














Tl;dr For the past few months, Databricks has been promoting an Apache Spark vs. Apache Flink vs. Apache Kafka Streams benchmark result that shows Spark significantly outperforming the other frameworks in throughput (records / second). We looked into the benchmark, and we found that:
-
Flink’s lower throughput is attributed to a bug in the data generator code Databricks wrote for Flink plus a simple configuration change
-
After fixing these issues, we see Flink significantly outperform Spark in throughput
Earlier this year, we shared why we’re not particularly fond of commonly-used stream processing benchmarks.
To be clear, our skepticism about over-reliance on benchmarks such as the Yahoo streaming benchmark does not mean we’re opposed to objective, repeatable methods for comparing stream processing frameworks.
Our skepticism is rooted in the fact that current benchmarks overlook key evaluation criteria for choosing a production-grade stream processing system in the best case, and in the worst case can be outright misleading.
In our earlier post about benchmarks, we elaborated on the first point: that evaluating a stream processing framework for use in a production application requires more than measures of throughput and latency performance in an artificial and controlled environment.
Today, we’re going to talk about the second point: that benchmarks can be (and often are) tuned to support a certain narrative, making it difficult for users to interpret the results with any sort of objectivity.
Step 1: Diagnosis
This October, Databricks published a blog post highlighting throughput of Apache Spark on their new Databricks Runtime 3.1 vs. Apache Flink 1.2.1 and Apache Kafka Streams 0.10.2.1. The winner of the contest was, well, Spark.
If you’re not already familiar with the Yahoo streaming benchmark, check out the original Yahoo post for an overview.
Databricks made a few modifications to the original benchmark, all of which are explained in their own post:
-
Removing Redis from step 5
-
Generating data in memory for Flink and Spark; generating data via Spark and writing it to Kafka for Kafka Streams
-
Writing data out to Kafka instead of to Redis
All sounds fair, at least for Flink and Spark. We will note that the fact that Spark and Flink use in-memory data generation and KStreams goes through Kafka is itself a bias against KStreams.
We delayed investigating the benchmark results because we quite strongly believe that putting time and resources into an increasingly irrelevant benchmark is of no benefit to users. But we heard feedback from the community that input from a Flink perspective would be helpful, so we decided to take a closer look.
Issue 1: The Flink Data Generator
We started with the data generator, and it didn’t take us long before we found something concerning.
The initial data generator written by Databricks for Flink in the benchmark does a lookup in a linked-list data structure for every generated event. In simple, pseudo-Scala code, the original data generator used in the Databricks benchmark looked like this:
val campaigns: Seq[Campaign] = getCampaigns()
var i = 0
while (true) {
val campaign = campaigns(i % campaigns.length)
emitEvent(campaign.id, System.currentTimeMillis())
i = i + 1
}
The `Seq` type that is used for the campaigns here is not bad, per-se, but in Scala, it can be unclear what data structure is used underneath. Due to how `getCampaigns()` is written, we get a linked list in this case, which has O(n) access time, where n is the number of elements in the list.
This is extremely slow, and it doesn’t make sense to use this approach here.
A simple fix is to replace the `Seq` with an `Array`, which has constant access time. In other words, it’s very fast to do lookups of campaigns with such an approach. The fixed code looks like this:
val campaigns: Array[Campaign] = getCampaigns().toArray
var i = 0
while (true) {
val campaign = campaigns(i % campaigns.length)
emitEvent(campaign.id, System.currentTimeMillis())
i = i + 1
}
Note that the Databricks Runtime benchmark is using a built-in Spark “source” to generate data and map it to ads and campaigns, whereas the Flink generator was custom and handmade, hence the reason this bug was limited to the Flink data generator.
But we’ll note that the Spark data generator uses an `Array` of Campaigns to handle campaign lookup, just like our fixed Flink data generator.
We have let the Databricks team know about this issue, and they updated the post accordingly--the results you see in their benchmark at the time we first published this post (December 15, 2017) reflect this fix.
Issue 2: Object Reuse
There’s an execution configuration setting in Flink regarding object reuse. From the documentation:
enableObjectReuse() / disableObjectReuse() By default, objects are not reused in Flink. Enabling the object reuse mode will instruct the runtime to reuse user objects for better performance. Keep in mind that this can lead to bugs when the user-code function of an operation is not aware of this behavior.(Editor’s note: For Flink’s DataStream API, this setting does in fact not even result in reusing of objects, but only in avoiding additional object copying on the way, which happens by default as an additional safety net for users.)As you see, object reuse is disabled by default, which is meant to serve as a guardrail for users. But all performance-minded Flink users would enable object reuse--at large scale, and with very complex job topographies.
Simply put, it’s unrealistic to run a performance-focused Flink benchmark with object reuse disabled. It’s a configuration that hardly reflects a real-word, production approach to running Flink. And indeed, object reuse was disabled in Flink in the original Databricks benchmark.
The Benchmark Results, Revised
Now, time to rerun the benchmark.
We produced the following results on Databricks Runtime 3.4, which is Spark 2.2 with some 2.3 features included. Note that Databricks Runtime is a proprietary runtime and one that’s presumably optimized to support Apache Spark. We ran Apache Flink 1.2.1 because this is what Databricks used in the initial benchmark post.
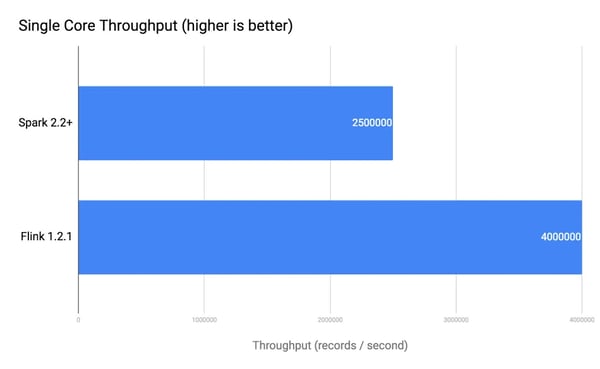
Below is a chart with what we found. To summarize,
-
Spark achieved throughput of 2.5 million records per second (in line with what Databricks reported in their post)
-
Flink achieved throughput of 4 million records per second
 Databricks flagged another potential Flink issue in their post related to the number of ads per campaign:
Databricks flagged another potential Flink issue in their post related to the number of ads per campaign:
"However, we noticed that we could achieve the 16M records/s throughput with Flink when we generated a single ad per campaign and not ten ads per campaign. Changing how many ads there were per campaign did not affect Spark or Kafka Streams’ performance but caused an order of magnitude drop in Flink’s throughput."Since fixing the data generation bug, we have not been able to reproduce this 10 vs. 1 ads Flink performance issue in any instance, and we recorded consistent performance from both systems when increasing the number of ads.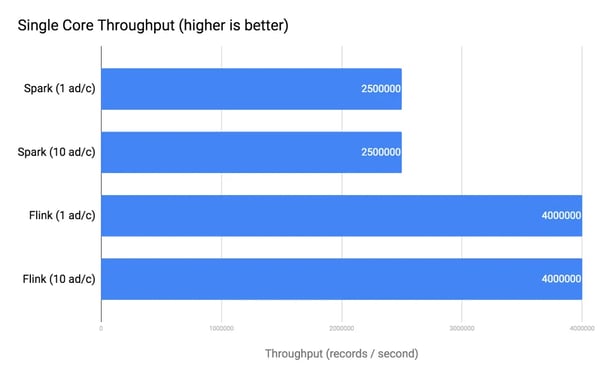
We created a Databricks notebook with our work (available here) that you can review if you'd like. Be sure to follow the setup instructions in the Databricks post. Note that we sometimes saw issues with Kafka Streams, and these cells (10-11) can be skipped if necessary. A start-to-finish run on a Databricks Community Edition cluster took us about 20 minutes.
In addition, we ran the same benchmark a number of times on a single node on our laptops and with newer versions of Flink (again, we benchmarked for this post with Flink 1.2.1, and the community released Flink 1.4.0 earlier this month) and recorded more or less the same results as what's in the graphs above.
On Benchmarking Best Practices
We’re not going to make any sweeping statements about what these results mean, because frankly, we don’t think it’s what matters the most. The whole purpose of this exercise was to demonstrate that benchmark results most often represent a narrow combination of business logic and configuration options (which might not even reflect real-world best practices), deployed in an artificial environment.
Why take seriously a result that’s so sensitive to bugs and simple config changes?
Here’s what does matter: The promotion of misleading benchmark results has real implications. It’s unfair to end users who evaluate software frameworks to make business-critical decisions, and it’s unfair to the contributor communities who are putting their time and effort into software projects.
So here’s our brief proposal for better benchmarking:
-
Benchmarks are fine, but let’s do away with benchmarketing. Benchmarks should be carried out by neutral third parties, or at the very least, with the involvement of stakeholders from all systems being benchmarked. The Flink community would have reviewed the Databricks benchmark before the results were published and widely promoted if given the opportunity, and we could have offered input on the data generator bug and the configuration best practice. Instead, the original Databricks result--which we consider to be illegitimate--was promoted in the market for months without consulting the Flink community first.
-
A stream processing benchmark should be representative of what stream processing actually is today. The modified Yahoo benchmark is like a "Word Count" for data streaming, as if stream processing was limited to being a tool to make simple batch analytics a little bit faster. While stream processing is indeed an ideal solution for real-time analytics, that's just one domain where stream processing has had a huge impact.
-
We’ve seen entire social networks built on top of Flink, not to mention fraud detection and trade processing applications in banking, or complex event generation and alerting in retail logistics.
-
Such applications present very different challenges--for example, complex data flow, elaborate temporal joins, very long sessions, very large state, or dynamically-changing operator logic. They interact with external services in complex ways, too.
-
-
As a consequence of (2), we suggest retiring the Yahoo streaming benchmark altogether. If we’re going to benchmark at all, let’s spend our time and energy on measures that reflect the present and future of stream processing, not the past. The Yahoo benchmark served a valid purpose two years ago, when stateful stream processing technologies were still young and were mostly used to compute real-time counters as part of a lambda architecture. The space has moved beyond that, and any common benchmark should reflect on how stream processing has progressed. For example, database benchmarks such TPC-H and TPC-DS contain a plethora of queries that try to capture different nuances of query execution. And while arguably, even those benchmarks have many deficiencies, at least they make an effort to be broad in scope. What would a database developer say to a benchmark consisting of a single SQL query?
Conclusion
The end users who build applications with stream processing frameworks are reliant on high-quality information--and the full context behind it--to make the best possible decisions on behalf of their organizations.
We in the stream processing space owe it to users to be transparent and thorough when comparing frameworks publicly. Let us all commit to this as one of our 2018 resolutions.

You may also like

Preventing Blackouts: Real-Time Data Processing for Millisecond-Level Fault Handling

Real-Time Fraud Detection Using Complex Event Processing

Meet the Flink Forward Program Committee: A Q&A with Erik Schmiegelow
