













Flink SQL is a powerful tool which unifies batch and stream processing. It provides low-code data analytics while complying with the SQL standard.
In production systems, our customers found that as the workload scales, the SQL jobs that used to work well may slow down significantly, or even fail. And data skews is a common and important reason.
Data skew refers to the asymmetry of the probability distribution of a variable about its mean. In other words, the data is unevenly distributed in terms of some attributes. This article discusses and analyzes the implications of data skews to stream joining for aggregation-related cases, and the potential solutions.
If you are new to this field, or interested in learning more about Flink or Flink SQL, please check out the Related Information at the end of this article too.
Joining with a Stream Having Key Skews
Consider the following scenario: we have a Users table which contains information about users of some business application. And we have a GenOrders table which contains information about orders (buy/sell something). We would like to know the number of orders per user in the Users table. The (simplified) query may look like the following:
CREATE TABLE `Users` (
`uid` BIGINT,
`name` STRING,
`country` STRING,
`zcode` STRING
)
WITH (
-- Details are skipped.
);
CREATE TEMPORARY TABLE `GenOrders` (
`uid` BIGINT,
`oid` BIGINT,
`category` STRING,
`price` DECIMAL(3, 2)
)
COMMENT ''
WITH (
'connector' = 'datagen',
'fields.price.max' = '99',
'fields.price.min' = '1',
'rows-per-second' = '1',
'number-of-rows' = '100000'
);
SELECT o.uid, COUNT(o.oid)
FROM GenOrders o
JOIN Users u ON o.uid = u.uid
GROUP BY o.uid;In the context of stream joining, it is important to understand that both tables represent continuous flows of information. In Flink, aggregations (such as COUNT and SUM) are performed by aggregation operators. An aggregation operator is a stateful operator, which stores the intermediate aggregate results in its state. By default, the streaming aggregation operators process input records one by one. When a record comes in, the operator goes through the following steps: (1) retrieve the accumulator from the state, (2) accumulate/retract the record to the accumulator, and (3) store the accumulator back to the state.
Each read/write of the state comes with a certain cost.
Data Skew
And in large scale Flink applications, the streams are often divided based on specific keys, and distributed into multiple tasks for parallel processing. We refer to such a key as a “Grouping Key”. If the distribution of records is uneven, then some tasks would be heavier than others. And the heavier tasks take longer to complete, and can potentially become the bottlenecks of the data pipeline. When this happens, we say that the data is skewed. Furthermore, if the data is distributed based on some keys, we refer to it as “key skew”.
For the above use case, we can distribute the records by user ID to aggregation tasks for parallel processing. Since we are looking for the number of orders per user, it makes sense to group the data by user ID.
In the graph below, we use colors to indicate data records for different users. We can see that the Red user has 8 records, which is considerably more than other users’. In this case, we say that the data is skewed on user ID. If we distributed the data by user ID, the top aggregation task which processes Red records, would process more data, and would likely take longer than others.
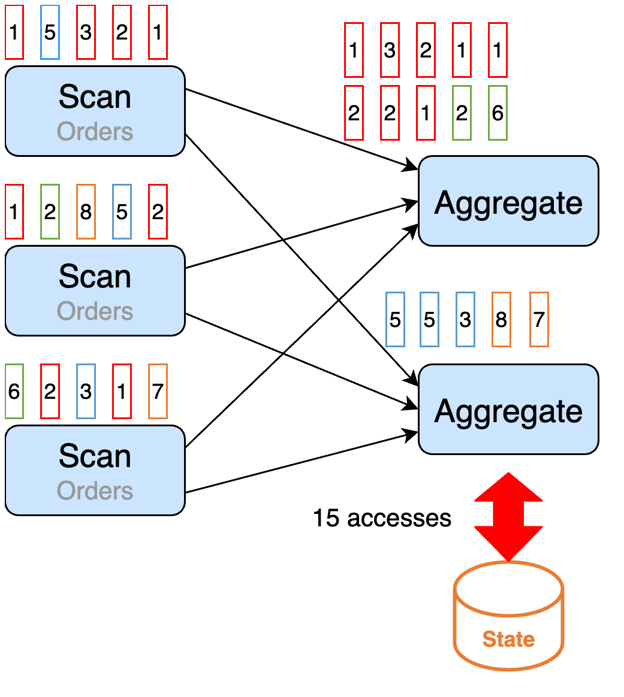
How to deal with it?
MiniBatch Aggregation
MiniBatch Aggregation puts the input records into a buffer and does the aggregation operation after the buffer is full or after some time. This way, the records with the same key value (value for the key) in the buffer are processed together, so we only have one state write per key value per batch.
MiniBatch Aggregation boosts the throughput as aggregation operators have fewer state accesses, and output fewer records, especially when there are retraction messages and the performance of downstream operators is suboptimal.
The following graph demonstrates it.
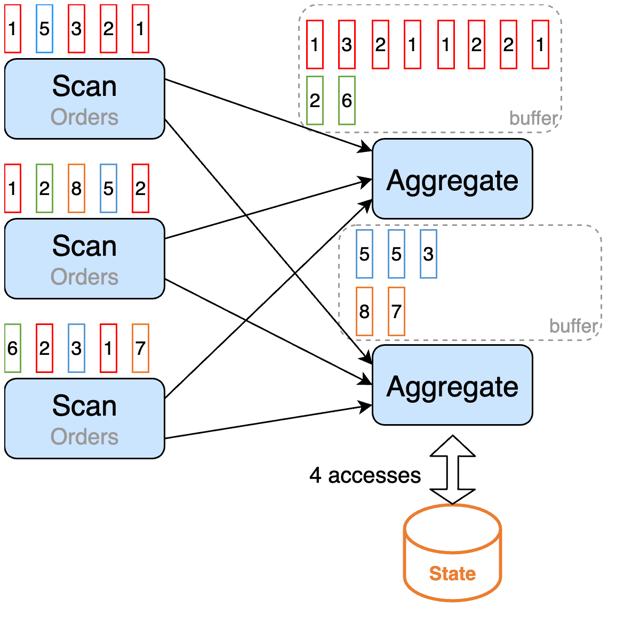
We can use the following options to implement it:
table.exec.mini-batch.enabled: true # Enable mini-batch
table.exec.mini-batch.allow-latency: 5s # Put the records into a buffer and do an aggregation within 5 seconds
table.exec.mini-batch.size: 10000 # [Optional] The maximal number of input records that can be buffered for MiniBatchCaution: The downside of MiniBatch is that it increases latency, because the aggregation operators start processing the records when the buffer is full or when the buffer times out, rather than processing them immediately.
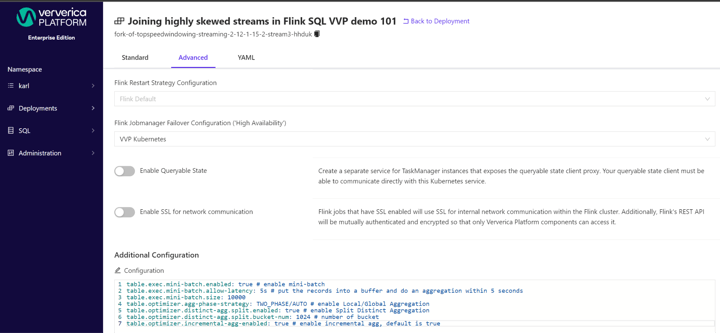
How to implement it in Ververica Platform
To learn how to create and deploy Flink SQL jobs in Ververica Platform, please go to Getting Started - Flink SQL on Ververica Platform in Ververica Platform Documentation.
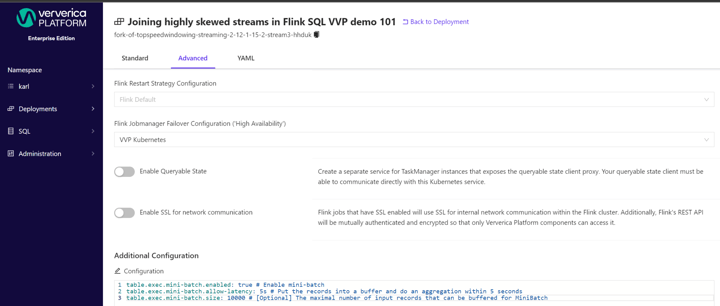
To implement the discussed techniques in Ververica Platform Web UI,
- Go to Deployments
- Click the job that you would like to apply the techniques to
- Click Configure button
- Click Advanced tab
- Set the options in Additional Configuration
As demonstrated below:
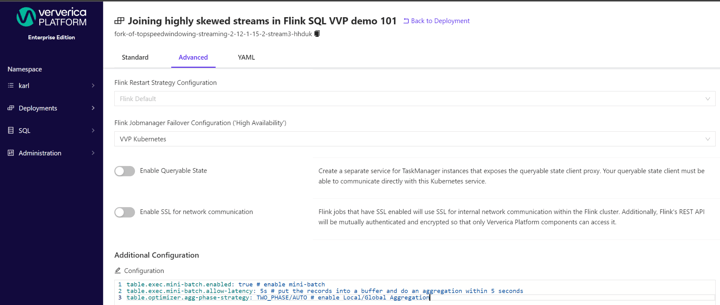
Local/Global Aggregation
In the above example, the first aggregation task (also known as the “hot” task) processes more data than the other, because of the key skew, and becomes a bottleneck. If each upstream task can aggregate the records for each key value before sending them to the aggregation tasks, then the aggregation tasks will receive much fewer records per key value, and thus reduce the load of the “hot” task. This technique is called Local/Global Aggregation.
The following graph demonstrates it.
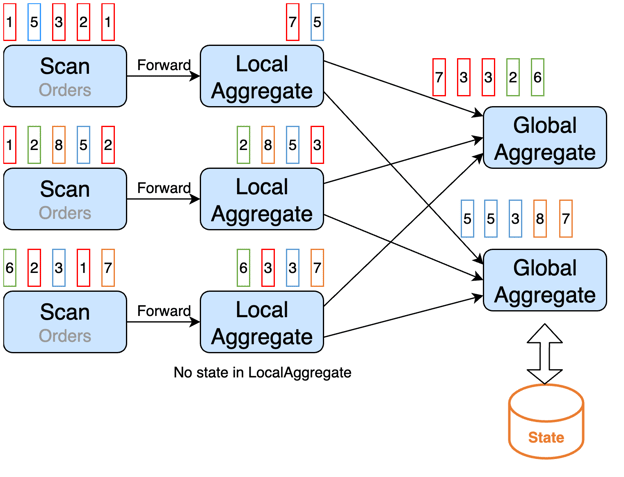
We do not maintain state for the local aggregations, so that we can avoid the cost of the state accesses there, and bear the cost only in global aggregations.
We can use the following options to implement it together with MiniBatch:
table.exec.mini-batch.enabled: true # enable mini-batch
table.exec.mini-batch.allow-latency: 5s # put the records into a buffer and do an aggregation within 5 seconds
table.optimizer.agg-phase-strategy: TWO_PHASE/AUTO # enable Local/Global AggregationNote: All aggregation functions in a query must implement the merge method in order for the query to leverage Local/Global Aggregation. Many built-in functions support Local/Global Aggregation, such as COUNT, MAX, MIN, SUM and AVG.
How to implement it in Ververica Platform
Please follow the instructions in the section How to implement it in Ververica Platform under MiniBatch Aggregation.
As demonstrated below:
Joining with a Stream Having Distinct Key Skews
Consider the same Users table and GenOrders table, this time we would like to know the number of distinct categories for each user. The (simplified) query may look like the following:
CREATE TABLE `Users` (
`uid` BIGINT,
`name` STRING
)
WITH (
-- Details are skipped.
);
CREATE TEMPORARY TABLE `GenOrders` (
`uid` BIGINT,
`oid` BIGINT,
`category` STRING,
`price` DECIMAL(3, 2)
)
COMMENT ''
WITH (
'connector' = 'datagen',
'fields.price.max' = '99',
'fields.price.min' = '1',
'rows-per-second' = '1',
'number-of-rows' = '100000'
);
SELECT o.uid, COUNT(DISTINCT o.category)
FROM GenOrders o
JOIN Users u ON o.uid = u.uid
GROUP BY o.uid;If we have many distinct values for the user-category combination, then some aggregation tasks may produce many records. We refer to it as “distinct key skew”.
The following graph demonstrates it.
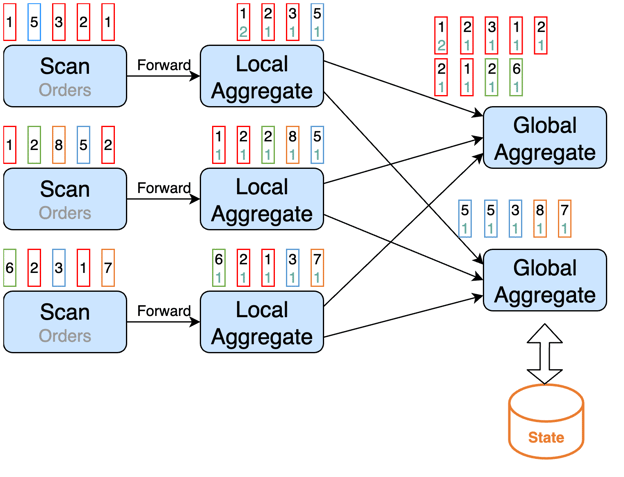
And Local/Global Aggregation cannot solve this problem. How to deal with it?
Split Distinct Aggregation
We can split the aggregation into two phases. First, we divide the records into buckets, based on the grouping key and a bucket key. The bucket key is the hash code of the distinct key modulo the number of buckets, i.e.
Bucket_Key = HASH_CODE(distinct_key) % NUMBER_OF_BUCKETS
Then we aggregate each bucket in parallel into partial results (first phase aggregation / partial aggregation). We divide the partial results based on the grouping key, and aggregate them into final results (second phase aggregation / final aggregation). This technique is called Split Distinct Aggregation.
The following graph demonstrates it.
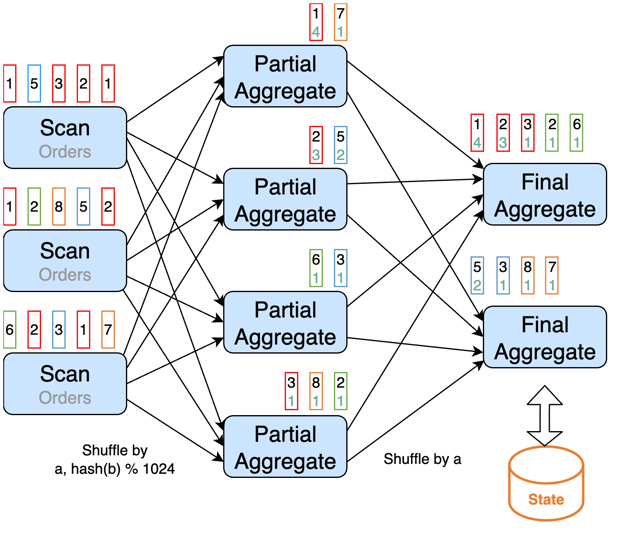
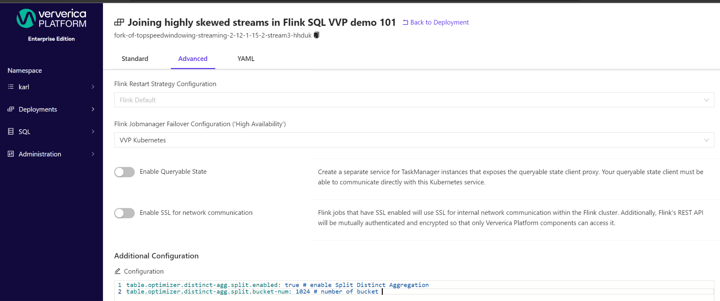
We can use the following options to implement it:
table.optimizer.distinct-agg.split.enabled: true # enable Split Distinct Aggregation
table.optimizer.distinct-agg.split.bucket-num: 1024 # number of bucketNote: All aggregate functions in the query must be built-in aggregation functions and must be splittable, e.g. AVG, SUM, COUNT, MAX, MIN, in order for the query to leverage Split Distinct Aggregation.
Caution: Split Distinct Aggregation has the overhead of state access and stream shuffling for the partial aggregation. Hence we do not recommend it if there is no distinct key skew or when the input data set is small.
How to implement it in Ververica Platform
Please follow the instructions in the section How to implement it in Ververica Platform under MiniBatch Aggregation.
As demonstrated below:
Incremental Aggregation
The state for partial aggregations can potentially become large because of distinct key skews. One solution for that is to have three phases of aggregations. First, each upstream task does a local aggregation for each distinct key value. No state is maintained for local aggregations. Those results are divided by grouping key and bucket key, and sent to the second phase aggregation (called incremental aggregation). Incremental aggregation only stores the distinct keys in its state. The results of incremental aggregation are divided by grouping key, and sent to the third phase aggregation (final aggregation), which keeps the aggregation function values in the state.
This technique is called Incremental Aggregation.
The following graph demonstrates it.
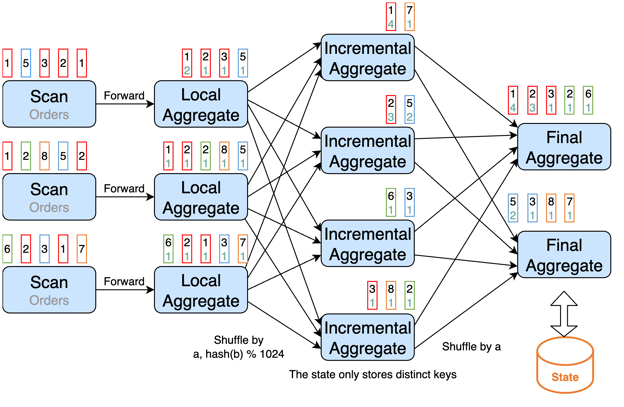
We can use the following options to leverage Incremental Aggregation, together with MiniBatch Aggregation, Local/Global Aggregation and Split Distinct Aggregation:
table.exec.mini-batch.enabled: true # enable mini-batch
table.exec.mini-batch.allow-latency: 5s # put the records into a buffer and do an aggregation within 5 seconds
table.exec.mini-batch.size: 10000
table.optimizer.agg-phase-strategy: TWO_PHASE/AUTO # enable Local/Global Aggregation
table.optimizer.distinct-agg.split.enabled: true # enable Split Distinct Aggregation
table.optimizer.distinct-agg.split.bucket-num: 1024 # number of bucket
table.optimizer.incremental-agg-enabled: true # enable incremental agg, default is trueNote: The query must support MiniBatch Aggregation, Local/Global Aggregation and Split Distinct Aggregation too. Please see the requirements for those optimizations in the corresponding sections of this article.
How to implement it in Ververica Platform
Please follow the instructions in the section How to implement it in Ververica Platform under MiniBatch Aggregation.
As demonstrated below:
Conclusion
We discussed key skews, distinct key skews, their implications to joins with aggregations, potential solutions, and how to implement them in Ververica Platform.
We will discuss this topic further in future articles. Stay tuned.
In case you are interested in learning more about Flink SQL, the following resources may help:
- Getting Started - Flink SQL on Ververica Platform
- Flink SQL Cookbook
- Flink Forward Talk: One SQL, Unified Analytics
- Only SQL: Empower data analysts end-to-end with Flink SQL
- The official Flink SQL documentation
We strongly encourage you to try your queries in Ververica Platform. The installation is as simple as these steps.
Related Information
You may be interested in these articles too:
- Flink SQL: Window Top-N and Continuous Top-N
- Flink SQL: Joins Series 1 (Regular, Interval, Look-up Joins)
- Flink SQL: Joins Series 2 (Temporal Table Join, Star Schema Denormalization)
- Flink SQL: Joins Series 3 (Lateral Joins, LAG aggregate function)
- Flink SQL: Deduplication
- Flink SQL: Queries, Windows, and Time - Part 1
- Flink SQL: Queries, Windows, and Time - Part 2
- Flink SQL: Detecting patterns with MATCH_RECOGNIZE
Acknowledgements
Some graphs in the article are based on Godfrey He’s work for “How to write fast Flink SQL”.
You may also like

Introducing The Era of "Zero-State" Streaming Joins

Ververica Platform 3.0: The Turning Point for Unified Streaming Data

Introducing Apache Fluss™ on Ververica’s Unified Streaming Data Platform
