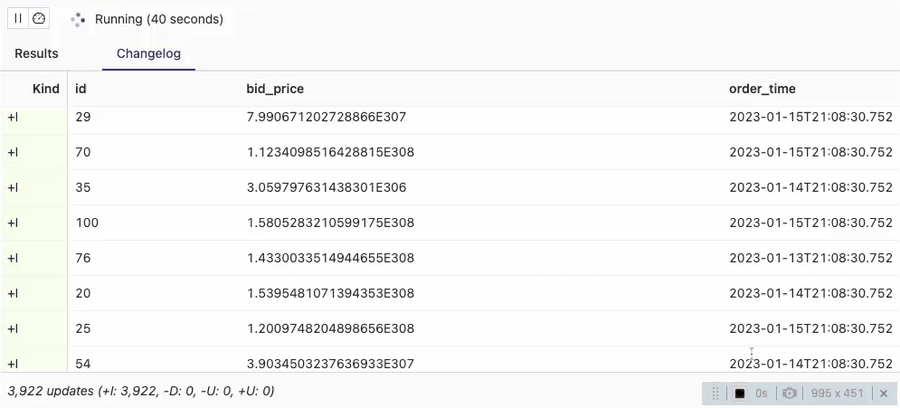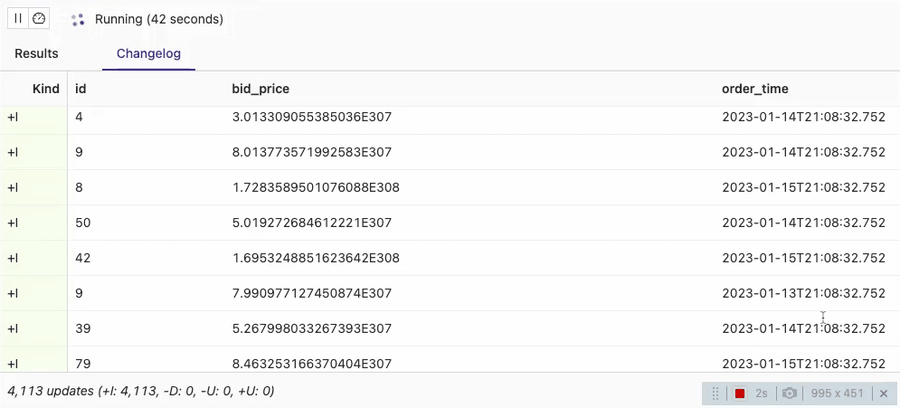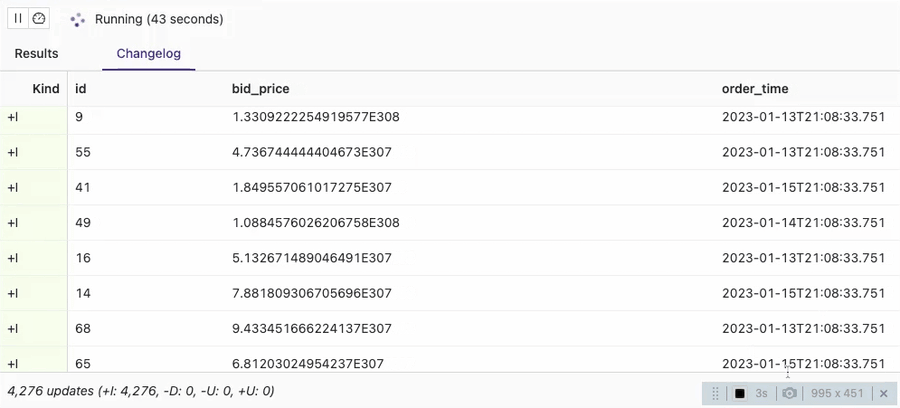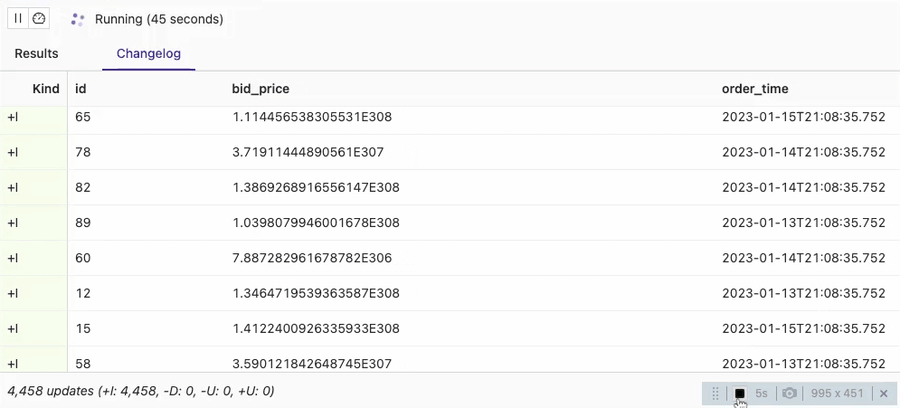
You can see that the client session in the VVP SQL Editor identifies all the data in the table with Kafka connector as Inserts (note +I in the Kind column). It implies that consumers should treat all the input data as appends.
To fulfill a business requirement of obtaining the most recent value for each key, consumers must use deduplication/grouping logic per order_id. This can be done by an external program which does this in memory, as well as by another Flink job which would group records by order_id and sort them over order_time using it as event time. So there are a couple options which could be applied further to get the latest bid_price per order_id.
Kafka Connector - Upsert Mode
Let’s look at another connector and what it makes different.
The input table definition stays the same, but the sink connector is set to “upsert-kafka”. For clarity, let’s create a clone table with the “upsert-kafka” connector.
CREATE TABLE orders_sink_upserts (
`id` INT,
bid_price DOUBLE,
`order_time` TIMESTAMP(3),
PRIMARY KEY (`id`) NOT ENFORCED
)
COMMENT ''
WITH (
'connector' = 'upsert-kafka',
'key.format' = 'csv',
'properties.bootstrap.servers' = '....kafka.svc.cluster.local:9092',
'topic' = 'order_upserts',
'properties.group.id' = 'order-upserts-consumers',
'value.format' = 'csv'
);Similar to the previous section, we create another VVP Deployment to store data into the table orders_sink_upserts with the “upsert-kafka” connector and the following SQL statement
INSERT INTO orders_sink_upserts SELECT * FROM orders;The overview of the VVP deployment and the job graph looks similar as before:
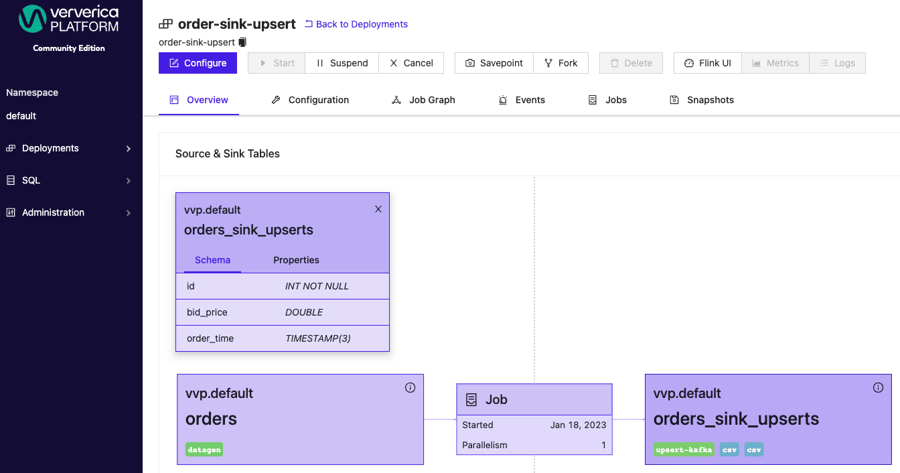
Topology of the Flink Job graph remains the same:
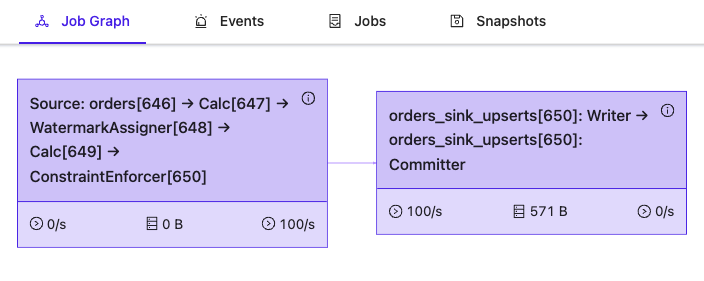
Below, you will find the output from orders_sink_upsert topic/table:
SELECT * FROM orders_sink_upsert;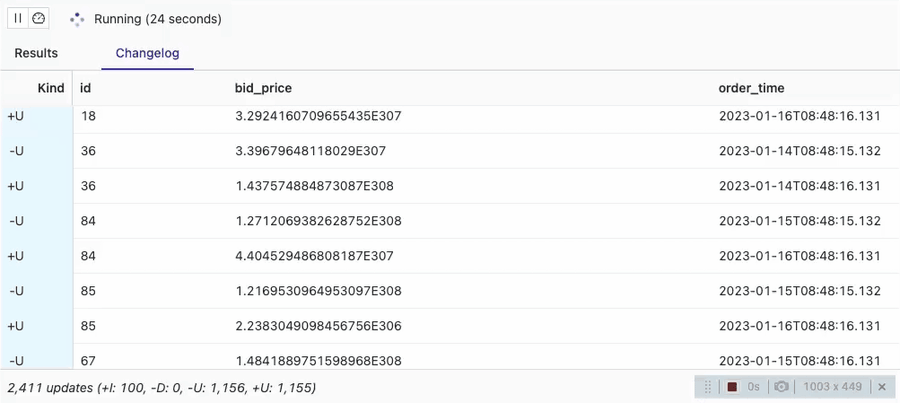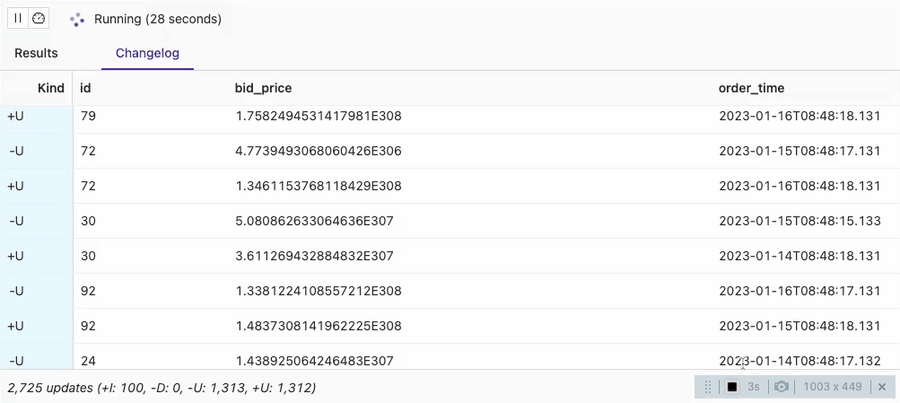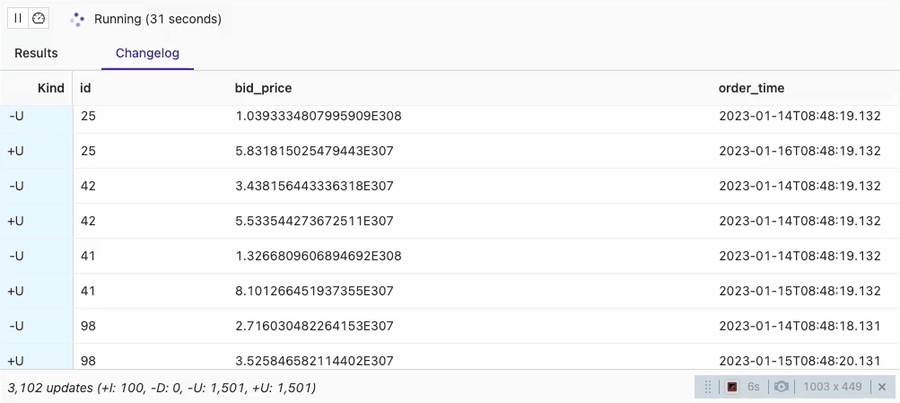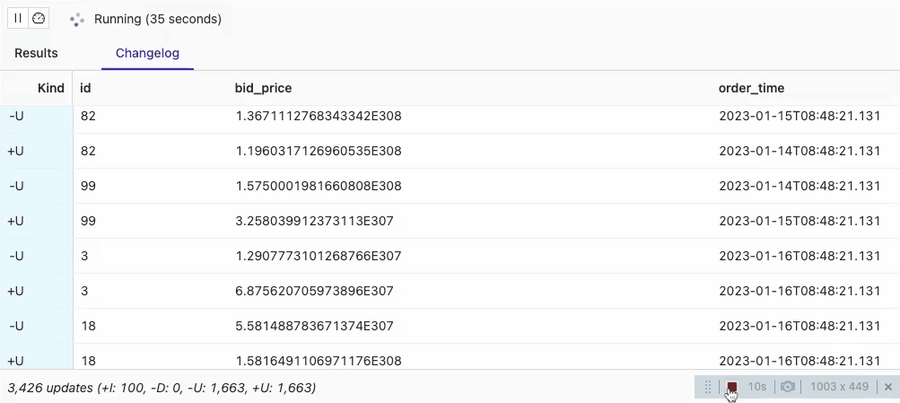
You can see that the VVP SQL Editor session is showing 100 Inserts (-I) and then the rest of the changes are Updates (+U, -U). There are 100 unique order Ids configured in datagen. That is the reason for getting 100 inserts only here and all the rest are updates to those 100 unique orders.
This is the main difference between the two streaming modes “append” and “upsert”, when you are working with a Kafka backed SQL table. Upsert mode makes it easy to get either the latest changes or understand whether streaming data is new or should be treated as an update or deletion. Deletion would be detected when any value for a specific key is NULL.
How does “upsert-kafka” detect the upserts? First of all, any Table using “upsert-kafka” connector must have a primary key. In case of the example above, it is:
PRIMARY KEY (`id`) NOT ENFORCEDYou can also see that Flink injects one more operator “ChangeLogNormalize'' when consuming data from the “upsert-kafka” table. Injected operator aggregates input data and returns the latest record for a specific primary key. Below is one more VVP Deployment to show this effect. It prints the data from upsert table to the standard output:
CREATE TEMPORARY TABLE SinkTable WITH ('connector' = 'print') LIKE orders_sink_upserts (EXCLUDING OPTIONS);
INSERT INTO SinkTable SELECT * FROM orders_sink_upserts;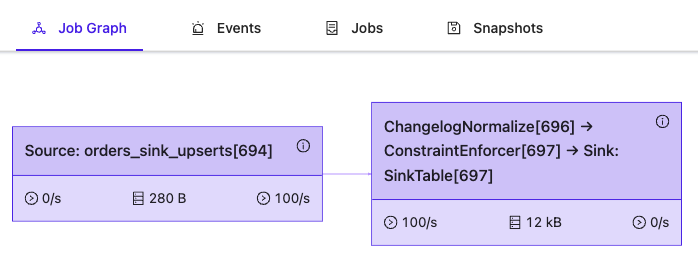
In contrast, if you read data from table orders_sink_append where the kafka connector works in the append mode, Flink does not inject ChangelogNormalize operator into the job graph:
CREATE TEMPORARY TABLE SinkTable
WITH ('connector' = 'print')
LIKE orders_sink_append
(EXCLUDING OPTIONS);
INSERT INTO SinkTable SELECT * FROM orders_sink_append;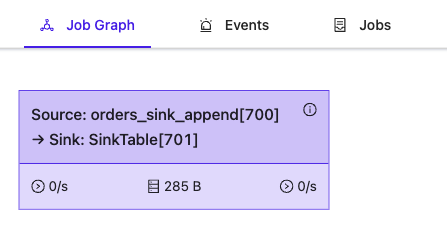
Join tables: upsert vs. append mode
The two different streaming modes make a big difference when multiple tables are joined together. This difference may lead to data duplication. The following example is showing how to avoid data duplication when joining two Flink tables backed by Kafka topics. Here is an example Flink SQL job about Taxi rides. We have a registry of cars, each has a carClass “Blue” or “Black” in the first table. Hypothetically, each car class has its own ride rate. The second table contains car assignments across New York City boroughs (Brooklyn, Queens, etc.). As cars move, an assignment event is generated and transmitted to our streaming pipeline. This allows us to keep track of the changing location of the cars. Ultimately, the business goal is to answer the question which cars are currently assigned to a particular borough.
Below are minimized table DDLs to get an idea of table schemas, full definitions are defined further:
CREATE TABLE `cars` (
`carId` INT NOT NULL,
`carClass` VARCHAR(50)
)...
CREATE TABLE `assignments` (
`carId` INT NOT NULL,
`borough` VARCHAR(50)
)...Business query:
SELECT
borough, carClass, collect(carId) AS carIds
FROM (
SELECT c.carId, borough, carClass
FROM cars c JOIN assignments a
ON c.carId = a.carId
)
GROUP BY borough, carClass;Using Append Mode
First, look at the append mode. When joining append-based tables you may end up with duplicates unless you apply deduplication logic as part of the business logic. Duplicates arise when a car changes its borough, i.e. the same car Id over the time may have different borough assigned.
Append mode sink table:
CREATE TABLE cars (
carId INT NOT NULL,
carClass VARCHAR(50)
) WITH (
'connector' = 'kafka',
'key.format' = 'csv',
'key.fields' = 'carId',
'properties.group.id' = 'sample-group-cars',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = '....kafka.svc.cluster.local:9092',
'topic' = 'cars',
'value.format' = 'csv'
);
CREATE TABLE assignments (
carId INT NOT NULL,
borough VARCHAR(50)
) WITH (
'connector' = 'kafka',
'key.format' = 'csv',
'key.fields' = 'carId',
'properties.group.id' = 'sample-group',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = ....kafka.svc.cluster.local:9092',
'topic' = 'assignments',
'value.format' = 'csv'
);Set your own Kafka servers in properties.bootstrap.servers property, if you want to try this example yourself.
Next, let’s define, another SQL script to generate data and store into both tables:
CREATE TEMPORARY TABLE assignments_log (
carId INT NOT NULL,
borough VARCHAR(50)
) WITH (
'connector' = 'faker',
'rows-per-second' = '1',
'fields.carId.expression' = '#{number.numberBetween ''1'',''10''}',
'fields.borough.expression' = '#{regexify ''(Brooklyn|Queens|Staten Island|Manhattan|Bronx){1}''}'
);
BEGIN STATEMENT SET;
INSERT INTO cars VALUES
(1, 'Blue'), (2, 'Black'), (3, 'Premium'),
(4, 'Blue'), (5, 'Black'), (6, 'Premium'),
(7, 'Blue'), (8, 'Black'), (9, 'Premium');
INSERT INTO assignments SELECT * FROM assignments_log;
END;Running the business query you defined earlier:
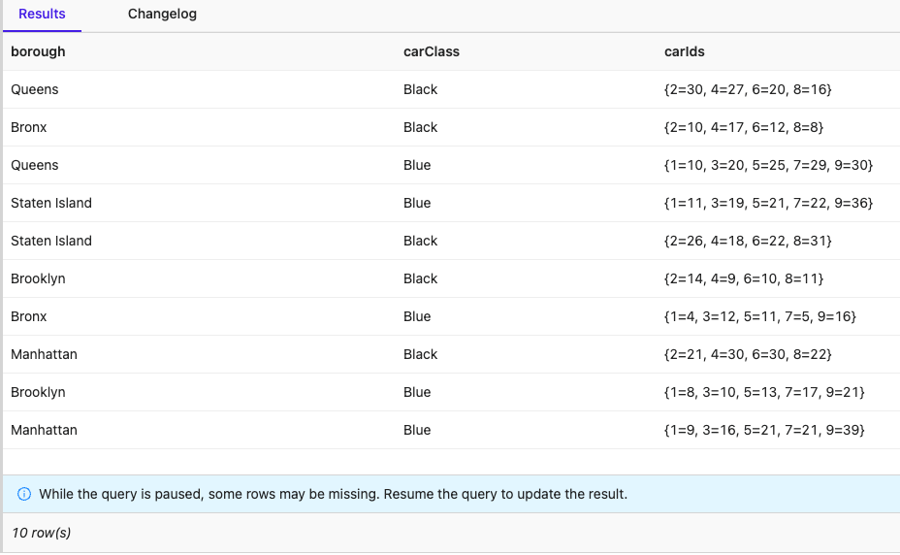
You can see a problem here. Why is the same car (id = 1 or 2) assigned to multiple boroughs as it should be assigned to a single borough at a time?
Investigation
Aggregation function “collect” returns a multiset, which contains key value pairs. Each key is the value from the respective table column (i.e., carId). Each value in the pair is a number of occurrences for that key. A multiset “{1=27, 3=56}” for the Staten Island borough means a car with an id equal to ‘1’ is assigned 27 times and carId with id ‘3’ is assigned 56 times in the Staten Island borough. That means that the same car exists in 27 places at the same time, which is not possible as long as we are in the same universe 😂. Taxi cars are unique, they have unique ids. We want to see where a particular car is assigned at the current moment. In order to solve this, we can deduplicate assignment events based on a time attribute, which needs to be added. Official “Deduplication” recipe from Flink documentation can be applied too. However, we can solve this problem without manual deduplication, by just using “upsert-kafka” tables instead.
Using Upsert Mode
Let’s re-create the input tables with the upsert-kafka connector:
CREATE TABLE assignments (
carId INT NOT NULL,
borough VARCHAR(50),
PRIMARY KEY (carId) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'key.format' = 'csv',
'properties.group.id' = 'sample-group',
'properties.bootstrap.servers' = '....kafka.svc.cluster.local:9092',
'topic' = 'assignments',
'value.format' = 'csv'
);
CREATE TABLE cars (
carId INT NOT NULL,
carClass VARCHAR(50),
PRIMARY KEY (carId) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'key.format' = 'csv',
'properties.group.id' = 'sample-group-cars',
'properties.bootstrap.servers' = '....kafka.svc.cluster.local:9092',
'topic' = 'cars',
'value.format' = 'csv'
);Finally, let’s run the same business query. This time, you get desired car assignments in real time:
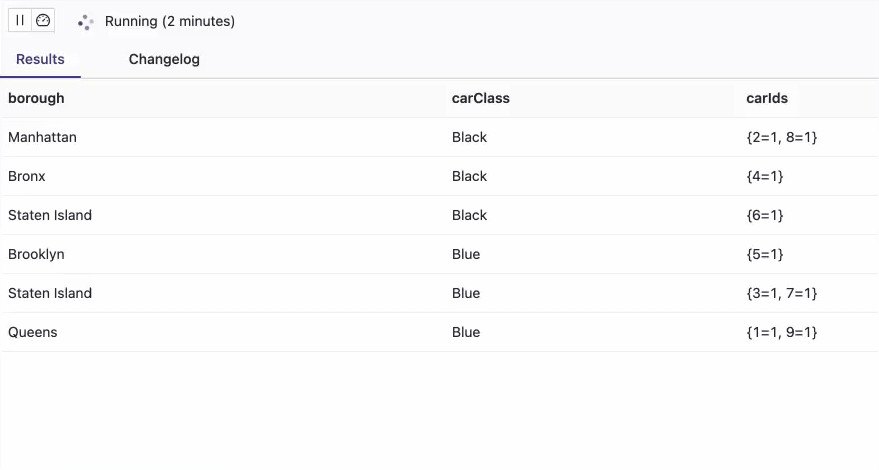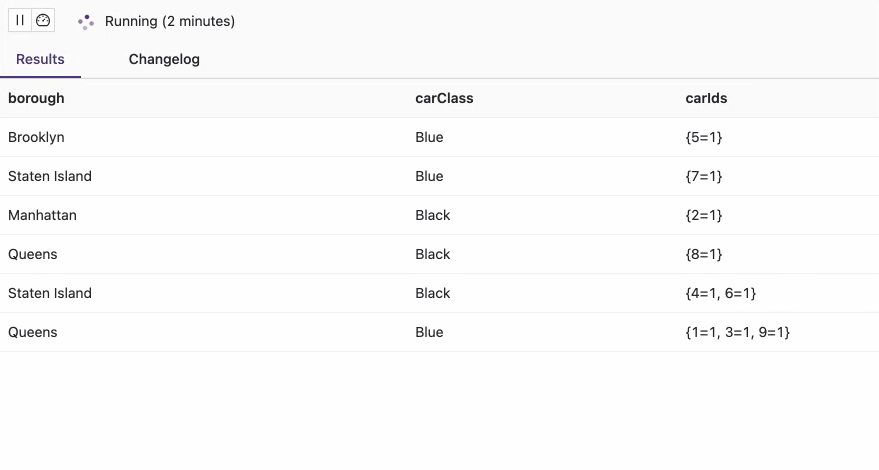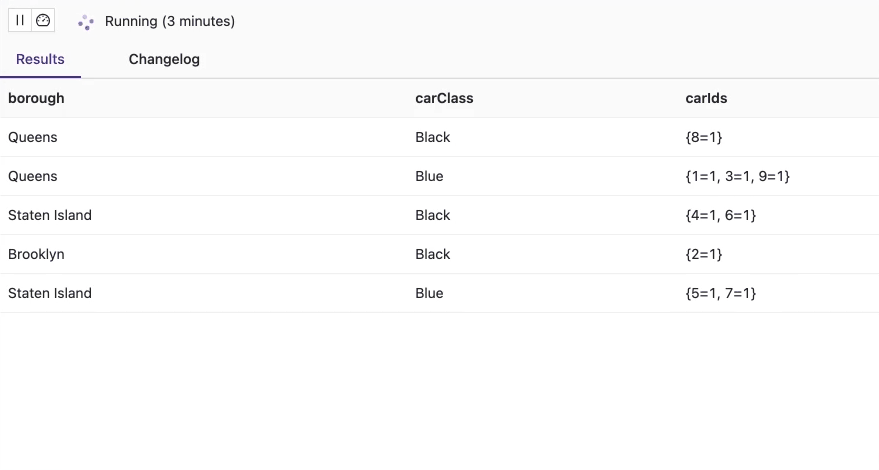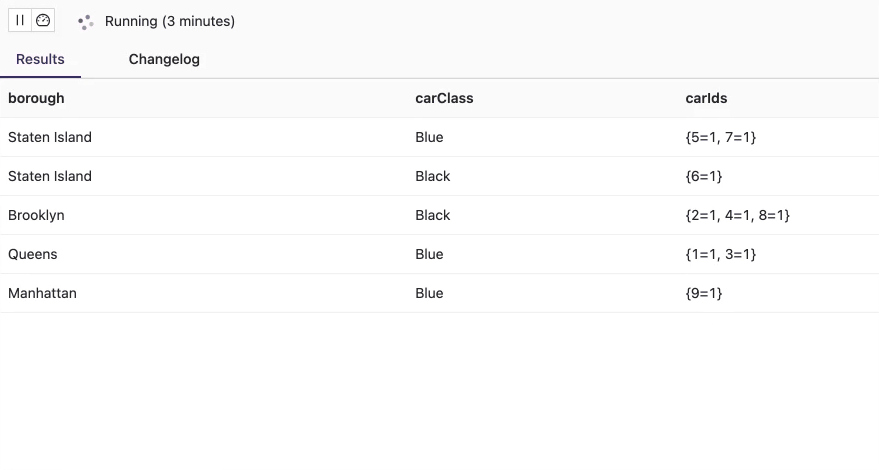
There are no cars (car ids) which exist more than one time at any given borough. Above animation is recorded within 12 seconds. Every second, you get a migration of one of the cars to another borough which makes real sense, as a new event is generated and sent to the “assignment” table/topic per second. The values in the multiset are always equal to 1, which is another test case that proves the query’s correctness.
Below is the Job Graph for the business query using tables that are backed by the upsert-kafka connector:
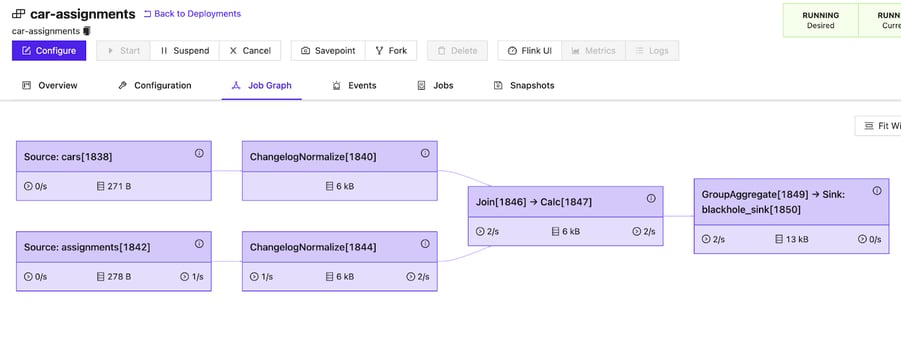
Both input tables are first normalized before they are joined by the join operator.
Summary
The Kafka connector in Flink SQL can work in two streaming modes. Upsert mode allows us to get the latest value for a specific entity automatically without any manual deduplication. One of the typical scenarios where you can leverage this mode is a SQL join of two tables, where one of the tables is keeping history of changes per some entity id. Once you join on such an entity id which is non-unique by design, you get unwanted rows, but you usually want to see the latest value of that entity. With upsert mode, Flink automatically normalizes before the tables are joined. Eventually it allows you to easily answer typical business questions on getting a real-time view of the shared resources like cars, planes, workers, etc.
Append mode is still an option to go with, if a business query does not need to filter out all historical events, but rather show the history of changes at the end. In this scenario, query may run faster with append mode, as Flink does not need to do any changelog normalization.

You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
