














This is the second blog post in our series on how Flink enables new streaming applications. Part 1 introduced event time and out of order processing.
This post is about versioning application state and was followed by a post about sessions and advanced windows (part 3, available here).
Stateful stream processing
Stream processing can be divided into stateless and stateful processing. Stateless stream processing applications merely receive events, and produce some kind of response (e.g., an alert or a transformed event) based on the information recorded on the last received event alone. As such, they have no “memory” or aggregating power. While these are useful in many cases (e.g., filtering, simple transformations), many interesting streaming applications, like aggregations over time windows, complex event processing and other pattern matching over several events, as well as transaction processing are stateful.
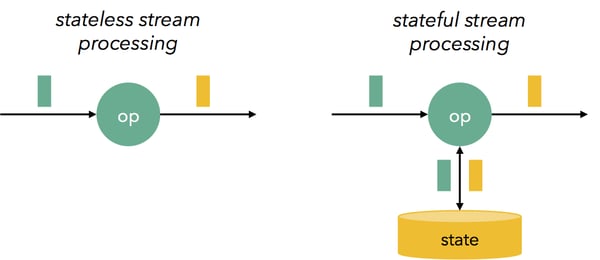
Older streaming systems, like Apache Storm (at its core API), did not have any support for stateful programs (Storm Trident, a library included with Apache Storm does provide support for state). Storm programs can define Java objects in bolts that hold state, or interact with external databases and key/value stores that hold state, but the system does not offer correctness guarantees for this state in the case of failures, falling back to “at least once” semantics (duplicates), or “at most once” semantics (data loss). This lack of accuracy guarantees, together with the inability to handle high volume streams (large throughput) made hybrid solutions like the Lambda architecture necessary. Flink represents a newer generation of streaming systems, and guarantees correctness of state, which makes stateful applications much easier. In Flink programs, you can define state in a variety of ways:
-
Using Flink’s window transformations, you can define time-based windows based on event or processing time, count-based windows, as well as generalized custom windows. See here for a short introduction to Flink windows, and stay tuned for the next blog post in this series for more advanced forms of windows.
-
Using the Checkpointed interface, you can register any kind of Java/Scala object (e.g., a HashMap) with Flink, guaranteeing its correct recovery after failure.
-
Using Flink’s key/value state interface, you can use state that is partitioned in the cluster by a key.
Where is this state stored? First, all the above forms of state are internally stored by Flink using a configurable state backend. Currently, Flink stores the state in-memory, and backs up the state in a file system (e.g., HDFS). We are actively working on providing additional state backends and backup options. For example, we recently contributed a state backed based on RocksDB, and we are working on a state backed that uses Flink-managed memory that can spill to disk if needed. In our experience, streaming applications, and especially stateful streaming applications are of a more “operational” nature than batch jobs. A batch job can run overnight, and can be re-run if the results were not as desired or if the job failed. In contrast, streaming jobs run 24/7 and power live, often user-facing applications and can therefore not be simply stopped and re-run. Production Flink users need to worry about the behavior of the jobs under upgrades (both of the application code and Flink itself), failures, as well as application and cluster maintenance.
Savepoints: versioning state
In Flink, we recently introduced savepoints, a feature that brings Flink a long way towards resolving the above and more issues. A savepoint can be taken on a running Flink job, and essentially takes an externally accessible snapshot of the job at a well-defined consistent time. It includes the offset currently being read from the stream sources, and the program state as it is at exactly this offset. Internally, savepoints are just regular checkpoints that Flink takes periodically in order to guarantee correctness in the case of failures. The main differences are (1) savepoints can be manually triggered, and (2) savepoints never expire unless explicitly disposed by the user. To take a savepoint of a running job with a given JobID through the command line, simply run
flink savepoint JobID
This will return a path that stores the savepoint (in the default configured file system, e.g., local, HDFS, S3, etc). To resume a job from that savepoint, simply run
flink run -s pathToSavepoint jobJar
With savepoints, you do not need to replay the event stream from the beginning to re-populate the state of a Flink job, as you can take a consistent snapshot at any time and resume from that checkpoint. In addition, when the log retention period is finite, it is useful to savepoint the state periodically, as the log cannot be replayed from the beginning. Another way to think about savepoints is saving versions of the application state at well-defined times, similarly to saving versions of applications themselves using version control systems like git. The simplest example is taking snapshots at regular intervals while changing the code of the application:
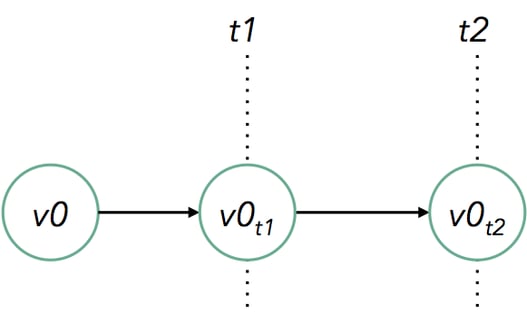
Even more, you can branch off from multiple savepoints, creating a tree of application versions:
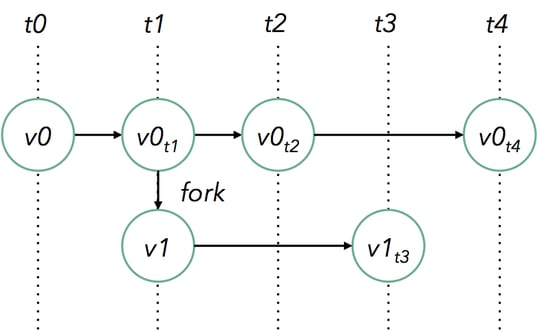
Here, two savepoints of a running job v0 are taken at times t1 and t2, creating version v0t1 and v0t2.These can be used to resume the job. As an example, the job is resumed from the savepoint at t1 with updated application code, creating v1 of the the program. At times t3 and t4, further savepoints are taken from version v0 and v1, respectively. Savepoints can be used to solve a variety of production issues for streaming jobs.
-
Application code upgrades: assume that you have found a bug in an already running application, and you want the future events to be processed by the updated code with the bug fixed. By taking a savepoint of the job, and restarting from that savepoint using the new code, downstream applications will not see the difference.
-
Flink version upgrades: upgrading Flink itself becomes also easy, as you can take savepoints of running pipelines and replay them from the savepoints using an upgraded Flink version.
-
Maintenance and migration: using savepoints, you can easily “pause and resume” an application. This is especially useful for cluster maintenance, as well as migrating jobs consistently to a new cluster. In addition, this is useful for developing, testing, and debugging applications, as you do not need to replay the complete event stream.
-
What-if simulations (reinstatements): many times it is very useful to run an alternative application logic to model “what if” scenarios from controllable points in the past.
-
A/B testing: by running two different versions of application code in parallel from the exact same savepoint, you can model A/B testing scenarios.
Conclusion
In this blog post, we saw:
-
Many interesting streaming use cases like aggregations over time windows, complex event processing or pattern matching require support for stateful programs inside the system. Flink’s support for state as a first class citizen enables these kinds of applications and allows Flink to make guarantees about the correctness of state (exactly ones semantics).
-
Stateful streaming applications face many operational issues like behaviour under upgrades (both of the application code and Flink itself), failures, as well as application and cluster maintenance. Flink’s support for savepoints help a great deal to solve these operational issues by allowing you to version both your application code and state.
Savepoints are part of the upcoming 1.0.0 release of Apache Flink™ with support for the use cases outlined in this post. A current limitation is that the parallelism of your program has to match the parallelism of the program from which the savepoint was drawn. In future versions of Flink, there will be support to re-partition the state of programs both during runtime and savepoint restores. In order to get started with savepoints, check out the docs about how savepoints work and how to use them from Flink’s command line.

You may also like

Preventing Blackouts: Real-Time Data Processing for Millisecond-Level Fault Handling

Real-Time Fraud Detection Using Complex Event Processing

Meet the Flink Forward Program Committee: A Q&A with Erik Schmiegelow
