














This is a story based on a real business use case, featuring an e-commerce company (“KartShoppe”) that is just beginning to explore and implement real-time feature engineering.
Introduction
KartShoppe has a significant challenge: their data teams are struggling to keep up with the growing demands of the business. KartShoppe operates a popular online marketplace with millions of users, and every click, view, and purchase generates data that is crucial for understanding user behavior, providing recommendations, and identifying possible fraudulent activities. However, no matter how much the team tries, they can’t shake the feeling that their data pipelines and models are lagging behind the actual user experience. The explanation? By the time their models receive the latest user data, that data is already out-of-date, making it incredibly hard for their recommendation and fraud detection engines to provide helpful decisions that further engage their customers, provide a better customer experience, and ultimately increase business profits.
KartShoppe is ready to make real-time decisions based on real-time data.

Figure One: KartShoppe
The next step? Implementing feature engineering that allows the team to select, transform, and create relevant input variables from their raw data that improves the performance of their machine learning models. Feature engineering is a crucial step in the AI/ML pipeline to ensure models receive high-quality, meaningful data at low latency and at highly scalable, variable volumes.
If KartShoppe’s challenge sounds familiar, you’re not alone. Real-time data engineering, especially for machine learning and AI, allows companies to deliver quick insights and timely predictions, and traditional batch processing isn’t fast enough when the goal is to create real-time experiences. With the recent explosion of AI, real-time stream processing solutions like Ververica’s Unified Streaming Data Platform have become even more essential across industries that rely on instant data for immediate decision-making. In this blog post, we’ll explore how real-time data pipelines that support feature engineering strategies are implemented. Let’s begin with a look at the big picture of real-time AI pipelines and workflows, and then dig into the technical components that KartShoppe adopts to solve their use cases.
Note: Throughout this blog the term “AI” is used interchangeably when describing both machine learning and AI models. AI refers specifically to externally owned models (including Qwen, Gpt4o, and DeekseekR1) vs ML where the model is trained in-house (with tools like TensorFlow or PyTorch).
Real-Time Data Pipelines For AI: The Big Picture
Building effective real-time AI pipelines involves more than simply feeding data into a model. It requires an end-to-end data pipeline that continually ingests, processes, and refines incoming data, while at the same time being able to adapt and incorporate new information. Figure 1 below outlines the major components of a complete real-time AI data pipeline. Let’s break down each of these steps:

Figure Two: AI Data Pipelines
1. Data Ingestion
Real-time data pipelines begin with the ingestion layer that captures event streams from various sources, including operational databases, message queues, and third-party APIs. Ingesting raw data from nearly any source is incredibly powerful, but techniques like Change Data Capture (CDC) also come into play, turning databases into continuously updated streams of inserts, updates, and deletes. CDC tracks and identifies every modification made to data in real-time, ensuring that the data and pipeline remains consistent and in sync with the latest changes, enabling models and other downstream applications to have access to the freshest possible inputs near-instantaneously.
2. Data Preprocessing
Before any model can extract value, incoming data needs to be cleaned, standardized, and validated. During this stage, the pipeline removes duplicates, normalizes values into a consistent format, and flags outliers or anomalies that could skew predictions. Completing these steps early sets a strong foundation for reliable feature engineering and accurate model outputs, mitigating issues that could compound downstream.
3. Feature Extraction and Engineering
Once data is cleaned, the pipeline transitions to transforming raw observations into relevant features, including the metrics or attributes that capture the essence of what the model needs to learn. For example, an e-commerce business like KartShoppe might track "number of items viewed in the last 10 minutes" or "time since the user’s last login as features to support real-time recommendations. High-quality features enhance a model’s view of user behavior or system states, thereby boosting accuracy and resilience. This step is often considered the “creative core” of AI, as well-crafted features can dramatically improve predictive performance.
4. Model Serving and Inference
With features generated and readily available, the pipeline must serve these features to deployed models at scale and on time, including demands that must take place within milliseconds. A well-designed serving infrastructure handles high volumes of requests (e.g., personalized recommendations or fraud checks,) while maintaining low latency. In practice, this might involve specialized microservices or inference frameworks optimized for concurrency, load balancing, and failover. By seamlessly feeding up-to-date data into model inference, real-time pipelines can support prompt decisions that directly impact user experience or security.
5. Adaptive Learning
Over time, the environment in which these models operate can shift significantly. Adaptive or online learning allows models to update their parameters continuously based on new data as it arrives, without requiring a full offline retraining process. This capability is important for situations like evolving fraud tactics or rapidly changing consumer preferences. By assimilating the latest data, models retain their relevance and effectiveness, reducing the time lag between shifts in real-world behavior and the pipeline’s response.
6. Feedback Loops
While adaptive learning focuses on real-time changes in the data itself, feedback loops emphasize the ongoing evaluation of model performance. Each prediction generates an outcome, for example, whether a recommended item was clicked or if a flagged transaction was indeed fraudulent. The pipeline records these outcomes to assess predictive accuracy and to further refine the model in subsequent iterations. This continuous feedback mechanism underpins true machine learning maturity: the system not only adapts to new data patterns, but also learns from its own successes and missteps to improve decision-making over time.
It’s important to note that adaptive learning and feedback loops might seem similar, but they are not the same. Both concepts involve improving the model over time, but adaptive learning focuses on learning from new data, while feedback loops provide improvements based on the accuracy of previous decisions.
The Complete Real-Time AI & ML Pipeline
When put together, this complete pipeline creates the backbone of real-time AI, where data is ingested, processed, and used for real-time actions while simultaneously adapting and improving based on feedback and new data.
Now that we have an understanding of the overall pipeline, let’s focus on feature engineering specifically.
The Journey from Batch to Real-Time Feature Engineering
Feature engineering is the process of transforming raw data into meaningful inputs (ie: features) that improve the performance of models. At its core, AI and ML models rely on features to represent the problem domain in a way that the model can understand and process. High-quality features allow:
- Actionable signals: Features do not merely replicate raw data; instead, they highlight the elements most relevant to the predictive task. By capturing crucial patterns (like recent clicks, transactions, or anomalous activities) into a more informative representation, they allow the model to focus on what truly matters. This accelerates learning and avoids overwhelming the model with “noise” (ie: irrelevant content).
- Improve model accuracy: When features capture the most pertinent aspects of user behavior or system states, the model’s predictive power increases significantly. Robust features help the model generalize effectively, meaning it can produce reliable predictions even when presented with new, unseen data. Better generalization translates into fewer mistakes and more consistent performance.
- Reduce complexity: Properly engineered features simplify how the model “views” the problem space. Rather than forcing a model to infer critical relationships from unprocessed data, high-quality features organize and refine the input, making patterns more apparent. This streamlined input representation reduces the risk of overfitting, (where a model memorizes details specific to the training data,) and also makes it easier to tune and maintain models over time.
- Domain relevance and interpretability: Effective feature engineering often integrates domain expertise, ensuring that each feature reflects a real-world concept or behavior. Domain alignment not only improves the model’s accuracy but also makes the results more interpretable. When decision-makers can connect model outputs back to meaningful features, (like "average purchase frequency" or "time since last login") they gain greater trust and insight into why the model behaves the way it does.
Taking Batch to Real-Time
In a batch processing setup, engineers usually create features by aggregating data over long time windows, such as weeks or months. While plenty of use cases still benefit from batch processing, many modern business use cases demand real-time requirements, and batch processing simply isn’t fast enough to keep up. For example, in the case of KartShoppe building their recommendation engine, knowing what a user did a month ago is valuable, but understanding what they did a few seconds ago is much more powerful, actionable data.
Features are also not static. In dynamic environments and industries like e-commerce, finance, or IoT, (to name a few,) the data landscape evolves rapidly. Static, pre-computed features quickly become stale, leading to degraded model performance. This is particularly detrimental in applications where decisions need to be made in real-time, like recommending products during an active user session, or for fraud detection.
So how do we turn raw, real-time data into high-quality features for ML models? For companies like KartShoppe, this is where streaming data platforms shine, making the process seamless for engineers.
Built to be 100% compatible with Apache Flink, the de facto standard for stream processing, Ververica’s Unified Streaming Data Platform is ideal for real-time feature engineering. Powered by the VERA engine, the solution provides Streaming Data Movement, Streamhouse, and Real-Time Stream Processing into a single platform. (See Figure 3.)
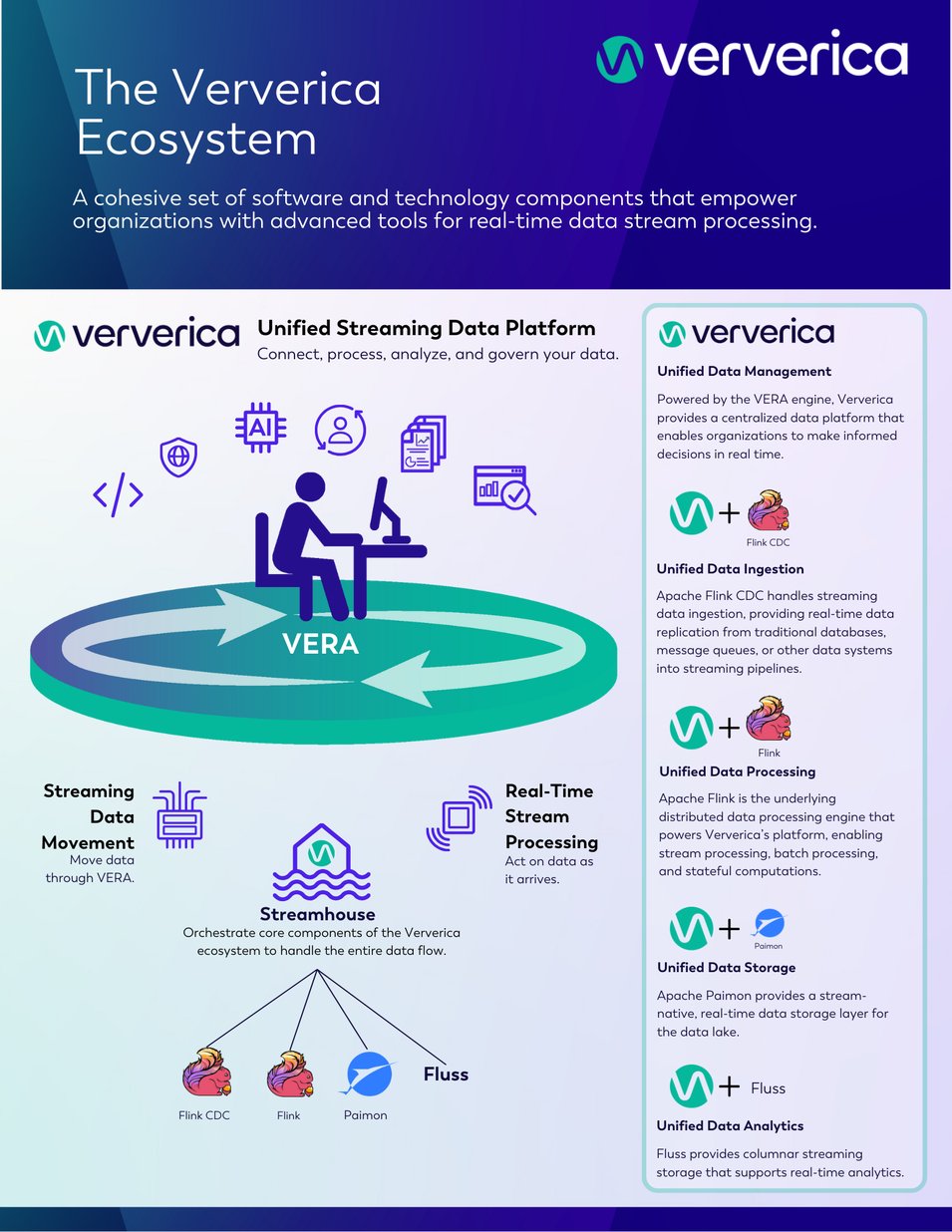
Figure Three: Ververica’s Unified Streaming Data Platform Ecosystem
While the solution can handle data at any speed, it is exceptional at real-time data streaming. Instead of waiting for batches of data, the platform processes events as they happen, with minimal latency. It then allows you to apply transformations, aggregates, and other complex logic directly on data streams, effectively creating features in real-time, allowing businesses (like KartShoppe) to make decisions on fresh data and respond to user behavior in milliseconds.
KartShoppe: Using Ververica for Real-Time Feature Engineering
With powerful stream processing capabilities, Ververica’s Unified Streaming Data Platform empowers KartShoppe’s data team to convert a once-lagging batch process into a dynamic, real-time engine for machine learning. This shift is more than just a technological upgrade, it fundamentally changes how KartShoppe approaches data, enabling immediate event-driven transformations and dramatically reducing the latency between raw input and actionable insights.
Continuous Transformations
Before adopting Ververica, KartShoppe relied on scheduled batch jobs to generate and refresh features. These jobs often run hourly or even daily, resulting in stale features whenever user behavior changes rapidly. With Ververica, data ingestion becomes a continuous flow. The team no longer waits to accumulate large batches of events, instead, each click, purchase, or page view is processed and actionable the moment it arrives.
In addition, they use Datastream API to allow the engineering team to create streaming applications that perform filtering, mapping, and aggregation on the fly. They also handle out-of-order events, a common scenario in distributed systems where network delays or asynchronous processing cause events to arrive late. By deploying watermarking strategies, the team preserves correct ordering at the logical level, ensuring no data is lost or doubly processed. As soon as a user makes a purchase, metrics such as "time since last purchase" and "number of items viewed in the current session" update, making KartShoppes models far more adaptive than before.
Accurate, Time-Based Aggregations
KartShoppe needs to incorporate time-sensitive behavior into both its recommendation and fraud detection features. For instance, a feature like ""total amount spent by a user in the last hour" is only useful if it is calculated precisely according to event times. Ververica's event-time processing model, combined with sliding or tumbling windows, offers a way to compute these aggregates with a high degree of accuracy.
In practice, this means the system handles small delays or inconsistencies in how events arrive, as watermarks ensure that windowed computations trigger only when a certain level of timestamp certainty is met. If a user’s payment event trails behind by a few seconds or arrives out of sequence, the platform still updates the feature correctly once the correct watermarks are reached. These consistently accurate time-based features become invaluable for predicting immediate user actions and identifying anomalies that might only appear when examined within specific time intervals.
Time-Based Joins for Event Correlations
To build richer features, the KartShoppe team needs to correlate events occurring within specific time intervals. For example:
"Time gap between a product view and a purchase": This required joining product view events with subsequent purchase events within a defined window.
Support for interval joins makes this straightforward. By defining a time-based join between two streams (e.g., views and purchases), the team can compute features like:
SELECT
v.userId,
v.productId,
TIMESTAMPDIFF(SECOND, v.eventTime, p.eventTime) AS timeToPurchase
FROM productViews v
JOIN purchases p
ON v.userId = p.userId
AND v.productId = p.productId
AND p.eventTime BETWEEN v.eventTime AND v.eventTime + INTERVAL '30' MINUTEWith interval joins, correlating events from two different streams, like productViews and purchases also becomes easier. By specifying a time-based condition, the system automatically pairs view events with corresponding purchase events that happen within a fixed interval (30 minutes for example). This allows the calculation of features that capture user intent, urgency, and overall responsiveness to marketing or search placements. In turn, these features drive more nuanced recommendations and higher confidence in identifying future fraudulent or abnormal purchasing behavior.
Stateful Processing for Complex Features
Not all real-time features can be derived from a single pass aggregation. Some require the system to remember and update data over extended periods. For example, KartShoppe needs rolling averages of purchase amounts and session-level details like total session duration or the number of distinct items viewed in one session.
Using managed state, developers build sophisticated event handlers that retain context between streams of data. The rolling average of purchase amounts (for example) is maintained in a keyed state that keeps track of how many purchases a given user has made and at what amount. Whenever a new purchase event arrives, the solution updates the state and recalculates the average. Because Ververica’s Unified Streaming Data Platform offers built-in fault tolerance and checkpointing via Flink, these stateful computations handle machine restarts or occasional outages without losing critical information. This resilience gives KartShoppe confidence that even under high-traffic scenarios, every feature calculation remains consistent and correct.
SQL for Simplicity
While DataStream transformations provide flexibility, many real-time features are simpler to express using declarative SQL. Flink SQL, within Ververica, offers a concise way to define windowed aggregations, joins, and filter conditions. By leveraging SQL, data engineers can rapidly prototype new features, freeing them from writing extensive Java or Scala code.
For instance, computing “average session duration” can be solved as a SQL query that joins session-start events with session-end events, and then calculates the time differences before aggregating them. Similarly, “conversion rate per campaign” is just another straightforward SQL grouping scenario. This ease of expression allows the team to accelerate feature development and respond more quickly to changing business needs or new ideas coming from the data science group.
How This Transformation Changes the AI Pipeline
Bringing all these capabilities together produces a robust, real-time feature engineering pipeline that fundamentally changes KartShoppe’s approach to machine learning:
- Immediate Adaptation: With minimal lag between data arrival and feature computation, models instantly reflect changes in user behavior, which results in more timely and relevant recommendations.
- Higher Model Accuracy: Features like real-time session metrics and event correlations provides the models with richer, context-aware information, improving the overall predictive performance.
- Reduced Operational Complexity: Declarative SQL, paired with built-in fault tolerance, simplifies operational tasks. The team no longer has to orchestrate multiple batch jobs or worry about data being out-of-sync across different systems.
Ultimately, by implementing Ververica’s solution, KartShoppe turns raw events into actionable signals for their ML models at near-instant speeds. The shift to real-time feature engineering lays the groundwork for an agile, data-driven environment, in which new ideas can be tested quickly, and user interactions are captured so rapidly that every click, view, and purchase drives more accurate predictions, with the additional benefits of uptime guarantees, expert help and support, and SLAs.
The Need For Feature Stores
As KartShoppe’s e-commerce data team continue building real-time feature pipelines, they quickly recognize another challenge: producing up-to-date features alone does not guarantee their models can reliably access those features at both training and serving time. Particularly in environments that include online recommendations and fraud detection, a predictive model is only as good as the data fed into it, and if the model is supplied with outdated or inconsistent feature values, the performance and reliability of predictions suffer.
To solve this, KartShoppe adds a feature store into their architecture. The feature store serves as a centralized system for maintaining, versioning, and distributing features across the organization. By integrating this tool with their Ververica-powered streaming jobs, the team establishes an end-to-end pipeline that ensures features are always fresh, consistent, and readily available for real-time inference.
In this case, Ververica ingests the raw event streams, (including clicks, views, and purchases) directly from databases and message queues. During ingestion, the team applies transformations such as time-based joins, windowed aggregations, and stateful queries to convert raw events into relevant features (for example: "average purchase amount over the last ten minutes"). Once calculated, these features are immediately pushed to the feature store, making them accessible to any model that requires real-time data for inference.

Figure Four: Feature Calculation, Storing, And Retrieval For Inference
This approach solves multiple challenges at once. First, it eliminates discrepancies between how features are generated for training and how they are served for inference, as both processes pull their data from exactly the same definitions. Second, it removes much of the costly overhead associated with repeatedly re-computing or copying features across different models and environments. And finally, it affords the data team a transparent way to track version histories of each feature, so that experimental changes or schema updates can be carefully managed without disrupting production pipelines.
The outcome is a real-time engine that reacts as user behaviors change. KartShoppe’s recommendation system no longer serves stale suggestions, and their fraud detection engine has immediate visibility into suspicious patterns, while new business initiatives can rapidly incorporate features from the store without duplicating any upstream engineering work. In essence, the feature store becomes the backbone of KartShoppe’s evolving AI ecosystem, delivering reliable, up-to-date feature data wherever it is needed.
Lessons Learned: Best Practices for Real-Time Feature Engineering
By moving to real-time feature engineering, KartShoppe continues to learn how to keep their systems both efficient and accurate. The first lesson they discover is that data quality can make or break the entire pipeline. Because everything operates in continuous mode, any anomalies or duplicated data can cause immediate downstream issues. As a result, the team adopts thorough validation at ingestion to safeguard data integrity and prevent sudden surges of flawed information.
Another key insight is the necessity of planning for schema evolution. As new product lines or user events emerge, the structure of incoming data changes, which can easily destabilize a streaming pipeline. By implementing a versioning strategy and building resilience into the pipeline, KartShoppe ensures each new data variation integrates without breaking existing feature engineering jobs.
Resource management also is a top priority. Handling large volumes of data in near real-time requires meticulous tuning of parallelism and memory allocation. Thoughtful partitioning strategies prevent data skew, a common issue when certain keys receive disproportionate amounts of traffic. To solve this, KartShoppe monitors workloads continuously and adjusts partitions to spread the load more evenly, using the elasticity and built-in scalability found in Ververica’s Unified Streaming Data Platform.
Finally, reliability proves paramount. Without robust fault-tolerance mechanisms, any unexpected disruption can interrupt data flows and degrade model performance. By using checkpointing and restart strategies, the team avoids lengthy outages and preserves stateful information across transient failures, ensuring that feature computations continue smoothly even in adverse conditions.
Conclusion: KartShoppe’s Journey
By embracing real-time feature engineering with Ververica, KartShoppe is able to successfully solve two major use cases, with plans to expand: first, their recommendation system is revitalized, and now provides customers with relevant suggestions at the exact moment that need and interest are highest. In addition, their fraud detection engine is able to catch potentially costly anomalies while simultaneously protecting the customer experience. Batch pipelines that once lagged now update features in real-time, ensuring that KartShoppe’s ML models always operate on the freshest, most recent user behavior data.
Behind this transformation, Ververica’s Streaming Data Platform provides robust real-time capabilities, alongside a feature store that safeguards consistency between training and inference models.
To summarize: KartShoppe’s post-transformation workflows demonstrate the potential of real-time AI pipelines to help businesses, including:
- Boosting engagement – A constant supply of accurate, context-aware recommendations increases click-through and conversion rates.
- Enhancing operational efficiency – Real-time analytics and automated feature engineering reduces manual intervention and data bottlenecks.
- Providing future-proof scalability – Adaptive, feedback-driven pipelines ensure the platform evolves in sync with changing user behaviors and market trends.
Real-time decision-making is an increasingly competitive edge in modern environments where milliseconds can help create a positive user experience or result in a lost sale. By combining modern architectural strategies with powerful solutions, organizations of all sizes can accelerate their journey from batch processing to real-time streaming and in doing so, position themselves as leaders in the era of AI-driven innovation.
For KartShoppe, the upgrade to real-time data processing and feature engineering marks a pivotal milestone. This not only improves their internal data efficiency, but also elevates their customers' experiences, ensuring that every recommendation, alert, or offer is relevant and timely and that the business and customers are protected from potentially fraudulent behavior. KartShoppe is a great example of how in the e-commerce industry, few advantages are as powerful as real-time intelligence.
Learn More
Curious to learn more about how Ververica’s Unified Streaming Data Platform solves other real-time use cases?
Check out the pages below:



