














Ufuk Celebi (@iamuce) is a co-founder and software engineer at data Artisans.
2016 was the year that stateful, event-time, and event-at-a-time stream processing arrived as the paradigm for high-throughput, low-latency, and accurate computations. Streaming has now been adopted by a wide range of organizations in production. So what comes next?
We believe that 2017 will be the year to realize the full potential of streaming application state. Streaming application state is the set of all variables that are updated when processing events. Keeping state reliably and consistently across the processing of individual events is what makes a streaming framework actually useful: it is required for all interesting operations, like windowing, joins, statistics, state machines, and so on. Apache Flink's support for streaming application state is already advanced: its checkpoint-based fault tolerance mechanism is lightweight and guarantees exactly-once semantics in the event of failure, and its savepoints feature makes it possible to deploy code updates without losing an application’s current progress.
State can be very large and can be updated event-time aware. However, there was always one issue with application state in Flink: it wasn’t available to external applications outside of the streaming framework. It was still necessary to send the result of a streaming computation to a database or key-value store to make it accessible for querying.
But that limitation of application state is being addressed. Apache Flink’s Queryable State, a new feature first introduced to Flink’s master branch in August 2016 and included in the version 1.2.0 release in February 2017, provides a turnkey mechanism for external access to application state and an API for submitting queries against this state.
Said another way, Flink itself can now provide access to real-time results of a computation, meaning that in some cases, it wouldn’t be necessary to send results to an external key-value store. Best of all: if you’re already using stateful operators or functions in your Flink programs (and you probably are), then making your state queryable and submitting queries requires minimal setup and overhead. We’ll go into more detail later in the post. In this post, we’ll look at a common use case under the lens of a stateful streaming architecture before and after Apache Flink’s Queryable State. Next, we’ll look at Queryable State as it’s implemented in Flink 1.2.0 along with some sample code.
1. A Use Case Walkthrough
2. A Stateful Streaming Architecture
3. Queryable State As The Real-time Access Layer
4. The Logical Conclusion: No External Key-Value Store
5. Queryable State in Flink 1.2.0: A Demo
6. Wrapping Up
A Use Case Walkthrough
Earlier this month, we published a guest post from Aris Koliopoulos of Drivetribe describing how their product has been built using Apache Flink. In case you missed that post, here’s some background: Drivetribe is a digital hub for motoring co-founded by the former hosts of Top Gear. Their user base consists of a number of different “Tribes”, which are topic-specific groups moderated and managed by the co-founders, by other bloggers and experts, or by motoring enthusiasts from the Drivetribe community. Tribe members can post their own content on the site and can also interact with posts from other users. Drivetribe explained how it uses Flink to compute metrics that are exposed to end users inside the product, such as impression counts, comment counts, “bump” counts (Drivetribe’s terminology for a “like”), and “bumps per day”. It’s a common and broadly-applicable use case--counting and exposing end-user-facing metrics, keyed by ID--and so we’ll think through the case in the context of a stateful streaming architecture in Flink both with and without Queryable State. In doing so, we’ll consider how Queryable State has the potential to provide even lower-latency access to results, and in some cases, to eliminate the need for an external key-value store altogether. Note that in its current form, Queryable State does not support querying windows. Adding this support requires only a straightforward addition to Flink’s DataStream API and is likely to be addressed in the near future. Therefore, we’re still going to walk through a use case that queries window state as we explain the feature. See the “Current Limitations” section further in the post for more detail.
A Stateful Streaming Architecture
First, we’ll look at the use case in Apache Flink without Queryable State: 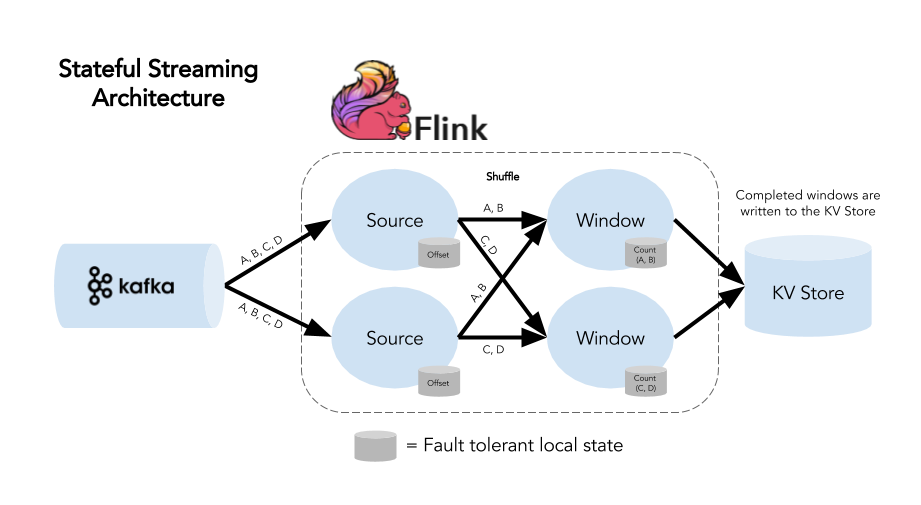 This diagram shows a Flink program that consumes user events (such as impressions, click counts, etc.) from Apache Kafka, counting by key (e.g. content ID), windowing counts on some time interval, then sending completed windows to a key-value store so the counts can be exposed to end users. State is stored locally within the application. A stateful streaming architecture provides us with:
This diagram shows a Flink program that consumes user events (such as impressions, click counts, etc.) from Apache Kafka, counting by key (e.g. content ID), windowing counts on some time interval, then sending completed windows to a key-value store so the counts can be exposed to end users. State is stored locally within the application. A stateful streaming architecture provides us with:
- Low latency: Flink’s performance ensures that our computation happens quickly and that we have fast access to completed windows.
- Fault tolerance: Flink’s checkpoints manage state locally within the application and ensure exactly-once semantics in the event of a failure. This means we can be confident that our results are accurate (no double-counting, no missing events) even when something goes wrong.
- Accuracy: Flink’s event time handling means that out-of-order data is windowed correctly based on when an event actually took place, not when it reaches our processing system. This is particularly important when dealing with delays due in upstream systems.
But there’s not a way for us to get to counts before a window is complete, and we still have to send completed windows to an external store. These are two points that should, in theory, be solvable. After all, we know that our counts exist inside the Flink application in the form of application state. We just need a way of getting to them.
Queryable State As The Real-time Access Layer
Flink’s Queryable State provides access to application state inside of Flink, and in this use case, it provides a way to get to in-flight aggregates so that we can have updated counts before a window is complete. Here’s what our streaming architecture with the addition of Queryable State might look like. 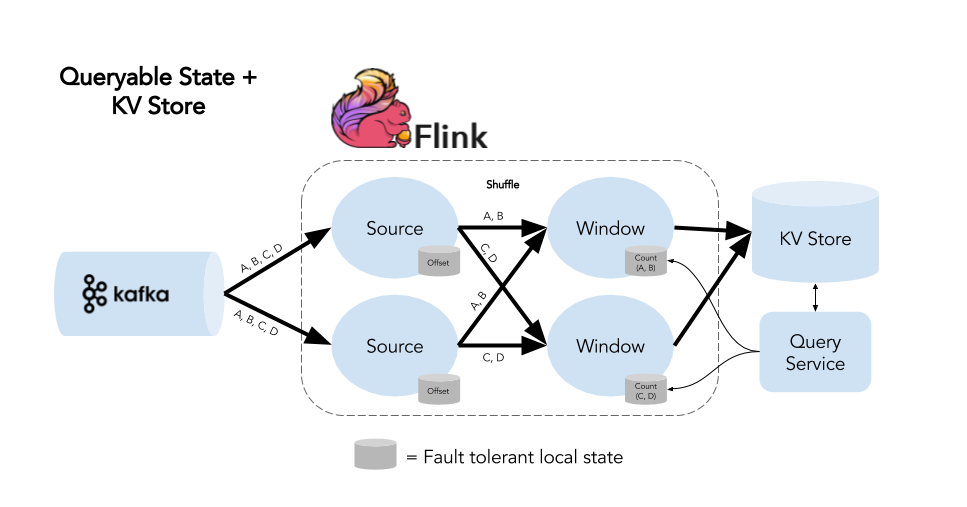 The diagram is nearly identical to our initial approach with one addition: we now have access to the results of an in-flight window using Flink’s Queryable State API. In other words, the external application responsible for providing results to users interacts directly with our Flink application to provide access to aggregates, while completed windows are still sent to a key-value store. In this approach, we’ve solved for one notable shortcoming in the stateful streaming architecture--no real-time access to results from in-flight aggregates--and we’ve done so without sacrificing any of the benefits of the approach. But we’re still reliant on an external store where we send our completed counts.
The diagram is nearly identical to our initial approach with one addition: we now have access to the results of an in-flight window using Flink’s Queryable State API. In other words, the external application responsible for providing results to users interacts directly with our Flink application to provide access to aggregates, while completed windows are still sent to a key-value store. In this approach, we’ve solved for one notable shortcoming in the stateful streaming architecture--no real-time access to results from in-flight aggregates--and we’ve done so without sacrificing any of the benefits of the approach. But we’re still reliant on an external store where we send our completed counts.
The Logical Conclusion: No External Key-Value Store
Let’s take it one step further. 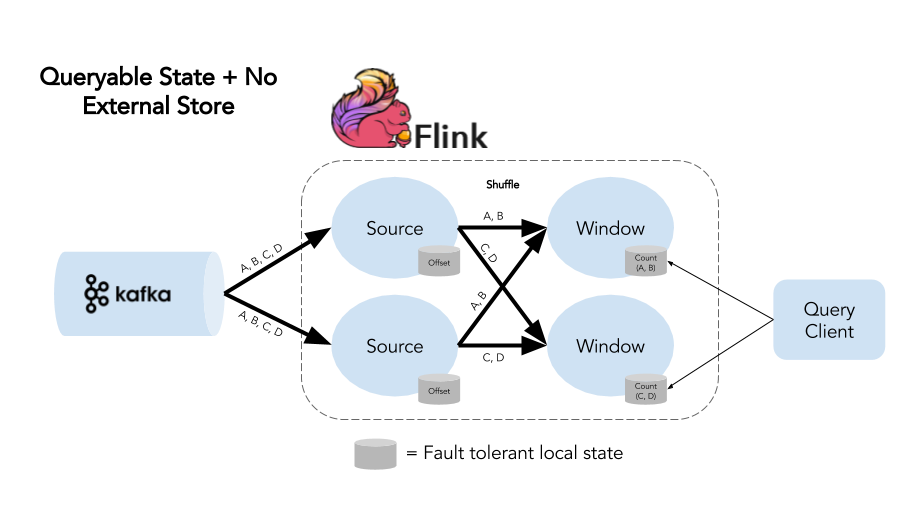 This diagram shows an approach where Queryable State allows us to completely remove the external store where we were sending our completed windows. Instead, all of the results from the application are stored in Flink state and only in Flink state. By fully taking advantage of Flink’s application state, we’ve simplified our end-to-end system by removing the need for an additional store. It’s one layer of complexity that we can remove from the application altogether. And there you have the vision behind Flink’s Queryable State: providing external applications with access to real-time results from Flink state and a simplified architecture.
This diagram shows an approach where Queryable State allows us to completely remove the external store where we were sending our completed windows. Instead, all of the results from the application are stored in Flink state and only in Flink state. By fully taking advantage of Flink’s application state, we’ve simplified our end-to-end system by removing the need for an additional store. It’s one layer of complexity that we can remove from the application altogether. And there you have the vision behind Flink’s Queryable State: providing external applications with access to real-time results from Flink state and a simplified architecture.
Queryable State in Flink 1.2.0: A Demo
Let's take a look at a sample Flink program that exposes a count for external queries. You can follow along at https://github.com/dataartisans/flink-queryable_state_demo and try it out firsthand. 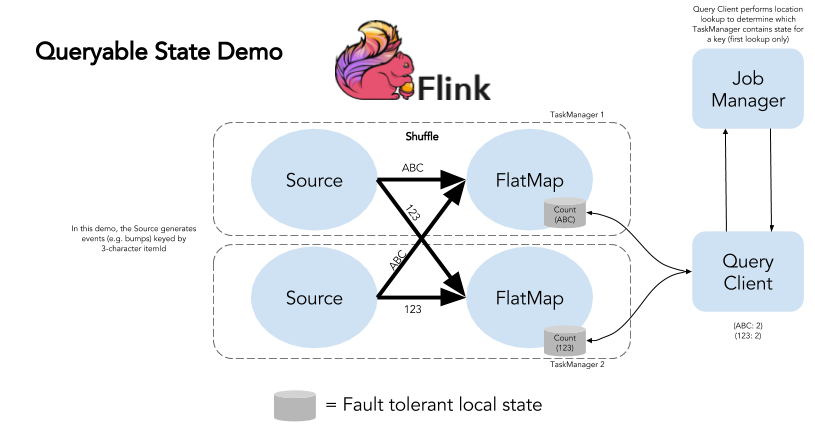 In this example, we have a stream of
In this example, we have a stream of BumpEvent instances, where each event is triggered by a user interacting with an item (e.g. a piece of content). For the purposes of this demo, the source generates the events itself.
public class BumpEvent {
// ID of the user bumping the item
private final int userId;
// Item being bumped
private final String itemId;}
The item IDs in our example are three-character alphanumeric Strings like ABC or 1A3. We want to count how many bumps each item receives and therefore key the stream by the itemId. After we have created the keyed stream, we expose it as a queryable state stream using Flink's state abstractions.
// Increment the count for each event (keyed on itemId)
FoldingStateDescriptor<BumpEvent, Long> countingState = new FoldingStateDescriptor<>(
"itemCounts",
0L, // Initial value is 0
(acc, event) -> acc + 1L, // Increment for each event
Long.class);
bumps.keyBy(BumpEvent::getItemId).asQueryableState("itemCounts", countingState);The queryable state stream will receive every event and update the created state instance. In this example, we use so called FoldingState that updates an accumulator for each received event. In our case we increment a count (acc + 1L). Note that you are not bound to the folding state variant, but have full flexibility to use other Flink-supported state, too. Check out the documentation for more details on this. Now, our application is ready to answer external queries as soon as it is running. The query side of things is handled by the QueryableStateClient that is fully asynchronous and handles lookup of state locations when necessary and network communication to actually query the state instance. As a user, you only have to provide the following information to set up the client:
- The ID of the job to query
- The name of the state instance to query
- The types of the key and values
In our example, the name of the state instance is itemCounts, the key type is String, and the value is Long. The rest is handled by the client, and you can directly start to query your stream. Our demo code includes a simple REPL that allows you to repeatedly submit queries against a running job:
[info] Executing EventCountClient from queryablestatedemo-1.0-SNAPSHOT.jar (exit via Control+C)
$ ABC
[info] Querying key 'abc'
446 (query took 99 ms)
$ ABC
[info] Querying key 'abc'
631 (query took 1 ms)We query the job for the counts of the item with key ABC and get increasing counts back, first 446, then 631. The initial query takes longer, because the client does a location lookup to find out which TaskManager actually holds state for key ABC. After the location information is available, the client caches it for later requests. The actual requests are then directly answered by the TaskManager that holds the state for a specific key. 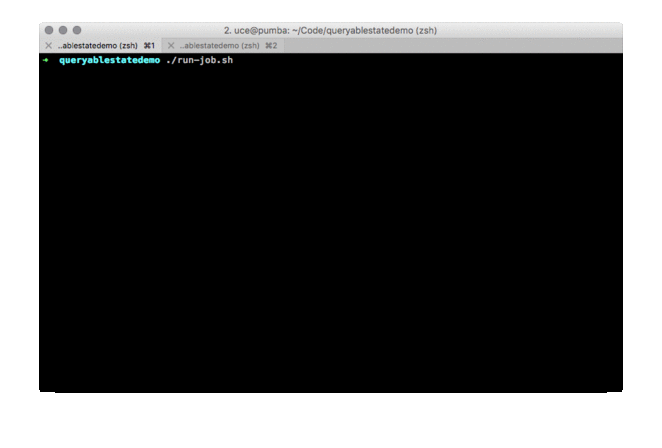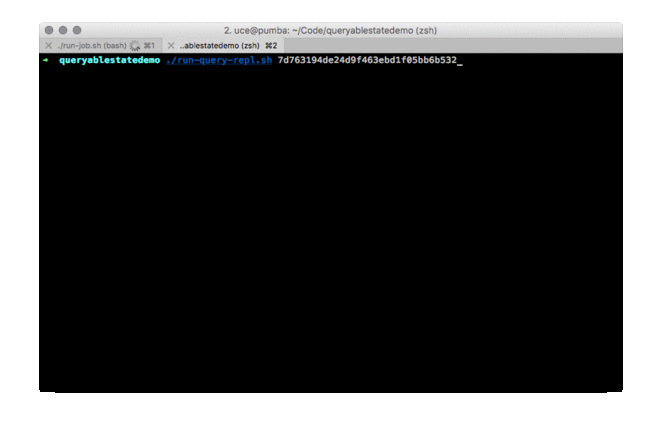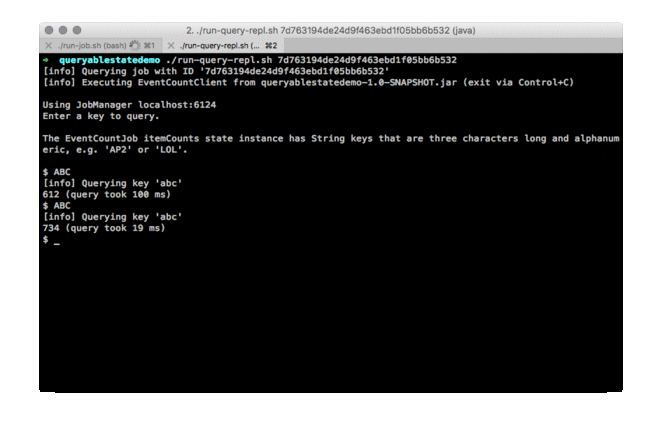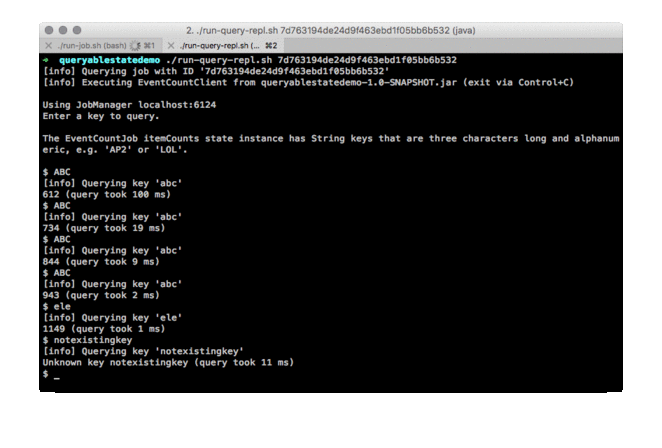 Please check out the demo repository and try it yourself! Current Limitations This overview wouldn’t be complete without discussing some of the ways that Queryable State can be improved in the future. Here are two that come to mind.
Please check out the demo repository and try it yourself! Current Limitations This overview wouldn’t be complete without discussing some of the ways that Queryable State can be improved in the future. Here are two that come to mind.
- This initial version of queryable state only allows keyed streams and manually managed state instances to expose their state for queries. This means that it is not possible to query window contents yet, which would require Flink's internal window operators to expose their state for queries, too. Since they use the same state abstractions as regular users, this is a straightforward addition to the DataStream API that is very likely to be addressed soon.
- Right now, queries always go to the live stream. After a failure, Flink will restore the state as of the latest checkpoint, which could reset counts to an earlier value than what may have been queried externally before. A potential solution is to be able to restrict queries to the latest checkpointed state only, which guarantees correctness of the queried counts. This is similar to database isolation levels read-committed (query against the latest checkpointed state) and read-uncommitted (query against the live stream).
Wrapping Up
We hope this post made you aware of the exciting work being done to unlock the potential of locally-managed application state, and not only within the Apache Flink community--the teams at Confluent and Codecentric have both written detailed posts about Apache Kafka’s Interactive Queries feature that are worth reading. And as the Flink community makes progress on Queryable State, we at data Artisans will be sure to write more about the feature. If any of our readers have feedback about Queryable State or would like to become a Flink contributor, please reach out to the Flink user mailing list.
If you’re interested in the topic and would like to explore it further, you can check out Jamie Grier’s talk “The Stream Processor as a Database” from Flink Forward 2016 in Berlin. It was inspired by Jamie’s time spent working on streaming systems at Twitter and examines a use case with the requirement to:
- Count Tweet impressions for all Tweets, windowed hourly
- Store historical hourly aggregates for all Tweets in a time-series database and provide low-latency access to recent results
- Handle a volume of 1 million tweet impressions (events) per second on approximately 100 million unique tweets (keys) per hour

You may also like

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica

Maximize Efficiency: How Ververica's BYOC Deployment Optimizes CAPEX and OPEX
