














Update December 18, 2017: Nearly 2 years after this initial post, we discussed the Yahoo streaming benchmark in another blog post where we cover some of the issues we see with modern benchmarking methods.
Until very recently, I’ve been working at Twitter and focusing primarily on stream processing systems. While researching the current state-of-the-art in stateful streaming systems I came across Apache Flink™. I’ve known for some time that having proper, fault-tolerant, managed state and exactly-once processing semantics with regard to that state was going to be a game changer for stream processing so when I came across Apache Flink™ I was understandably excited.
Shortly after my first introduction to Flink I saw that the Flink Forward 2015 conference was about to be held in Berlin and I knew that I had to be there to learn more. I spent a few days in Berlin attending talks and having long discussions with the Flink committers and others in the Flink community. By the end of the conference it was apparent to me that Flink was far and away the most advanced stream processing system available in the open source world. I returned home determined to see what I could accomplish with Flink back at Twitter.
I had an application in mind that I knew I could make more efficient by a huge factor if I could use the stateful processing guarantees available in Flink so I set out to build a prototype to do exactly that. The end result of this was a new prototype system which computed a more accurate result than the previous one and also used less than 1% of the resources of the previous system. The better accuracy came from the fact that Flink provides exactly-once processing guarantees whereas the existing system only provided at-most-once. The efficiency improvements came from several places but the largest was the elimination of a large key-value store cluster needed for the existing system. This prototype system earned my team first prize in the infrastructure category at Twitter’s December 2015 Hack Week competition!
During the course of my work with Flink I also developed a good sense of Flink’s performance capabilities so I was very interested when I read the Yahoo! benchmark that was recently published comparing Storm, Flink, and Spark. The benchmark measures the latency of the frameworks under relatively low throughput scenarios, and establishes that both Flink and Storm can achieve sub-second latencies in these scenarios, while Spark Streaming has much higher latency. However, I didn’t think the throughput numbers given for Flink lined up with what I knew was possible based on my own experience so I decided to dig into this as well. I re-ran the Yahoo! benchmarks myself along with a couple of variants that used the features in Flink to compute the windowed aggregates directly in Flink, with full exactly-once semantics, and came up with much different throughput numbers while still maintaining sub-second latencies. The extended benchmarks are available on GitHub.
In the rest of this post I will go into detail about my own benchmarking of Flink and Storm and also describe the new architecture, enabled by Flink, that turned out to be such a huge win for my prototype system at Twitter.
During the process of working with Flink and building this application on top of it I’ve come to realize just how advanced a system Apache Flink™ actually is. As a result of this whole process and working closely with the team behind Apache Flink™ I’m very happy to report that I’ve decided to join data Artisans to continue this work full time!
Benchmarking: Comparing Flink and Storm
For background, in the Yahoo! benchmark the task is to consume ad impressions from Kafka, look up which ad campaign the ad corresponds to (from Redis) and compute the number of ad views in each 10 second window grouped by campaign. The final result of the 10 second windows are written to Redis for storage as well as early updates on those windows every second. This is the same benchmark we are discussing in this section of the post.
All experiments referenced in this post were run on a cluster with the following setup. This is close to the setup used in the Yahoo! experiments with one exception. In the Yahoo! experiments the compute nodes running the Flink and Storm workers were interconnected with a 1 GigE interconnect. In the setup we tested the compute nodes were interconnected with a 10 GigE interconnect. The connection between the Kafka cluster and the compute nodes however was still just 1 GigE. Here are the exact hardware specs:
- 10 Kafka brokers with 2 partitions each
- 10 compute machines (Flink / Storm)
- Each machine has 1 Xeon E3-1230-V2@3.30GHz CPU (4 cores w/ hyperthreading) and 32 GB RAM (only 8GB allocated to JVMs)
- 10 GigE Ethernet between compute nodes
- 1 GigE Ethernet between Kafka cluster and Flink/Storm nodes
Fault Tolerance and Throughput
We used the benchmark programs from the Yahoo! streaming benchmark to measure the maximum throughput of each system while maintaining the best possible fault tolerance.
- For Storm, we turned acknowledgements on, to make the spouts re-send lost tuples upon failures. This, however, does not prevent lost state in the event of a Storm worker failure. The messaging guarantees provided are at-least-once which means there can be tuple replays leading to overcounting. In addition to that the actual state being accumulated on each node as the 10 second aggregates are computed is lost whenever there is a failure. This leaves the possibility of both lost values and duplicates in the final results.
- For Flink, we changed the job to use Flink’s built-in windowing mechanism. Starting with version 0.10, Flink supports windows on event time. We use Flink’s window trigger API to emit the current window to Redis when the window is complete (every 10 seconds) and in addition we do an early update of the window every second to meet the SLA requirement defined in the Yahoo! benchmark. We also have Flink’s fault tolerance mechanism enabled (with checkpoints every second) which means the window state is recovered in the event of any failure and also guarantees exactly-once semantics with regard to the aggregated counts we are computing. Said another way this means the results we are computing here are the same whether there are failures along the way or not. This is true exactly-once semantics.
Below is a diagram giving an overview of the system used in the benchmark. On the left you see the original Flink job as reported in the Yahoo! benchmark. There is custom code to compute and cache the windows locally along with a separate user thread to flush results to Redis periodically. This is a direct port of the Storm job to Flink so it doesn’t take advantage of Flink’s window API for computing windows. On the right you see a similar diagram except in this case the job uses the Flink window API which fault-tolerantly manages the windows and emits them downstream based on user-specified triggers. This version is both simpler and provides better fault-tolerance guarantees: exactly-once. 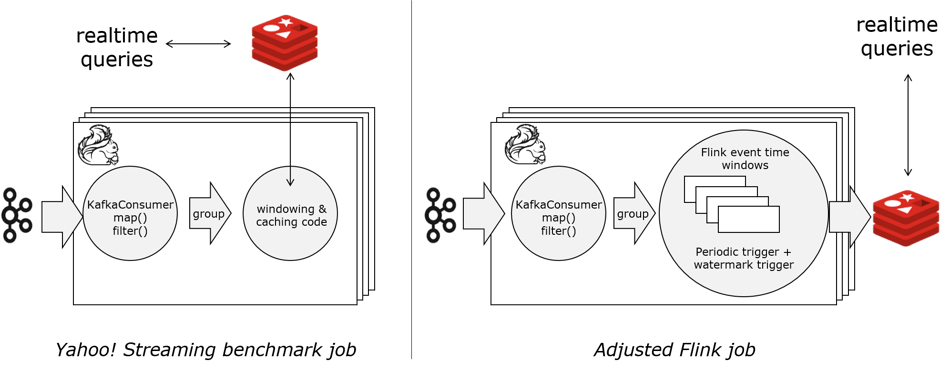 The chart below shows the maximum throughput we were able to get out of the systems. There are a few interesting points:
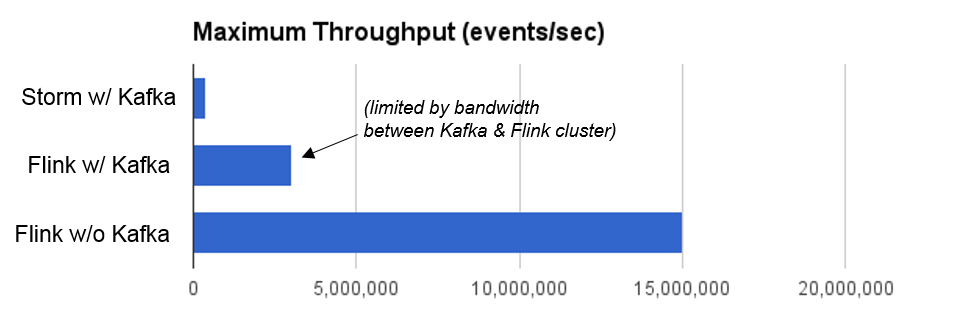
The chart below shows the maximum throughput we were able to get out of the systems. There are a few interesting points:
- We were actually able to get 400K events/second out of Storm (compared to 170K in the Yahoo! benchmark), presumably because of the difference in CPUs we used and potentially the 10 GigE links between the worker machines. Storm was still not able to saturate the network links to Kafka, however.
- Flink started to saturate the network links to Kafka at around 3 million events/sec and thus the throughput was limited at that point. To see how much Flink could handle on these nodes we moved the data generator into the Flink topology. The topology then had 3 operators: (datagen) -> (map-filter) -> (window). In this configuration we were able to get to a throughput of 15 million events/second.
- We could not see a measurable throughput difference in Flink when switching fault tolerance on or off. Since the state is comparably small, the checkpoints cost very little.
Winning Twitter Hack Week: Eliminating the key-value store bottleneck
While the above results are very interesting by themselves, it’s even more interesting when moving to applications that use large windows and many distinct keys. The starting job during Hack Week was a pipeline with over a million events per second, but windows of one hour, each window containing hundreds of millions of distinct keys per window.
Where the Yahoo! streaming benchmark job writes 100 windows per second to the key-value store (100 distinct ad campaigns), the above mentioned stream needs to update millions of entries in the key-value store per second. Scaling that type of streaming application quickly becomes an exercise in scaling out the database. In addition, unless you have state managed by the streaming system with exactly once guarantees you can’t actually do accurate counting in the face of failures. Like the Yahoo! benchmark system, the system in use at Twitter also suffered from these same issues.
The solution we came up with during Hack Week to circumvent the key-value store is shown in the sketch below. It is somewhat similar to the streaming job with Flink’s windows above, but instead of periodically writing current windows into a database (to make them accessible), we directly exposed the in-flight windows to be queried. That way, only final windows need to be written to the database (once per hour). This ends up reducing the load on the database dramatically while still making the state queryable immediately as it’s computed.
To query the window contents, we wrote a custom Flink operator that computes the windows and in addition runs an Akka actor system for the queries. Flink computes the windows and checkpoints them as part of its fault tolerance mechanism, while Akka acts like an RPC system that answers the state queries (“get state for key k, time t”). 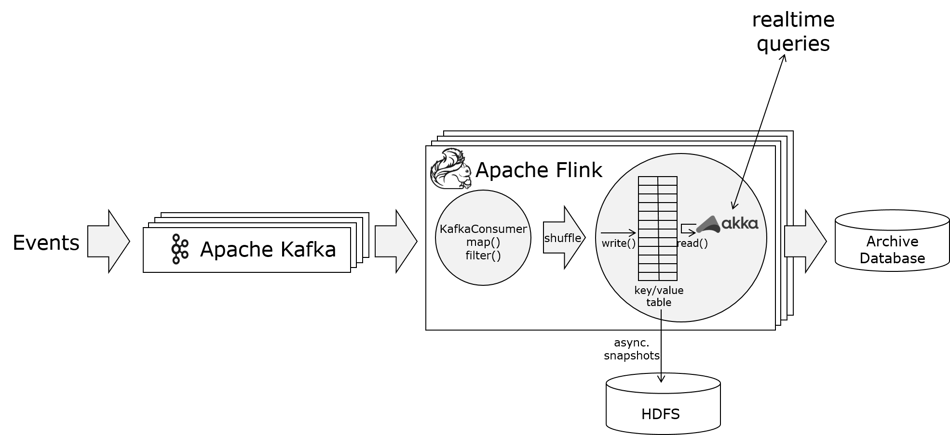
Streaming application querying state in the stream processor
To show the value of this approach in the context of the Yahoo! benchmark we created another variant in which we have 1,000,000 campaigns and store and update the windows directly in the key-value store. When you do this the key-value store very quickly becomes the bottleneck in the streaming application. In our benchmark this bottleneck occurred at around 280,000 events/sec. Beyond that there was no way to increase throughput further without either scaling up the key-value store dramatically or getting rid of it altogether.
We chose to get rid of it altogether. This is the power of having fault-tolerant local state. The stream processor itself becomes the key-value store and updating state becomes fast and cheap in-memory processing rather than communication across the network to a remote store.
Using this model we were able to completely eliminate the key-value store bottleneck and achieve a throughput of 15,000,000 events/sec all while making the data directly queryable instantly as it’s processed. This is the new architecture that the new generation of stream processing technology such as Flink enables.
Latency
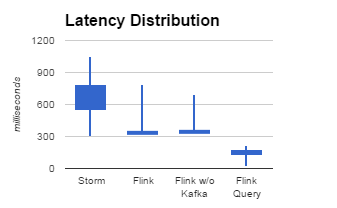
While we were mainly looking into throughput and fault tolerance in these experiments, we also evaluated latency. Because the programs are very different from each other, the latencies should not be compared to each other directly. They merely stand to show that all approaches discussed here achieve acceptably low (sub-second) latency.
- Both the Storm job and the first Flink job write their results to Redis, and latencies are analyzed with the same formula and scripts as in the Yahoo! streaming benchmark. The scripts only see the final write of a window to Redis. We measured a comparable latency distribution for Storm as the one reported in the Yahoo! streaming benchmark. The majority of the latency is caused by the delay of the thread that periodically flushes the results to Redis.
- Flink's final window write is triggered when the window is closed by the event time watermark. Under default settings, that watermark is generated more frequently than once per second, leading to a bit more compact latency distribution. We also observed that the latency stays low under high throughput.
- The Flink-with-state-query job has no form of periodic flush or delay at all; hence, the latency here is naturally lower than in the other jobs, ranging between 1 and 240 milliseconds. The high-percentile latencies come most likely from garbage collection and locks during checkpoints and can probably be brought even lower by optimizing the data structure holding the state (currently a simple Java HashMap).
Our takeaway from these experiments
While Storm paved much of the way for open source streaming, Flink and Storm represent, really, two different generations of stream processing technology. Flink can be used similarly to Storm (as in the Yahoo! benchmark), but comes with features that support new approaches to building streaming applications. Embracing these new approaches can lead to huge wins in many dimensions:
- Higher efficiency: The difference in throughput between Storm and Flink is huge. This translates directly to either scaling down to fewer machines or being able to handle much larger problems.
- Fault tolerance and consistency: Flink provides exactly-once semantics where Storm only provides at-least-once semantics. When these better guarantees come at high cost, many deployments will deactivate them and applications will often not be able to rely on them. However, with Flink exactly-once guarantees are cheap and applications can take it for granted. This is the same argument as for NoSQL databases, where better consistency guarantees led to wider applicability. With these guarantees a whole new realm of stream processing applications become possible.
- Exploiting local state: When building streaming applications, fault-tolerant local state is very powerful. It eliminates the need for distributed operations/transactions with external systems such as key-value stores which are often the bottleneck in practice. Exploiting the local state in Flink like we did, we were able to build the query abstraction that lifted a good part of the database work into the stream processor. This allowed us tremendous throughput and also allowed queries immediate access to the computed state.
Special thanks to Steve Cosenza (@scosenza), Dan Richelson (@nooga) and Jason Carey (@jmcarey) for all their help with the Twitter Hack Week project.

You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
