













The Apache Flink community is showing no signs of slowing down, with rapid growth expected to continue into 2023. Currently, the number of stars on the Apache Flink GitHub repository has exceeded 20,000.
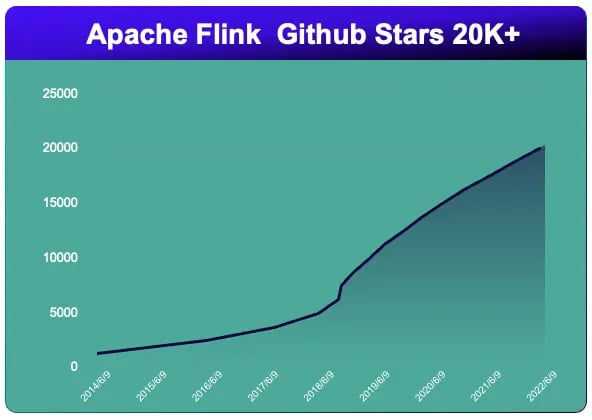
The total number of contributors has increased to over 1600.[1]:
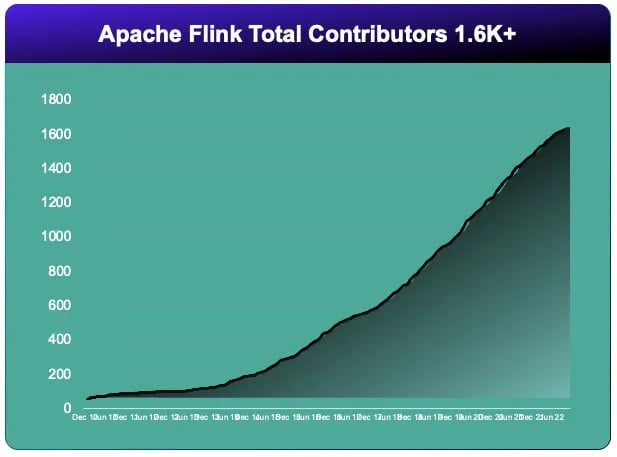
The number of monthly downloads surpassed 14 million.
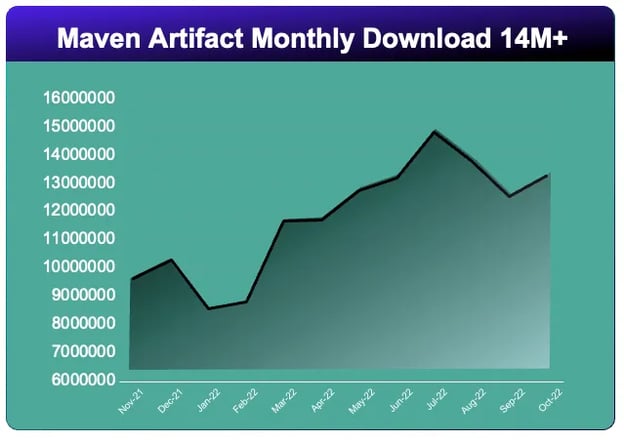
The Pull Request history depicts a vibrant and engaged community, with the top 3 Pull Request creators coming from China (45.5%), USA (17.3%), and Germany (10.1%).
In 2022, Apache Flink released two minor versions with incredible improvements and new features:
- cleaner checkpoint and savepoint semantics design
- watermark alignment
- log-based incremental checkpoint
- hybrid shuffle mode
- adaptive batch scheduler
- SQL related enhancements including new syntax support and optimization
- Flink Table Store
- PyFlink improvement
- Flink ML


With these two releases, Flink has further solidified its position as a unified stream and batch processing platform. At the same time, Flink is moving towards a new and ambitious vision: the streaming data warehouse. You can find more information in the Flink 1.15 Release Announcement and the Flink 1.16 Release Announcement.
In addition to our numerous contributions to Apache Flink, Ververcia had a pretty remarkable 2022. We have been restructuring our product development and released a new Enterprise Flink Kubernetes High Availability (HA) module. This feature supports JobManager failover with significantly improved performance compared to VVP Kubernetes HA. We completely redesigned our technical infrastructure in order to facilitate the transition from Ververica Platform (VVP) to Ververica Cloud (VVC), enabling us to offer not only on-premise deployment, but also a cloud-based SaaS solution. Users can use our out-of-the-box service with a fully managed cluster or bring their own Kubernetes cluster using our semi-managed service. Thanks to our multi-cloud architecture, users don't need to transfer their data back and forth among different cloud providers, making our service vendor-independent. In short, we are working on something big and will be launching it soon, so stay tuned!
There is a growing interest in Apache Flink, and there are many insightful articles available that detail its technical design and implementation. These pieces provide an informative look into the inner workings of Flink and explain why it is so successful and efficient. Ververica, the company that created Flink, provides a wealth of resources on their website, including blogs and tutorials, with more to come. Feel free to explore these resources to gain a better understanding of Flink and its capabilities as well as provide us with feedback on what you would like to see
This post will look back onto the many milestones and changes that occurred in 2022 and how Ververica fits in. We will look at things from the user's perspective and ponder why Flink contributors have put so much effort into implementing these features and answer questions such as: What's in it for me as a user or developer? Should I start using Flink if I haven't already? Should I upgrade to the new versions if I have an older version of Flink running in production?
We will take a deep dive into each one of the following user-oriented scenarios:
- Engine: make Unified Data Processing faster, more robust, and efficient
- Data: from compute engine towards Streaming Data Warehouse
- AI: more solid online learning toolset
Engine: Better Unified Data Processing
Unified stream and batch data processing is the foundation of Flink, and has helped make it one of the most attractive engines in the industry. Flink continues to innovate and evolve, building on its strong foundation and staying ahead of the curve in the rapidly changing world of data processing. In 2022, Flink saw significant improvements to its engine, making it faster, more reliable, and more efficient. Particularly noteworthy are the enhancements to checkpointing and unified data processing.
Checkpoint Enhancement
Let's start with semantic improvements. First of all, Flink finally clarified the checkpoint and savepoint semantics clearly. Savepoints are in the control of users and should be used for backing up and updating Flink jobs. Checkpoints should only be used by Flink internally to offer fault tolerance guarantees through fast failover.
Previously, users were keen to use checkpoints as savepoints to maintain their Flink jobs, because savepoints were not as performant. Flink has solved the issue by introducing native and incremental savepoints. It is recommended that users opt for the native format and RocksDB state backend since this will enable savepoints to be generated quickly, which is sufficient for maintaining Flink jobs. It is important to note that when resuming jobs from savepoints, the NO_CLAIM mode will be applied by default, thus all files are controlled by the user.
If any task had already been completed, Flink could not take checkpoints semantically, which caused issues when dealing with bounded sources. One scenario was that, in jobs with mixed bounded and unbounded sources, no new checkpoint would be created if the bounded part was completed. In case of failure, the unbounded part would have to reprocess a large amount of data because the last checkpoint had been taken a long time ago. Another scenario was related to data lakes, where two-phase-commit sinks were used to ingest data into the downstream data lake in an end-to-end exactly-once manner. Data would be written to temporary files in the first phase and would only be committed in the second phase after a checkpoint was completed. For bounded jobs, which are the most common case for data lake usage, it would be impossible to commit the last piece of data because of the lack of a checkpoint. To solve this issue from the ground up, Flink has extended the semantic of the finishing process by decoupling the "finishing operator logic" and "finishing tasks". All tasks will first finish their execution logic as a whole and then each task can wait for the next checkpoint individually.
Now that the semantics of checkpoints and savepoints have been clarified, Flink has focused more attention on checkpoints, which are fully controlled by Flink. Checkpoints are a crucial concept in Flink, since they are used to support stateful stream processing and provide fault tolerance through recovery jobs that use checkpoints. Users often want to take checkpoints frequently and at a low cost in order to ensure the stability and reliability of their pipelines. As a result, Flink has developed a range of features and tools to support efficient and effective checkpointing in Flink pipelines. However, in a real production environment, the checkpointing mechanism often faces challenges, especially with large and complex workloads.
When the job is under a lot of pressure, such as from data skew or network buffers becoming congested, it can be difficult to trigger checkpoints in a timely manner. To address this issue, Flink introduced unaligned checkpoints, which can speed up the propagation of barriers. Flink also provided the convenient default behavior: jobs will start with aligned checkpoint and automatically switch to unaligned checkpoint when the barrier aligning time reaches a certain threshold. One downside of unaligned checkpoints is that they will increase the size of checkpoints. This can lead to higher storage and bandwidth costs, and can make it more difficult to manage checkpoints in large and complex pipelines. Therefore, buffer debloating is introduced as another option to speed up the propagation of barriers. With buffer debloating enabled, upstream tasks will only buffer a limited amount of data that can be processed by downstream operators within one second. This is a trade-off between maximizing operator performance and minimizing buffered data. By default, buffer debloating is enabled to help improve the performance and efficiency of the pipeline.
Even if checkpoints can be triggered, there is another challenge: the amount of state data that needs to be transferred from local storage to a remote storage system, and the time it takes to upload this data, can be difficult to control. As a result, users may find that checkpoints are not generated within the expected time, which can have a significant impact on the stability of the service. This can be a major issue, especially in large and complex workloads where the amount of state data can be significant and the need for timely checkpoints is critical. That is where log-based incremental checkpoints come into play. Beside the state table, a new state changelog has been introduced, which can be persisted in a very fine-grained manner. This allows Flink to save only the changes that have occurred, rather than saving the entire state of the pipeline, which can be much more efficient. Log-based incremental checkpoints are particularly useful in cases where the state of a pipeline is changing rapidly and the amount of data that needs to be saved in each checkpoint is large. By only saving the changes that have occurred, log-based incremental checkpoints can help Flink to maintain the stability and reliability of a pipeline even in the face of high volumes of data and rapid state changes.
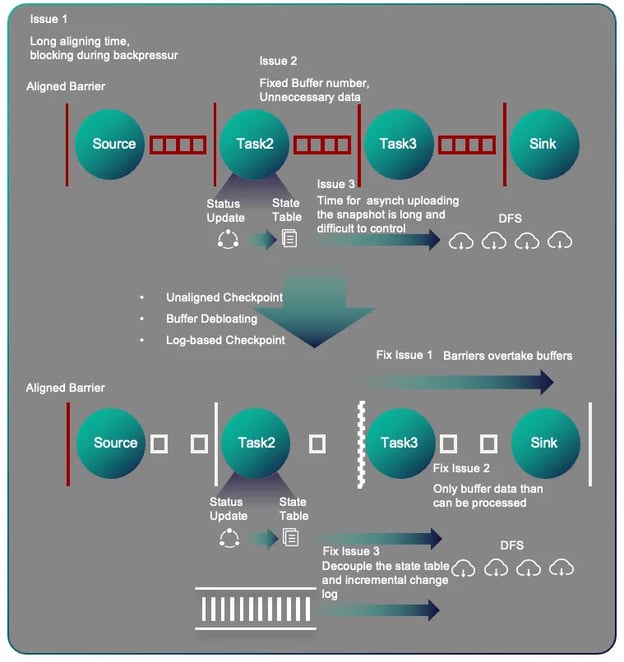
Speaking of data skew, as a checkpoint related topic, there are many best practices to prevent it. Flink offered Watermark Alignment, which addresses the issue from the perspective of the engine. If a split/partition/shard or source process records too fast, compared to other inputs, it can increase watermarks faster than other inputs. This means that all records emitted by the fast input will need to be buffered in the downstream operator state because the minimal watermark from all inputs is being held back by the slower input. This can lead to uncontrollable growth of the operator's state. By enabling watermark alignment, Flink will check watermarks drift between different inputs that belong to the same alignment group internally and pause consuming from the input that generated the watermark too far ahead of the rest. Note: Flink 1.16 only supports watermark alignment across tasks of the same source and/or different sources. Supporting aligning splits/partitions has been developed during 1.16 release and unfortunately didn't catch the release train. It will be available in Flink 1.17.
Note: If you are using Flink SQL, The blog How to write fast Flink SQL will show you more deep knowledge about how to optimize your SQL job and prevent data skew at SQL job level.
With the implementation of new technologies, Flink has developed a new generation of distributed checkpointing mechanisms. These mechanisms are designed to support efficient and effective checkpointing, and to help ensure the stability and reliability of stream processing applications.
Unified Data Processing Enhancement
Let us now focus on another essential and performance-related technology - shuffling. Based on the unified stream and batch processing concept, Flink 1.16 introduced the innovative adaptive Hybrid Shuffle technology.
Previously, Flink offered two different shuffle technologies used in streaming or batch execution mode individually.
- Pipeline Shuffle used in streaming execution mode: The upstream and downstream tasks are directly connected through the network, and the data is transmitted through the memory and the network without disk IO, resulting in a better performance.
- Blocking Shuffle used in batch execution mode: The upstream task first writes the intermediate data to the disk or other storage services, and the downstream reads the intermediate data from the disk or storage services. Disk IO is required, and the performance is slightly poor.
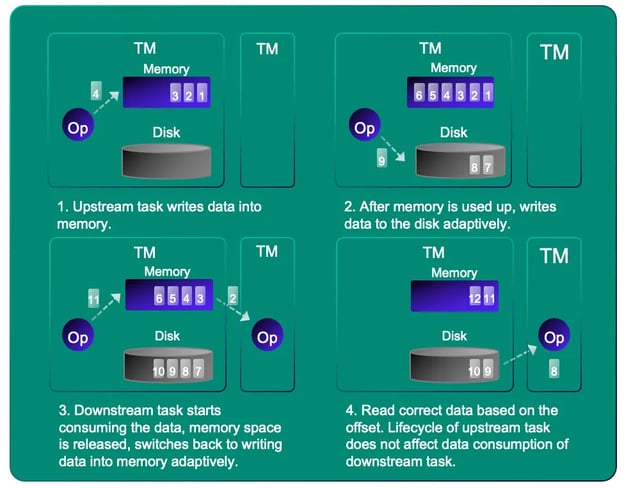
Pipeline Shuffle provides better performance, but it requires more resources because all interconnected tasks must be launched at the same time. It is tempting to use Pipeline Shuffle in batch execution mode as well, but this can be challenging in a production environment where there is no guarantee of having enough resources. When multiple tasks compete for resources, there may even be deadlocks. To address this issue, Flink introduced the Hybrid Shuffle. It combines the advantages of Blocking Shuffle and Pipelined Shuffle. Streaming shuffle will be used only when resources are sufficient and tasks connected to each other can be launched simultaneously. It will fall back to batch shuffle at the same time when resources are insufficient. In this way, resources will be used more effectively for shuffle acceleration. The first version of Hybrid Shuffle was released in Flink 1.16. The preliminary evaluation shows a good performance improvement compared with the traditional Blocking Shuffle. In the subsequent releases, the community will further improve and optimize this technology [2].
The scheduler is another key component in Flink. In 1.15, Flink introduced the Adaptive Batch Scheduler, which can automatically determine the parallelisms of job vertices for batch jobs based on the amount of data each vertex needs to process. This feature is user-friendly in two ways: it is fine-grained and adaptive, allowing for efficient resource consumption and good performance, and it is easy to use, relieving users from the need to tune parallelism manually.
By leveraging these technologies, Flink can offer users a powerful and robust tool for building unified stream and batch data pipelines and processing large streams of data in real time.
Data: From Compute Engine towards Streaming Data Warehouse
Offering exactly-once data consistency of stateful streaming computing at the framework level while maintaining high throughput and low latency is the key to Flink becoming a new generation of stream and batch computing engine. Since then it has been used in many different areas.
Entering the area where data warehouses were the norm, a new challenge arose, since the majority of users in this space were more adept with SQL than with Java/Scala. In order to improve users' development efficiency, Flink SQL was released in 2019. Comparing the flexibility with the complexity offered by DataStream API, SQL is a simple declarative language. It is valuable across many different roles, e.g. data engineers, analysts, scientists, product managers, and used widely in many different industries. From an engineering's perspective, SQL is a great choice to apply the single responsibility principle (SRP). Users are relieved from low-level technical complexity and can focus on their own business model. On the other hand, platform engineers can concentrate on optimizing the query without needing to understand the business logic.
Note: If you are interested in learning more about Flink SQL, you may want to read the blog post Apache Flink SQL: Past, Present, and Future. This blog post provides an overview of Flink SQL, including its features and capabilities, and discusses how it will play a key role in the future of Flink.
In 2022, Flink put extra effort on SQL enhancements:
- SQL version upgrades - Keep the same query up and running after upgrades by leveraging JSON plans.
- New SQL Syntax support - CAST/Type, JSON functions, USING JAR, CTAS, ANALYZE TABLE, you mention it.
- SQL Gateway - As an extension and enhancement to SQL Client, SQL Gateway supports multi-tenancy and pluggable API protocols. It can be integrated with external services or components.
- Hive Compatibility - Support HiveServer2 Endpoint and reached 94.1% compatibility for Hive 2.3.
- Join Hint - BROADCAST, SHUFFLE_HASH, NEST_LOOP, etc.
- Enhanced Lookup Join - Cache support, asynchronous mode, and retry mechanism.
- Dynamic Partition Pruning - Partition pruning information will be collected at runtime based on data from other related tables, thus reduceing unnecessary partition scan IO for partitioned tables. The use of Dynamic Partition Pruning has been validated with the 10 TB dataset TPC-DS to improve performance by up to 30%. A very useful improvement, especially for Flink SQL jobs that use star-schema to build complex data models.
Data ingestion is another important topic for building an end-to-end data processing pipeline. As we already know, Flink is essentially a distributed streaming data processing engine with a rich connector ecosystem that can connect to various mainstream storage systems including MySQL family, PostgreSQL, SQLServer, DB2, Oracle, MongoDB, TiDB, PolarDB, and OceanBase. It has an excellent distributed architecture that supports mechanisms such as distributed checkpointing which can offer exactly-once data consistency guarantees, stream batch unification which can cover both initial and incremental load.
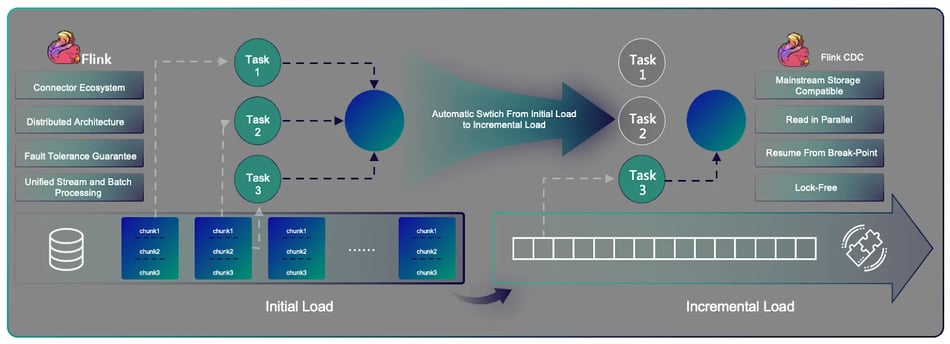
Since Flink already possesses all features typical data ingestion scenarios required, Flink CDC was born to leverage those Flink built-in features and became a data pipeline connecting different storages. Flink CDC 2.0 was released this year. One unique feature Flink CDC provided is that, by leveraging the unified batch and stream architecture, developers can use one SQL and run one Job to perform both initial load and incremental load. During the initial load phase, it breaks the initial snapshot into chunks and loads them in parallel with multiple tasks to increase throughput. After switching to the incremental load, only one task will be used to read the binlog. The switch between initial load and incremental load will be done automatically and a lock free algorithm will guarantee the data consistency. Based on Flink's distributed checkpointing mechanism, data integration can be resumed, which significantly improves the reliability.
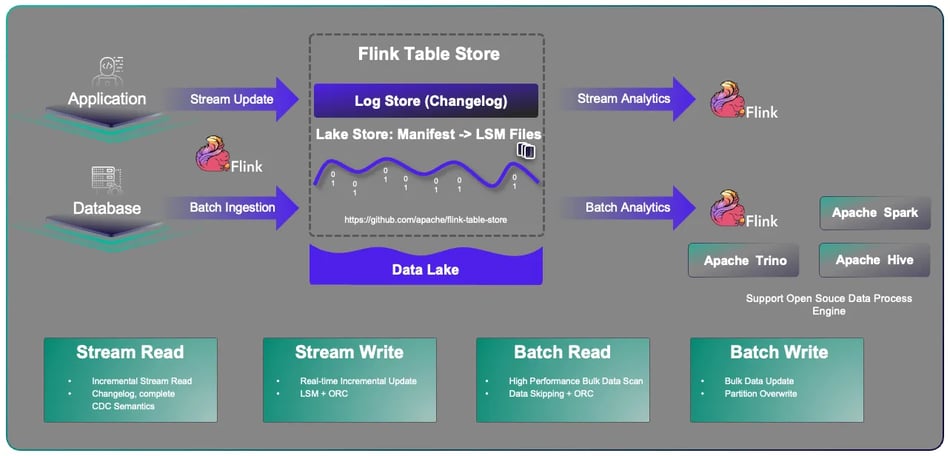
Even though Flink introduced the simple declarative language Flink SQL for users to write jobs and provided Flink CDC to ingest data, users still struggled with the complexity at the storage layer. Depending on the business requirements, different stream or batch storages need to be integrated into the pipeline. Each of them has their own advantages and disadvantages. It is difficult to query the data and find insight in stream storages, and batch storages have high data latency. Flink had an opportunity to provide a unified stream and batch storage abstraction to alleviate this complexity for users. This will end up with the new Streaming Data Warehouse. To address this issue, Flink launched the Flink Table Store sub-project this year. It follows the principle of separating compute and storage, allowing data to be stored in the cloud. It enables low-latency real-time data write-in and read-out, as well as low-latency analytics query execution. Underneath the storage abstraction there are two concrete components. The first one is the LakeStore which is focusing on the batch mode and analytics, it applies the classic LSM, ORC, and other indexing technologies, suitable for large-scale, high-performance data update and reading. The second one is called LogStore which takes care of the streaming mode. It stores table changes into change logs with complete CDC semantics. Sub streams can use Flink SQL to subscribe changes for further real time data processing. In addition to connecting to Flink by default, it can also connect to mainstream open source computing engines such as Spark, Hive, and Trino. Two versions of Flink Table Store have been released this year. Overall, Flink Table Store provides better performance than Hudi. The update performance is significantly better, and the query performance is significantly better than Hudi's MOR mode and almost as good as Hudi's COW mode.
AI: More Solid Online Learning Toolset
Previously, Flink had a Flink ML module that was a set of machine learning algorithms based on the DataSet API. After restructuring the architecture with unified stream and batch processing, the original Flink ML was discarded along with the DataSet API. This year, Flink relaunched Flink ML as a new sub-project based on the DataStream API, and has released two versions so far. The core of machine learning algorithms is the iterative processing framework. In line with the Flink concept, Flink ML provides a unified stream and batch iterative processing framework. It supports online training on unbounded streams, training recovery from interruptions, and high-performance asynchronous training. Dozens of algorithms have been developed to cover AI scenarios such as feature engineering, online learning, regression, classification, and evaluation. It is expected that more companies and developers will participate in the future and contribute additional classic machine learning algorithms to Flink ML, allowing Flink's excellent processing power to play an even greater role in machine learning scenarios.
The Python part of Flink ML relies on PyFlink. In this year, PyFlink made significant progress. The new "thread" mode was introduced, which allows Python DataStream API, Python table functions, and user-defined Python functions to be executed in the Java virtual machine (JVM) via the Java Native Interface (JNI) instead of a separate Python process. Benchmarks show that throughput can be increased by 2x in common scenarios, and processing latency is reduced from several seconds to microseconds. The Python DataStream API has also been improved significantly and now supports most common connectors and formats.
Ververica Platform: The Best Place to Learn Flink and Run Enterprise Flink Jobs
While we use Flink extensively, we have found that one of the biggest challenges is that users often have a deep understanding of their domain but lack expertise in low-level big data technology. It is not practical for businesses in diverse industries to maintain an engineering team with a deep understanding of Flink, as each company has its own objectives and outlook. To address this challenge, we created Ververica Platform and training curricula to educate users and help them get things done more efficiently.
Ververica Platform is an integrated platform for stateful stream processing and streaming analytics powered by Apache Flink. We have designed Ververica Platform to meet the needs of organizations at different stages of stream processing adoption. The Community Edition, which is free to use, is intended for developers, engineers, data scientists, and data/business analysts who want to learn and experiment with Flink. The Stream Edition (Enterprise Edition) offers additional enterprise features such as security, high availability, and auto-scaling, making stream processing infrastructure easier to manage, safer and more scalable.
In Conclusion
With the rapid pace of development in 2022, we are pleased to see significant contributions and achievements in engine, data, AI, and many other areas of Flink. We would like to express our gratitude to the Flink community for all their efforts in advocating Flink at Flink Forward and Flink meetups, and disseminating knowledge especially throughout the Covid pandemic. The cooperation and contributions from around the world are what make Flink successful.
Our mission at Ververica is to make Flink easy to use at a low cost. We want to especially thank our customers for providing valuable feedback and look forward to working even more closely with them in the future.
[1] None distinct, it is different from the calculation of Github contributors.
[2] Hybrid Shuffle is an experimental feature and has some limitations. It is by default not activated.
You may also like

Zero Trust Theater and Why Most Streaming Platforms Are Pretenders

No False Trade-Offs: Introducing Ververica Bring Your Own Cloud for Microsoft Azure

Data Sovereignty Is Existential Most Platforms Treat It Like a Feature
