













Hackathons at Ververica
At Ververica we have a long-standing tradition of Hackathons. In fact, some widespread and very relevant features and efforts in Apache Flink and Ververica Platform originated from Hackathons. These include:
- The State Processor API
- Akka-free runtime
- Job Submission via REST
- Apache Flink Benchmark Infrastructure
- Migration of the Documentation from Jekyll to Hugo
Beyond Ververica, Hackathons have become an essential part of what is known as ‘engineering culture’. Hackathons serve several purposes, namely:
Driving Innovation
The invitation to a Hackathon immediately triggers the question “What will I work on?” and next “What would make sense?”. It is not uncommon that some highly requested features, that still somehow have never made it into the team objectives, are finally kicked off during a hackathon. The same applies to crazy ideas. Hackathons are truly about out-of-the-box thinking. Projects that are based on crazy ideas might not always be successful but they are getting us close to something that can be tested.
It's hardly ever the goal to create production-ready features. It is ok to just make things work and learn from them.
Cleaning up the Backyard
Hackathons not only accelerate innovation, but they also help us clean up the backyard. Our engineers are motivated to choose both topics that go beyond their current tasks, as well as topics that increase productivity by removing or decreasing the pain from outdated or slow infrastructure. Tasks like upgrading frameworks — which are usually hard to estimate at first — are sometimes kicked off with a prototype during a Hackathon.
Spreading Knowledge
The obvious way to gather knowledge during Hackathons is by working hands-on with new technologies. But there’s way more. Participants not only test new frameworks, new programming languages, and new libraries; they also tap into components which they are usually not involved with day-to-day. During Hackathons, there is room and time to discuss and teach. When doing a Hackathon with mixed teams (We highly recommend this) relationships are built and knowledge is shared across teams.
Product Discovery
Hackathons are the perfect place to perform product discovery: build a quick prototype and get feedback immediately in the final presentation. As the organizer of a Hackathon, you need to make the results count by documenting them properly and making them accessible company-wide.
A different state of mind
A Hackathon provides the perfect environment for engineering teams to come together and work on specific projects or features for a limited period of time. This provides the necessary flexibility, ease of operation, and team collaboration that can bring everyone to see things from a different perspective, and think ‘outside the box’. This enables understanding what processes and activities make sense and add to the team’s productivity and overall organization, but also allows re-evaluating what might cause additional overhead to the engineering team, preventing its day-to-day operation and productivity.
Hackathons also come with a very real option to fail. Your project might be going nowhere. That’s fine. The project might never make it to production. That’s also fine. Not having any pressure, and being yourself, setting up your own expectations, can be really relieving.
… and if it is none of the above it’s sometimes just experiencing the sheer pain of working on the idea you have romanticized for years.
The Ververica Hackathon Recipe
- Guiding thoughts, but open topics in general
- A hub that documents the ideas and projects
- Making all projects experienceable
- A kick-off to present the ideas and why they have been chosen to get into the state of the Hackathon
- No distraction (ban all other meetings for that time)
- Social gathering to discuss what happened
- A review session
- Presentations that contain the outcome, key learnings, and next steps
- Not too serious awards (e.g. “Oh, that’s interesting”, “Feel ya pain”, “Funky presentation”)

Hackathon Project Deep-Dive
Let’s take a closer look at three projects from our last Hackathon.
antiskew®
Who worked on this?
Anton, Piotr
What is this about?
Apache Flink splits the keyspace into a fixed number of key groups. The keys are assigned to these key groups via consistent hashing. The key groups in turn are distributed among the parallel instances of each subtask in the form of continuous key group ranges. For example, task 1 would handle key groups 1 to 2, and task 2 would handle key groups 3 to 4.
What’s the problem we are trying to solve?
Key Group Ranges are statically assigned and have the same length. This means that each subtask receives the same number of keygroups. When the data is skewed many records will fall into just a few key groups. In turn, some sub-tasks need to do all the work while other sub-tasks are almost idle. This situation is depicted in Figure 2 (top). Data skew reduces max throughput, but it can also increase end-to-end checkpointing and recovery time as it can cause skew of operator state size.
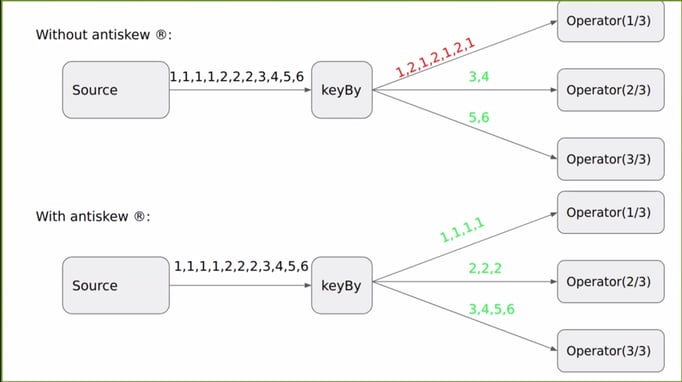
Figure 2: Key Group Assignment without (top) and with (bottom) antikskew
How did we solve it?
Antikskew® dynamically adjusts the key group ranges assigned to each task based on the real-life distribution of the keys. In the example in Figure 2 (bottom), key groups 1 and 2 receive dedicated tasks, while key groups 3-6 are all handled by the third task. The benchmarks taken during the hackathon show significant throughput improvements, not even only in high skew scenarios.
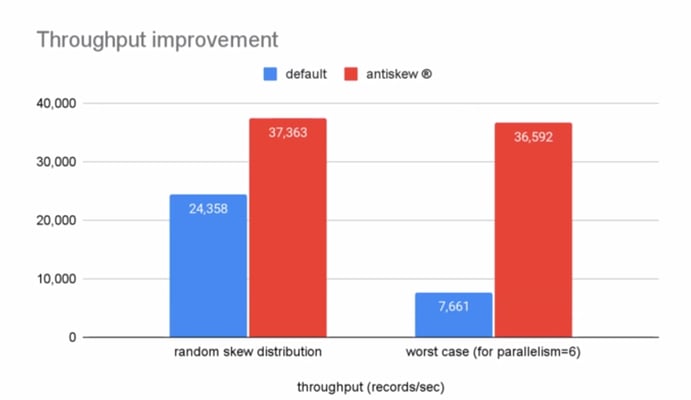
Figure 3: Throughput with and without antiskew®
What happens next?
With the prototype in place, we’ve created a Flink Ticket to track a future production-level implementation of this feature. If you are interested in this, please watch or comment directly on the ticket.
Apache Flink CI on GitHub Actions
Who worked on this?
Matthias, Martijn, Mika, Nicolaus
What is this about?
This is about the Apache Flink CI. It runs on Azure Pipelines and is quite comprehensive:
- It builds Apache Flink for Java, Scala, and Python including all of its connectors.
- It executes unit tests as well as end-to-end tests.
- It performs different kinds of verification e.g. for API compatibility, software licenses.
- It builds the documentation and performs checks on those.
- It is triggered on PRs and pushes on master as well as on a cron schedule.
- We use self-hosted runners.
What’s the problem we are trying to solve?
This works quite well in general and checks all the boxes, but we’ve also seen that it introduces quite a bit of friction both for (new) contributors and the team maintaining the infrastructure.
- Understanding Azure Pipelines and how Apache Flink is using it is an additional hurdle for new contributors to the project. Specifically, in order to run CI on a fork, contributors initially need to fill out a form to request free machine time from Azure.
- Azure Pipelines requires writing access to the GitHub repository, which we cannot provide for apache/flink. So, CI actually runs on a fork of apache/flink, and results are mirrored back to the original repository.
How did we solve it?
The idea is to migrate the CI/CD to GitHub Actions. This would work for any contributor and fork, out-of-the-box, and integrate seamlessly with the existing infrastructure. At the end of the Hackathon, the team had a working prototype.

Figure 4: Apache Flink GitHub Actions Prototype
Big thanks to the Apache Airflow Community, specifically Ash Berlin-Taylor, who adopted GitHub Actions before and provided very helpful tips to use during the whole hackathon and beyond.
What happens next?
We just published a proposal for the migration on the Apache Flink dev mailing list.
Apache Flink Architecture Tests with ArchUnit
Who worked on this?
Ingo, Chesnay
What is this about?
Apache Flink has become a large and complex project. It now consists of more than 2 million lines of code and more than 60 Maven modules. More importantly, the number of contributors and committers is continuously growing, too. Keeping this codebase maintainable and evolvable is critical to the long-term success of the project.
As with many projects Apache Flink’s architecture has matured over time. In particular, the community has defined the responsibilities of the different building blocks (classes, packages, modules) more clearly and agreed on how these should interface with each other. In other words: over time the community defines Apache Flink’s internal architecture more and more explicitly.
What’s the problem we are trying to solve?
What’s challenging is that such conventions can sometimes be difficult to communicate to the entire community, to document, or to properly define. And even if they are documented and well-defined, which they often are, they are easily forgotten or just not known to every contributor and/or reviewer.
In addition, there is a large existing codebase and there is no clear process on how to align existing code to new architecture conventions.
How did we solve it?
The idea is to codify these architecture rules in the form of JUnit tests (using ArchUnit) that can be executed on each CI run. This way, the rules are clearly defined and the whole codebase is checked on each PR for violations. To give you an idea of how this looks like, here’s an example rule which asserts that all APIs should be annotated with stability annotations.
@ArchTest
public static final ArchRule ANNOTATED_APIS =
freeze(
javaClassesThat()
.resideInAPackage("org.apache.flink..api..")
.and()
.resideOutsideOfPackage("..internal..")
.and()
.arePublic()
.should(
fulfill(
areDirectlyAnnotatedWithAtLeastOneOf(
Internal.class,
Experimental.class,
PublicEvolving.class,
Public.class,
Deprecated.class)))
.as(
"Classes in API packages should have at least one API visibility annotation."));Figure 5: ArchUnit Rule testing Apache Flink API stability annotation
Existing violations can be frozen and fixed over time, but no new violations can be introduced. In this context, we’ve discovered roughly 1,000 violations of the eight rules that were implemented initially.
This project was previously discussed on the mailing list, too.
What happens next?
It’s one of these examples where the Hackathon was used to push existing side projects over the finish line. The architecture tests are now merged into Apache Flink and run in CI. There is a README that outlines how to extend the test coverage of this framework.
Wrap Up
This was just the tip of the Iceberg. There were many more projects worth featuring: from a RocksDB Autotuner to a prototype for Migrating Flink from Maven to Gradle. The latter has been a topic at almost every hackathon so far, but it's a hard nut to crack.
It was fun, thought-provoking, and overall a nice break from our day-to-day work with customers and the Apache Flink community. We are looking forward to the next Hackathon in April. Until then we leave you with one of the visual highlights of this hackathon.
Figure 5: Acwern: Apache Flink Visualization Framework based on Phaser 3.
If you read this very long post till the very end it looks like you are really into hackathons.
We ❤️❤️❤️ engineers who are into hackathons. You might want to have a look at the engineering roles on our careers page.
You may also like

Zero Trust Theater and Why Most Streaming Platforms Are Pretenders

No False Trade-Offs: Introducing Ververica Bring Your Own Cloud for Microsoft Azure

Data Sovereignty Is Existential Most Platforms Treat It Like a Feature
