














Flink Forward Asia (FFA) is a technical summit officially authorized by the Apache Software Foundation and hosted by Ververica. It is currently one of the largest Apache top-level project conferences in China and an annual event for Flink developers and users. Due to the ongoing COVID-19 pandemic, the summit was held online again this year. The award ceremony for the 4th annual Real-time Compute for Apache Flink Challenge was also held at the summit. A total of 11 teams out of 4346 participating teams were selected to receive the awards after competing in various levels.
As usual, the FFA conference summarized the development of Apache Flink in the past year. In 2022, the Apache Flink community continued its rapid growth:
- the number of Github stars exceeded 20,000
- the total number of code contributors exceeded 1,600
- the monthly downloads exceeded 14 million
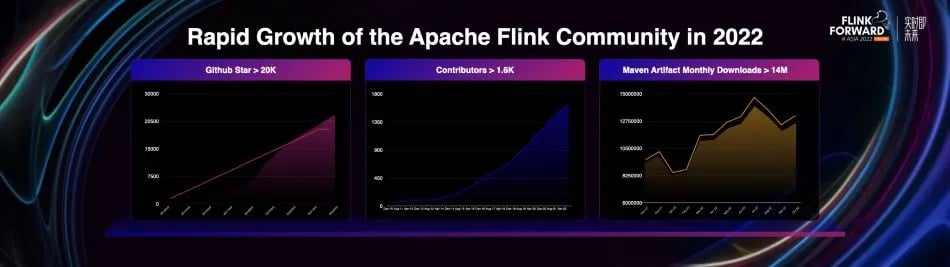
The development of the Apache Flink China community is particularly strong:
- According to statistics from ossinsight.io, 45% of all PRs of the Apache Flink project are from Chinese developers.
- The official WeChat account authorized by the Apache Software Foundation and managed by the Apache Flink PMC has published 130+ technical articles in 2022, with 60,000 subscribers.
- The newly launched WeChat video account published 36 videos and has nearly 4,000 subscribers.
We are pleased to see that Apache Flink has become the global standard for real-time stream computing. With its powerful real-time big data computing capabilities, Flink has combined many open source projects to form a series of solutions for real-time big data scenarios, including:
- (large) monitoring dashboard
- data integration
- data lake warehouse analysis
- personalized recommendation
- risk control monitoring
The rest of this article will briefly summarize the Keynotes from the summit.Cloud and Open Source - Planting the Roots of the Digital World Together
Before the Keynotes session started, Yangqing Jia, Vice President of Alibaba Group, Head of Alibaba Open Source Technology Committee, and Head of Alibaba Cloud Intelligent Computing Platform, shared his understanding of the relationship between cloud and open source.
In today's era of digitalization, cloud and open source have been symbiotic, growing together, and building the roots of a digital world. We keep asking ourselves the question how to better combine open source and commercialization. And we believe that the cloud is the most important component in the solution.
The cloud provides a better environment for the deployment and acquisition of open source software. In the elastic environment provided by the cloud, users can obtain the capabilities of open source software and platforms with one click. The symbiosis of cloud and open source software also enables users to have a broader and more flexible choice, with everyone able to find the most suitable combination of open source software to solve their own business problems. In the process of this development, the concept of cloud-native has gradually emerged.
Over the past decade, Alibaba has been a staunch supporter and practitioner of open source software and communities, forming a trinity strategy:
- Technologies from the open source community
- Technologies applied internally by Alibaba
- Technologies provided to customers as commercial applications on Alibaba Cloud
All of the above are unified as a single solution.

A large-scale environment like Alibaba can generate many personalized or systematic needs, but open source offers a highly positive user experience. The two situations complement one another. Alibaba contributes its best practices back to the open source community, enabling a good combination of ease of use of the community and the stability and resilience used by large-scale enterprises.
Taking Apache Flink as an example, Alibaba began to adopt Flink as a technical route for internal real-time computing in 2016, and built an internal solution - Blink based on Flink. Since 2016, we have gradually contributed Blink back to the community, and by 2018 we have become the largest contributor to the Flink community. Today, we are pleased to see that 1/4 of the members of the Apache Flink project management committee (PMC) come from Alibaba. Through Alibaba’s promotion and the cooperation of the entire community, Flink has been used by most Internet companies in China as the industry standard for stream computing. Flink has also been the most active project in the Apache community for two consecutive years.
Today's iterations of cloud and open source have also led to new explorations in the direction of open source software. Flink, for example, started as a platform for implementing stream computing with Java APIs, and gradually grew to include capabilities like SQL in applications within Alibaba and on Alibaba Cloud. In recent years, Alibaba has also been exploring new directions based on its own needs for using Flink, such as
- Flink CDC project that is developing very fast in the direction of data integration
- Flink ML project that combines machine learning
- Streaming Data Warehouse concept that combines traditional data warehouses
- Flink Table Store project launched under that concept
Additionally, the big data industry as a whole uses a lot of standard technology, such as the Remote Shuffle Service in a large-scale distributed computing environment where storage and computing are separated, as well as similar specifications in engines like Flink, Spark, and Hive. We are also happy to announce that Alibaba Cloud has donated the Remote Shuffle Service project to the Apache Software Foundation, which was created in its own cloud scenario, and given the name Apache Celeborn.
Alibaba is not only a beneficiary of open source software, but also a contributor. Open source has become an integral part of Alibaba's engineering culture. More and more engineers are gaining knowledge from the open source community, actively participating in open source software and community building; while at the same time contributing their own projects to the open source community. I believe that in the future we will continue to collaborate with the open source community to give people a platform and a way to access and utilize software more readily based on cloud solutions, while also using our technical prowess to create a more profitable open source ecosystem. Flink Towards Streaming Data Warehouse
The first Keynote speech comes from Mr. Feng Wang, the initiator of the Apache Flink China community and the Head of the Alibaba Cloud Open Source Big Data Platform. He introduced the main technological innovations and achievements of the Apache Flink community in 2022, as well as the direction of future developments.
Continuous Innovation in Real-time Data Technology
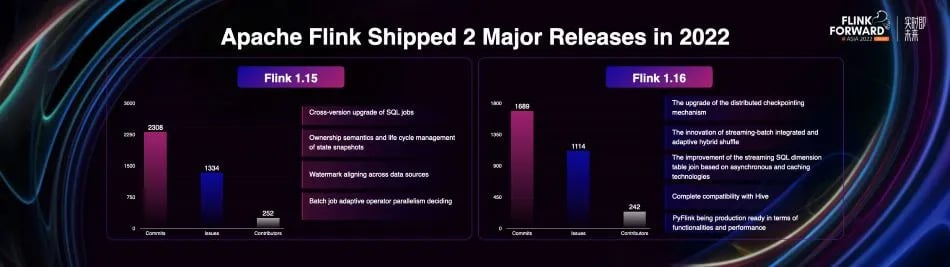
In 2022, Apache Flink released two major versions.
In version 1.15 of Flink, the community concentrated on solving many long-standing historical problems, including:
- Cross-version upgrade of SQL jobs
- Ownership semantics and life cycle management of state snapshots
- Watermark aligning across data sources
- Batch job adaptive operator parallelism deciding, etc.
In the Flink 1.16 version, the community made more innovations, including:
- The upgrade of the distributed checkpointing mechanism
- The innovation of streaming-batch integrated and adaptive hybrid shuffle
- The improvement of the streaming SQL dimension table join based on asynchronous and caching technologies
- Complete compatibility with Hive
- PyFlink being production ready in terms of functionalities and performance, etc.
Upgrades to the Distributed Checkpointing Mechanism
One of the very foundational components of Apache Flink, a stateful stream processing engine, is the distributed checkpointing mechanism. During the stream processing, Flink takes checkpoints of the state periodically and persists them. Upon errors, the job can be restored from the latest checkpoint to ensure business continuity. Consequently, it is a typical request from Flink users to be able to take checkpoints at a higher frequency and at a lower cost.
However, in a real production environment, especially for large-scale and complex workloads, the checkpointing mechanism faces many challenges. On the one hand, under backpressure, the network buffer is congested, and the barrier used for generating checkpoints cannot propagate along the data flow, preventing checkpoints from being triggered in time. On the other hand, even if checkpoints can be triggered, the data volume and upload time of the local state data that needs to be persisted to the remote storage system are uncontrollable. Due to these reasons, users often encounter the situation that checkpoints cannot be generated within the specified time, which significantly affects the stability of the business.
In response to these problems, Flink has upgraded the distributed checkpointing mechanism in recent versions.
- Unaligned Checkpoint: When the barrier aligning time reaches a certain threshold, Flink automatically switches to unaligned checkpointing, taking both the amount of checkpointed data and the barrier aligning time into account.
- Buffer Debloating: Only buffer the amount of data that can be processed by downstream operators within 1 second. This minimizes the amount of data cached between operators on the premise of avoiding network transmission affecting operator performance.
- Log-based Checkpoint: Reduce the cost of generating checkpoints by decoupling the states and incremental logs and uploading asynchronously.
With the implementation of the above technologies in the 1.16 release, Flink has formed a new generation of distributed checkpointing mechanism.
Cloud-native state management mechanisms
The era of cloud native has arrived and every infrastructure software project needs to consider how to adapt to such an era. Apache Flink is no exception. For Flink, the most significant change brought about by the cloud-native era is the demand for resource elasticity, which requires Flink jobs to dynamically change parallelisms along with the workload and resources. When changing parallelism, Flink's state also needs to be quickly redistributed (i.e., splitting and merging). Therefore, the splitting and merging performance of Flink's state is directly related to the experience of Flink's elastic scaling.
In version 1.16 of Flink, the community has made a lot of optimizations to the state reconstruction algorithm of the RocksDB State Backend, achieving a performance improvement of 2-10 times and making Flink's elastic scaling smoother and more adaptable to the cloud-native era.
In addition, the community also plans to further upgrade the Flink state management mechanism to a complete storage-computing separation architecture to adapt to the cloud-native environment. At present, Flink's state management mechanism is not a real storage-computing separation architecture. All state data is still stored in the local RocksDB instance. Only incremental data is copied to remote storage during checkpointings to ensure that there is a full copy of state in remote storage. In the future, Flink's state will all be on remote storages natively, and local disks and memory will only be used for cache and access acceleration, forming a tiered storage mechanism, which we call the Tiered State Backend architecture.
Innovative Hybrid Shuffle Technology for Stream and Batch Unification
Apache Flink's Stream-Batch unification and integration are very unique technical concepts, but Shuffle is a fundamental and performance-related technology in distributed computing systems. Flink 1.16 innovatively introduced the integrated and adaptive Hybrid Shuffle technology.
Prior to this, Apache Flink had two different Shuffle technologies in stream mode and batch mode:
- Streaming Pipelined Shuffle: The upstream and downstream tasks are directly connected through the network, and the data is transmitted through the memory and the network without disk IO, resulting in a better performance.
- Batch Blocking Shuffle: The upstream task first writes the intermediate data to the disk or other storage services, and the downstream reads the intermediate data from the disk or storage services. Disk IO is required, and the performance is slightly poor.
So, the question arises if streaming shuffle can be applied in batch execution mode to speed up batch shuffle. From the perspective of technology itself, it is possible, but it will face relatively large constraints in the production environment. There is no guarantee that there will be enough resources in the production environment for streaming pipelined shuffling, and there might even be deadlocks because all interconnected tasks must be launched at the same time. Resources can be used more effectively for shuffle acceleration if the tasks connected to each other can be launched simultaneously for streaming shuffle acceleration only when resources are sufficient and fall back to batch shuffle at the same time when resources are insufficient. This is the background and idea of Hybrid Shuffle.
The first version of Hybrid Shuffle was completed in Flink 1.16, and the preliminary evaluation shows a good performance improvement compared to the traditional Blocking Shuffle. In subsequent versions, the community will further improve and optimize this technology.
Flink CDC unified full-incremental data integration
Flink CDC, a unified full-incremental data integration technology based on Apache Flink, is a new concept proposed in the past two years.
Why build such a data integration engine based on Flink? Flink is essentially a streaming distributed processing engine, which has actually become a data pipeline connecting different storages. Flink has a rich connector ecosystem that can connect to various mainstream storage systems, and has an excellent distributed architecture that supports mechanisms such as distributed checkpointing and stream-batch unification. These are the features required by a unified full-incremental data integration engine. Therefore, it is very suitable to build such an engine based on Flink, which is the origin of the Flink CDC project.
We launched Flink CDC 1.0 last year and received very good feedback from the developers in the ecosystem. Therefore, this year we increased our investment and launched a more mature and complete Flink CDC 2.0. The main features of Flink CDC 2.0 include:
- The general incremental snapshot framework abstraction reduces the access cost of new data sources and enables Flink CDC to quickly access more data sources.
- Supports high-performance concurrent reads.
- Based on Flink's distributed checkpointing mechanism, data integration can be resumed, which significantly improved the reliability.
- There is no lock on the data source, thus the data integration has no impact on online business.
The innovative Flink CDC project is growing very fast and is becoming a new generation of data integration engine. At present, Flink CDC has supported mainstream databases including the MySQL family, PolarDB, Oracle, and MongoDB with the incremental snapshot framework. In addition, it also supports well known databases such as DB2, SQLServer, PostgreSQL, TiDB, and OceanBase, and more data sources will be supported in future. The project has also received great feedback from developers in the open source ecosystem, and the number of Github stars has exceeded 3,000.
Flink ML-2.0 and the new iterative processing framework
In the old versions of Flink, there is a Flink ML module, which is a set of machine learning algorithms based on the DataSet API. With the stream-batch unified DataStream API dominating Flink’s lower API layer, the original Flink ML module is discarded together with the DataSet API. This year, the Flink community rebuilt Flink ML based on the DataStream API as a new subproject, and two versions have been released so far.
As we all know, the core of the machine learning algorithms is the iterative processing framework. Based on the Flink DataStream API, Flink ML 2.0 rebuilds a stream-batch unified iterative processing framework, which can support online training on infinite streams, training recovery from interruption, and high-performance asynchronous training. Flink ML 2.0 is still in its infancy. As a beginning, dozens of algorithms have been contributed by the real-time computing and machine learning teams from Alibaba Cloud, which can cover common feature engineering scenarios and support low-latency near-linear inference computing. It is expected that more companies and developers will participate in the future and contribute more classic machine learning algorithms to Flink ML, so that Flink's excellent processing power can play a greater role in machine learning scenarios.
Apache Flink Next - Streaming Data Warehouse
At the FFA Summit last year, we proposed the next milestone in the technical roadmap of the Apache Flink project: the Streaming Data Warehouse.

Let's first review the evolution of the core technical concept in Flink's history, which helps to understand why we think Streaming Data Warehouse is the next direction in the evolution of Flink.
- Stateful Streaming: At the beginning of its birth, Flink was favored by developers. It replaced the previous generation of stream computing engine Storm and became a new generation of stream computing engine. The key lies in its positioning of stateful stream computing. By integrating streaming computing and state, Flink can support exactly-once data consistency of stateful streaming computing at the framework layer while maintaining high throughput and low latency.
- Streaming SQL: In the early days, users of Flink were required to write Java programs. After several years of rapid development, Flink encountered a bottleneck due to this high adoption bar. In the world of data analysts, the industry standard language is SQL. So in 2019, Alibaba Cloud contributed their internally accumulated Blink SQL to the Flink community, which greatly lowered the bar for developing Flink jobs, resulting in explosive growth of Flink's applications in various industries.
- Streaming Data Warehouse: Flink's streaming-batch unified SQL can provide a full-incremental integrated data developing experience at the computing layer, but it cannot solve the problem of splitting at the storage layer. The data in streaming storage is difficult to query and analyze, while the timeliness of data in batch storage is relatively poor. Therefore, we believe that the new opportunity for the Flink community in the next stage is to continue to improve the integrated experience, and build a streaming data warehouse with integrated experiences with stream-batch unified SQL + stream-batch unified storage.
Flink Table Store, a new sub-project launched by the Flink community, is positioned to achieve streaming-batch unified storage capability, with high-performance streaming reading, streaming writing, batch reading, and batch writing. The design of Flink Table Store follows the concept of separation of storage and computing. Data is stored on mainstream cloud storage. Its core storage format consists of two parts, LakeStore and LogStore. LakeStore applies classic LSM, ORC and other indexing technologies, suitable for large-scale, high-performance data update and reading. LogStore provides a ChangeLog with complete CDC semantics, and with Flink Streaming SQL, it can incrementally subscribe to Table Store for streaming data analysis. What’s more, Flink Table Store adopts an open data format system. In addition to connecting to Flink by default, it can also connect to mainstream open source computing engines such as Spark, Hive, and Trino.
Two editions of the Flink Table Store have been released in the year since its conception, and the incubation and landing from 0 to 1 have been finished. At present, in addition to Alibaba Cloud, developers from companies such as ByteDance are also participating in co-construction and trials. We compared the performance of Flink Table Store with the current mainstream data lake storage Hudi. The results show that:
- The updated performance of Flink Table Store is significantly ahead of Hudi
- The query performance is significantly ahead of Hudi MOR mode, close to Hudi COW mode
- The overall performance is better
The application of Apache Flink real-time computing at Midea Group
The second Keynote session was brought by Ms. Qi Dong, who is in charge of real-time data at Midea Group and a senior data architect. From the perspective of the home appliance industry, she shared the application and practice of Apache Flink real-time computing in Midea's traditional and emerging business scenarios.
Qi first introduced the development and current status of the real-time ecosystem in Midea, which builds its real-time data warehouse mainly around three elements:
- Timeliness
- Stability
- Flexibility
In terms of timeliness, a timeliness guarantee mechanism using Flink at its core is created to ensure timeliness. In terms of stability, it introduces a series of checks in the development phase for data source connectivity, metadata parameter format, etc., as well as monitoring and alerts of cluster resources and task status in the running phase. In terms of flexibility, there is unified resource management for resources such as metadata, UDFs, connectors, and unified task management such as task templates and pre-build common logics.
Flink has played an important role in the digital transformation of Midea's core traditional business scenarios. Qi shared three of them.
- Long-cycle business scenarios: Specific business scenarios include the Kanban board for Mei-yun-xiao (the names consists of three Chinese characters, which translates to Midea, Cloud, and Sales respectively) App and full-link order visualization. Purchasing, marketing, inventory analysis, and tracking of long-term orders in traditional industries need to track the data of a long period of time in the past, which poses a relatively large challenge to real-time computing. In our architecture, the full amount of historical data is imported through Flink's automatic loading of the Hive partition table, and combined with Kafka's incremental data for further calculation and processing.
- Factory production progress: The factory managers and employees can see the hourly production progress through the real-time large screen, which is of great practical value for completing daily production tasks.
- Large screen for early bird specials: The order grabbing activities for agents, operators, and retailers are very critical when it comes to rights and interests in terms of price, supply, and new product launch. The real-time large screen at the event site is of great significance for guiding operators to adjust their operation strategies, and for agents and retailers to carry out retail and order grabbing activities.
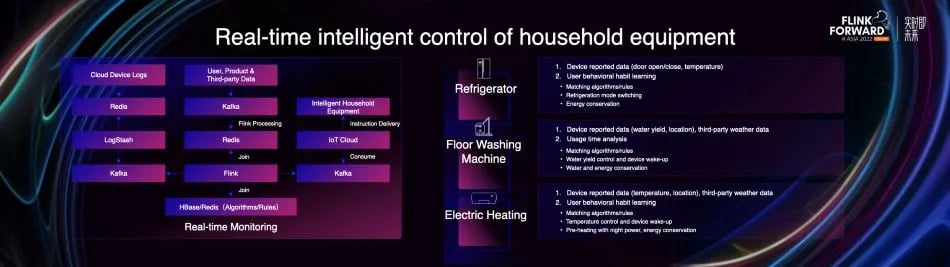
In the emerging business scenarios of Midea, there are also many real-time digital application practices based on Flink. In this regard, Qi also shared three scenarios.
- Real-time intelligent control of household equipment: applications such as refrigerator cloud manager, floor washing machine cloud manager, and electric heating cloud manager all have the function of analyzing user behavior and adjusting and controlling the behavior of smart home appliances to achieve the purpose of energy saving and water saving. Flink consumes device data in Kafka, associates it with Redis/HBase users, products, third-party data, algorithm models, rules, then writes the results to Kafka, and finally completes the delivery of device instructions through the IoT cloud. In addition, in this set of links, Flink also undertakes the function of real-time monitoring.
- HI service real-time message push: In addition to automatic control functions, smart home products also have many functions that need to be completed through human-computer interaction and human manipulation, such as failure reminders, completion reminders, and consumable reminders. This set of links is very similar to the real-time intelligent control of home devices, except that the final data will be written to a third-party push platform.
- E-commerce activity monitoring large screen: the business data manually collected and entered by operators is inserted into the database, incremental change data is captured through CDC technology, and then processed by Flink, and a real-time large screen is built through StarRocks + QuibkBI for Fast and intuitive operational decisions.
Qi Dong pointed out that the next step of Midea Group's real-time ecosystem development will focus on cost reduction and efficiency improvement and tool empowerment, including basic operation and maintenance capabilities such as cloud-native deployment, hotspot balance, task error report root cause and repair prompt, as well as platform and visual configuration integration tools on the business side, fine-grained resource configuration, and stream-batch integration practices, etc.Apache Flink in practice at MiHoYo
Next is the Keynote from Mr. Jian Zhang, the leader of MiHoYo’s big data real-time computing team.
Jian first introduced the development history and platform creation of Flink in MiHoYo. MiHoYo chose Apache Flink from the beginning, based on Flink's excellent features such as millisecond delay, window computing, state storage, and fault-tolerant recovery, as well as the thriving community behind it. The original real-time computing platform is completely based on the Flink DataStream API, and initially has task management and operation and maintenance capabilities. With the growth of business, the MiHoYo real-time computing platform has entered a stage of rapid development in 2020, starting to build a one-stop development platform based on SQL, improving capabilities such as multi-cloud and cross-region task management, SQL and connectors, metrics and log systems, metadata and blood relationship, which greatly improved the efficiency of development. This year, the MiHoYo real-time computing platform began to move towards new goals, starting to improve the functionality and use-case coverage of the one-stop development platform, including static and dynamic job tuning, auto scaling, resource elasticity, near real-time data warehouse, etc.

In terms of application, Jian shared four important application scenarios inside MiHoYo.
- Standardized collection and processing of global game logs: Flink is responsible for the processing of nearly 10 billion logs per day for MiHoYo’s entire game business, with a peak traffic of over 10 million. The logs received through the Filebeat collection and log reporting service are transmitted to the Kafka real-time data bus, processed by Flink SQL, and written into downstream Clickhouse, Doris, Iceberg and other storages, and provided to customer service query systems, real-time analysis of operations, offline data warehouses and other applications use cases.
- Real-time reports and large screen: We will provide real-time large-screen services for important indicators according to business needs, and provide real-time application viewing of indicators based on BI reports for operations. E.g. in community posts sorting, the data source is firstly reported by the client to Kafka, and secondly captured by the incremental data of the business database through Flink CDC. In order not to introduce additional KV storage, and to solve the problem of missing join due to untimely update of dimension tables, we merge the task of Flink streaming consumption Kafka and the task of Flink CDC capture database into the same task, and use RegularJoin. Here we have extended Flink SQL to be able to control the time-to-live of underlying state at a finer grained and avoid the expiration of the state of the dimension table. The joined data is then processed into indicators and provided to the post sorting service.
- Near-real-time data warehouse: We use Flink SQL to write to Iceberg in real time to achieve near-real-time for writing logs into offline storage. The data storage time is shortened from hours to minutes, and the volatility of offline storage IO is also much more stable. Through Flink CDC, the MySQL database is fully and incrementally synchronized, combined with the platform's one-click task generation, automatic tuning and scaling, and automatic submission and operation, etc., to achieve one-click database-warehouse synchronization, which greatly improves development efficiency and reduces downtime pressure on the database. A typical application scenario of the near real-time data warehouse is player record query.
- Real-time risk management: In MiHoYo, the risk management team and the real-time computing team are in close contact. The risk management team provided a good risk control engine, and the real-time computing team built a set of relatively automated API and task management methods based on the risk management engine to make the real-time computing platform servitization. Specific application scenarios include login verification, game anti-cheating, man-machine verification, etc.
According to Jian, the future work of MiHoYo in the field of real-time computing mainly includes three aspects: first, platform capacity building, including Flink SQL, resource optimization, automated operation and maintenance, resource elasticity, etc.; second, exploration of usage scenarios, for example, delayed message service, Flink CDC-based binlog service, application-level indicator service, etc.; the third is the continuous practice of data lakes and TableStore, including the practice and exploration of stream batch integration and near real-time data warehouses.
Disney Streaming Media Advertisement with Flink
The last Keynote session was jointly brought by Youchao Hao, Executive Director of Disney Advertising Intelligence, and Dingzhe Li, Head of Disney Advertising Intelligence Real-time Computing.
Youchao first introduced Disney's streaming media advertising business. As the leading streaming media platform in the United States, Hulu was first established jointly by Disney, Fox, and NBC. With the acquisition of Fox in 2019, Disney gained the operational control of Hulu and the high-quality resources of the advertising platform, and began to focus on online streaming media, launching Disney+, ESPN+, Star+ and other brands one after another.
Currently, Disney streaming has 235 million subscribers worldwide (on a household basis), more than Netflix. Hulu is currently the main source of Disney's streaming media advertising business. It delivers hundreds of millions of 15-second and 30-second video advertisements every day, and every time an advertisement is selected, dozens or even hundreds of events will be generated, which poses a very high challenge to the data platform. This challenge is expected to grow exponentially with the launch of ads on Disney+ in December. The Disney streaming media advertising data platform is divided into two layers: data algorithms and application services. Apache Flink is mainly used in the data algorithm layer to aggregate key indicators in operational data in real time.
Dingzhe also shared the details of the real-time data part of the Disney streaming media advertising data platform. In the real-time pipeline, Flink performs streaming processing on all data collected from the system and the user side, and the calculated indicators are exposed to the business platform, operation and maintenance platform, advertising server, etc. via the data interface. In the offline pipeline, they use Spark to generate offline reports and external data output, and use Flink to perform indicator backfilling and other processing.
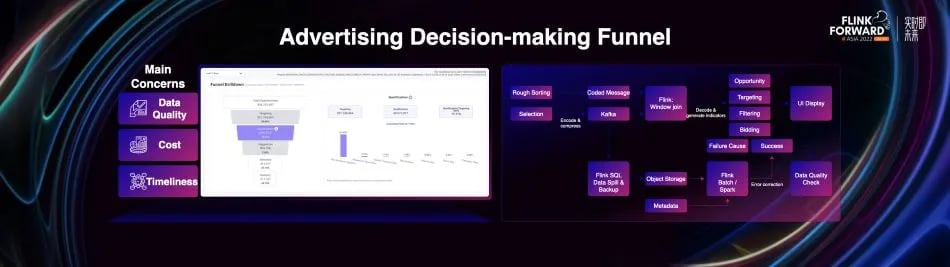
Dingzhe also shared three real-time application scenarios of using Flink in Disney streaming advertisements.
- Advertising decision-making funnel: Advertising decision-making is a complicated process, which needs to select the most suitable advertisement for users from a huge advertising pool through rough sorting, fine sorting and a series of filter conditions. In order to troubleshoot this complex process, we abstract it into a funnel model to display information such as the opportunity of advertising, whether the targeting is successful, whether it is filtered, whether it is finally successfully delivered, and the reason for the failure. We use Flink to decode and correlate the decision-making information obtained from the advertising server, restore the decision-making funnel and submit it to the front-end for display. In the offline link, we have practiced Flink's stream-batch integration, and use the same set of codes to perform error correction and data backfill when there is a problem with real-time data.
- Advertising exposure monitoring: Advertisers usually put forward some requirements for advertising, such as targeting specific groups of people, limiting the number of times of advertising within the same time period for the same user, and avoiding simultaneous appearance of competing advertisements. In response to these needs, we have developed an advertising exposure monitoring platform, allowing advertisers to view relevant information about their advertising. In this scenario, we use Flink to correlate and dimensionally enhance the contextual information and user behavior from the advertising system and client, generate a series of factual indicators, and calculate more derived indicators based on specific rules.
- Large screen of the advertising system: Facing the management and business parties, it provides a global insight into the advertising system and advertising delivery. Data from factual data sources is processed by Flink, exposed through the indicator interface, aggregated according to different business rules, and finally delivered to the front end for large-screen display.
According to Dingzhe, the real-time data platform for Disney’s streaming media ads is built on the cloud, deployed on Kubernetes, and uses Flink Kubernetes Operator to manage the Flink cluster. They have practiced Gang Scheduler, stream batch job mixing, and queue-based elastic rescaling and other technologies.
At the end, Youchao shared some future application scenario plans for Flink on the Disney streaming media advertising platform, including stream batch integration, OLAP, real-time attribution, and streaming machine learning.
Summary
At this year’s Flink Forward Asia, we were delighted to see that the Apache Flink community continues to thrive in the following areas:
- community building: the scale and activity of the global and Chinese communities have reached record highs
- technology growth: states, fault tolerance, shuffle, data Integration, machine learning and other Flink-related technologies are continuously developing. On top of that, Flink Table Store, a stream-batch integrated storage for future stream data warehouses, has also made gratifying progress
- industry applications: a growing number of businesses from all sectors are participating in the Flink development, the technology accumulation and new applications are continuously fed back to the community.
Let us look forward to Apache Flink getting better and better!




