














In this post, we would like to shed some light upon Apache Beam, the new Apache Incubator project that Google initiated with us and other partners. We would like to highlight our involvement in Beam and how we see the relationship between Beam and Flink developing in the future. See also Google’s perspective on how Beam and Flink relate.
Our involvement with Beam started very early, when we created the Flink runner for (what was then) the Google Dataflow SDK. Very quickly, it became apparent to us that the Dataflow model (as published at the VLDB paper, and discussed in Streaming 101, Streaming 102, and Beam versus Spark) is the correct model for stream and batch data processing. We fully subscribed to Google’s vision to unify real-time and historical analytics under one platform by treating static data sets as streams which happen to have a beginning and an end. Taking a cue from this foundational work, we rewrote Flink’s DataStream API in Flink 0.10 to incorporate many of the concepts described in the Dataflow paper, moving away from the old Flink 0.9 DataStream API. We retained this API with Flink 1.0 and made it stable and backwards compatible.
As the Dataflow SDK and the Runners were moving to Apache Incubator as Apache Beam, we were asked by Google to bring the Flink runner into the codebase of Beam, and become committers and PMC members in the new project. We decided to go full st(r)eam ahead with this opportunity as we believe that (1) the Beam model is the future reference programming model for writing data applications in both stream and batch, and (2) Flink is the definitive platform to execute these data applications. As Beam is now taking shape, Flink is currently the only practical execution engine for Beam programs outside Google’s Cloud. As Tyler Akidau, Apache Beam PMC, puts it:
For Apache Beam to achieve its goal of pipeline portability, we needed to have at least one runner which was sophisticated enough to be a compelling alternative to Cloud Dataflow when running on premise or on non-Google clouds. As you can see from these tables, Flink is the runner which currently fulfills those requirements. With Flink, Beam becomes a truly compelling platform for the industry.
This is not merely an artifact of the Flink runner starting early. Flink and Beam are completely aligned in their concepts, which makes the translation of Beam programs to Flink jobs both straightforward and very efficient. With full support for concepts such as event time, watermarks, and triggers, and with the new features we are contributing to Flink, we believe that the superiority of the Flink runner will stick for the foreseeable future.
One question that remains is what is the relationship between Flink’s own native API (DataStream), and the Beam API? Will both of these continue to be supported, and is it confusing for developers to have two different APIs that in the end generate Flink jobs? Our committers at data Artisans will continue to fully support both the Flink DataStream API (which is, as of Flink 1.0, stable and backwards compatible), as well as the Beam API as it evolves for Beam programs that run on Flink. The differences between the two APIs are largely syntactical (and a matter of taste), and, we are working together with Google towards unifying the APIs, with the end goal of making the Beam and Flink APIs source compatible. We believe that the two communities can learn from each other, and we encourage users to use either of the two APIs to implement their Flink jobs for stream data processing. With the native Flink DataStream API you get an already mature and backwards-compatible API, built-in libraries (e.g., CEP and upcoming SQL), mature tooling and connectors, key-value state (with the ability to query that state in the future), and an API which fully utilizes all the features of Flink’s powerful engine. With the Beam API, you get the option of portability down the line as more Beam runners mature.
API, model, and engine
To clarify our points above, we would like to explain what we mean by choice of API, choice of programming model, and choice of execution engine. Currently, Beam has three available runners: the Google Cloud Dataflow proprietary runner by Google, as well as the Flink and Spark runners, included in the open source Apache Beam project. Let us look at this ecosystem, and add Flink and Spark themselves with their native APIs, as well as Storm:
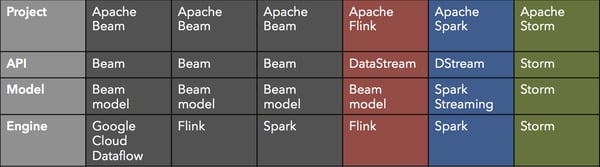
The table has four rows: project, API, model, and engine. For example, Apache Storm comes with the Storm API which implements the Storm model and is executed in Storm. Apache Beam comes with the Beam API which is portable, meaning that it can be executed with either of the three aforementioned runners.
Perhaps the only non-straightforward row, and yet the most important is the “model”. While the programming model is somewhat hidden and less tangible than an API (you do not program it directly), the choice of model dictates both the feel and the capabilities of the API, as well as the architecture of the engine. The choice of programming model is perhaps the most important one to make: transitioning from one API to another is much easier when the underlying model is the same. You can think of the programming model as the semantics of the program, and the API providing the syntax above.
While the models that Spark Streaming and Storm follow are very different from the Beam model, the Flink DataStream API included in Apache Flink™ faithfully implements the Beam model with a fluent and functional approach to API syntax on top. While Flink DataStream programs cannot run directly on Beam, they use the same underlying concepts, so porting code from one to the other is more of an exercise in syntax, without needing to re-think the application logic a lot. Even more, Google and data Artisans are working together to make the two APIs semantically equivalent, ironing out any minor inconsistencies. This means that users of either API can switch with relatively low effort. Our long term goal is to make the Beam and Flink DataStream APIs source-compatible, so that programs written in one can natively run on the other with no code changes.
If you choose to invest in the Beam programming model now, you have two options:
-
Use the Flink DataStream API in Java and Scala
-
Use the Beam API directly in Java (and soon Python) with the Flink runner
We recommend option 1 to users that want to get started immediately, using an already mature and backwards-compatible API, access to libraries (e.g., the existing CEP library and the upcoming SQL functionality), mature tooling and connectors (e.g., to Kafka), as well as an API that fully and natively utilizes all the existing and upcoming features of the Flink engine. In addition, we recommend the Flink native API for use cases that use Flink’s key-value state abstraction, and in the future Flink’s facilities for querying that state. We recommend option 2 to users that want to keep the option of engine portability (as other Beam runners progress).
To back these claims up, we took the example of the recent blog post that compared Beam and Spark Streaming from a programming model perspective and implemented that program in Flink’s native API. Our code can be found in this repository.
In a recent blog post, Google compared Beam and Spark Streaming from a programming model perspective. They took a mobile gaming scenario, and implemented several use cases in Beam and Spark Streaming, focusing their analysis on how well are the following concerns separated in the code:
-
What results are calculated? Sums, joins, histograms, machine learning models?
-
Where in event time are results calculated? Does the time each event originally occurred affect results? Are results aggregated in fixed windows, sessions, or a single global window?
-
When in processing time are results materialized? Does the time each event is observed within the system affect results? When are results emitted? Speculatively, as data evolve? When data arrive late and results must be revised? Some combination of these?
-
How do refinements of results relate? If additional data arrive and results change, are they independent and distinct, do they build upon one another, etc.?
See Streaming 102 if you’re unfamiliar with these questions and why they’re important. The code is color-coded using the above colors. If the colors are well-separated, these concerns are nicely separated, whereas if the colors are mixed all over the program, they are not. In both the Beam and native Flink APIs, these concerns are nicely separated:

Note that the Flink code uses a custom trigger implementation (EventTimeTrigger), which is not yet included in the Flink repository, hence the syntax might change in the future. This does not affect the main point, namely the separation of concerns shown as separate colors. We are working on contributing this functionality back to Flink.
Conclusion
We firmly believe that the Beam model is the correct programming model for streaming and batch data processing. We encourage users to adopt this model for their future data applications, embodied in either the Beam API itself or the Flink DataStream API. Further, we believe that Flink, with its current features and roadmap, is currently the most advanced open source stream processor, and at the same time the only practical solution for deploying Beam programs in production on on-premise or non-GCP clusters. We are looking forward to continue pushing the envelope in stream processing and enabling enterprises to use stream processing technology for their data applications.

You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
