














We recently presented Klaviyo’s use case at Flink Forward San Francisco 2019 and showcased how our engineering team leverages Apache Flink to scale the company’s real-time analytics system that deduplicates over a million events and updates over a million counters per second with cardinality in the billion range. In the following paragraphs, we will explain our journey in building a scalable real-time analytics system using leading open source technologies such as Apache Flink and Apache Kafka.
We will first outline some of the technical challenges of our analytics system and present how its initial version was upgraded to its current Apache Flink-based version. We will then talk about the reasons why we chose Flink and dive deeper into some of the tuning parameters and configuration changes of implementing Apache Flink for high cardinality and fan-out ratio workloads at Klaviyo.
Real-time Analytics with High Cardinality
Klaviyo is a data-driven company with the mission to help ecommerce brands grow faster. At the heart of our product sits Klaviyo’s analytics platform which ingests billions of events daily and processes them in near real-time. Today, Klaviyo processes thousands of types of events at a rate of close to 100,000 per second for more than 200,000 user companies.
Some of the technical challenges our team had to address were the following:
-
Having over a billion user profiles, increases dramatically the data set size (cardinality) of our system.
-
Our platform maintains large state — more than 1.5TB — mainly for duplicate detection.
-
We have a very high fan-out ratio, from one to hundreds of dimensions for a single event.
-
Because of both the high cardinality and fan-out ratios mentioned previously, we need to aggregate millions of events per second.
The initial version of Klaviyo’s event processing pipeline relied on a complex series of Celery tasks built with RabbitMQ as a message bus. The system was written in custom Python code, leveraging separate Redis clusters to track events flowing through and performing event de-duplication or aggregation before sending the aggregated or deduped results to a Cassandra cluster. The top-level architecture of the event processing system consisted of the components shown in the diagram below:
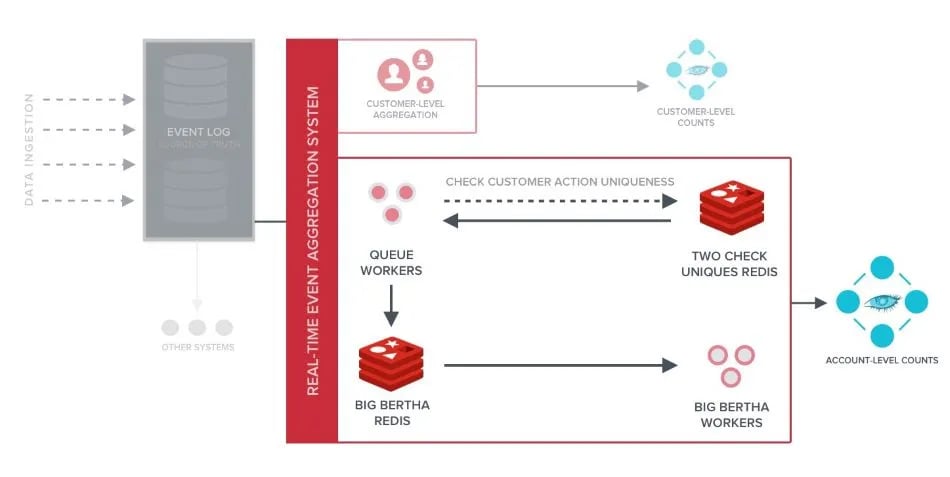
Although this system served Klaviyo well for many years, it had some limitations such as being prone to data accuracy issues because the ingestion was not idempotent. The aggregation system relied upon two Klaviyo proprietary subsystems — Big Bertha and Check Uniques — to process events and write to Cassandra. As a result, the system’s dependency on the two proprietary systems made the ingestion of an event no longer idempotent, which meant any failure in these subsystems and their storage tiers could cause data accuracy issues. Additionally, the system lacked isolation between account-level and customer-level aggregations (impacting different areas of Klaviyo), meaning that either system’s operational incidents could negatively impact the other. Finally, the aggregation system was slow because of Cassandra’s counter data type demanding a read before write blocking operations, which made the writing to counter data type less performant than writing to other Cassandra data types.
Why we chose Flink
During the evaluation phase, we looked at the popular stream processing technologies that were relatively mature, including among others Apache Spark, Apache Storm, Apache Flink and In-memory DB, e.g., VoltDB. Flink was chosen because of its unique combination of attributes such as being:
-
Stateful: The framework’s ability to efficiently manage state internally is essential for our success because external state management is the leading cause of non-idempotency for our workload.
-
Highly available: If the aggregation system is unavailable, it impacts all of our products and customers. The streaming framework has to be resilient to failures.
-
Easy to scale: Klaviyo’s ingestion workload varies wildly during the course of normal daily operations as well as for large events. For instance, during Black Friday, overall event ingestion more than triples and we see spikes of over 10x previous highs. It is crucial for the framework to allow us to scale easily. For us, scalability has two primary aspects. One is the scalability in terms of throughput. The system’s throughput should be readily increased by simply adding more nodes. The other equally important aspect is the scalability of data storage. It should be trivial to grow the amount of data the system can store.
-
Real-time: Downstream tasks rely on ingestion of event to be within one second to perform accurate business logic actions, such as segmentation and flow sending.
Flink was the only technology that possessed the attributes we wanted in a framework. Even better, the Flink community was growing fast and the documentation of the software was reasonably detailed.
Next-Gen Real-time event processing at Klaviyo: Abacus
To truly overcome the challenges of the initial version of our real-time event aggregation system, we decided to transform it into a modern streaming application, called Abacus, that leverages Apache Flink as the core stream processing framework.
Abacus was built in two iterations; the first one focused on aggregating events and writing deltas to a database while still using Cassandra’s counter data type mentioned above, to leverage existing data storage and APIs. The second iteration aggregates final counts and persists the results to Cassandra (or any other distributed database). The second iteration includes redesigning the API layer to query data and migrating of all historical data to the new system. After this second iteration, we then moved off from Cassandra’s counter data type.
To bring Abacus in line with the performance expectations of our specific workload, we made a series of code changes and tuning to improve the performance, including tuning RocksDB that we explain below.
Tuning RocksDB in Apache Flink
Large states in our workload makes it infeasible to maintain everything in memory. Thus, we rely heavily on the RocksDB state backend to manage our growing hot data for processing events.
RocksDB is a high-performance storage engine, but tuning it for different workloads is not hassle-free. With dozens of options, finding the right ones to tune is as challenging as tuning them. Flink comes with several predefined option sets for different storage device types. It works reasonably well for simple workloads. Anything else may require further tuning. RocksDB’s Tuning Guide is a good place to start.
Before going into the parameters, it is worth understanding how RocksDB works because the design highly influences the tuning.
RocksDB is a persistent key-value store based on LevelDB from Google. The foundational data structure in RocksDB is Log-structured merge-tree (or LSM tree). It caches writes in memory (Memtable) until they reach a certain size, then it flushes them to fixed-size files on disk (SSTable). Once written, the files are immutable, which is one of the reasons LSM trees are fast for writes. As files on disk accumulate, they get compacted into bigger files by merging the smaller files together and removing any duplicates. The compaction process continues until it reaches the max set level, then the files stay unchanged. Because writes are always-append operations in memory, they are super fast. It does not update the previous versions of the same key in the persisted files. Compaction takes care of removing the older versions. RocksDB is an example of the tradeoff between space and speed — its fast writes come at the cost of greater storage demands. RocksDB operation is described in the diagram below.
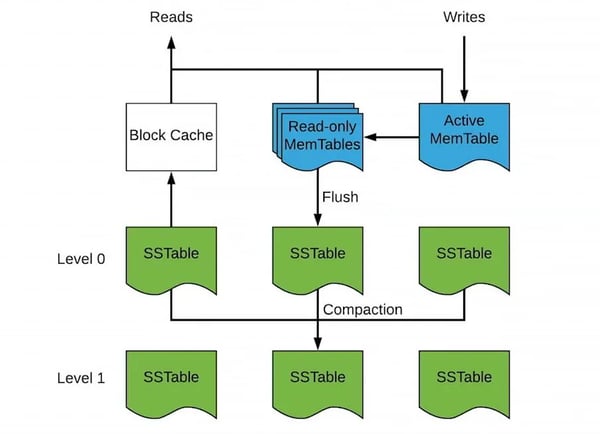
As described above, RocksDB is optimized for writes without sacrificing much read performance. If a read accesses a recently written key, it is highly likely that it still exists in the Memtables, which can be serviced without going to disk. This is perfect for workloads with a Zipfian distribution, which covers a plethora of real-world use cases such as a tweet going viral.
With writes and reads accessing mostly the recent data, our goal is to let them stay in memory as much as possible without using up all the memory on the server. The following parameters are worth tuning:
-
Block cache size: When uncompressed blocks are read from SSTables, they are cached in memory. The amount of data that can be stored before eviction policies apply is determined by the block cache size. The bigger the better.
-
Write buffer size: How big can Memtable get before it is frozen. Generally, the bigger the better. The tradeoff is that big write buffer takes more memory and longer to flush to disk and to recover.
-
Write buffer number: How many Memtables to keep before flushing to SSTable. Generally, the bigger the better. Similarly, the tradeoff is that too many write buffers take up more memory and longer to flush to disk.
-
Minimum write buffers to merge: If most recently written keys are frequently changed, it is better to only flush the latest version to SSTable. This parameter controls how many Memtables it will try to merge before flushing to SSTable. It should be less than the write buffer number. A suggested value is 2. If the number is too big, it takes longer to merge buffers and there is less chance of duplicate keys in that many buffers.
The list above is far from being exhaustive, but tuning them correctly can have a big impact on performance. Please refer to RocksDB’s Tuning Guide for more details on these parameters. Figuring out the optimal combination of values for all of them is an art in itself.
The challenge in finding the right values lies in the balance between write performance, read performance, disk performance, recovery time, and available memory. Setting the values too high for the block cache and write buffers risk running out of memory, which kills the job. If the values are too low, it may incur much higher disk IOPs and slow down throughput when saturating your storage hardware capacity.
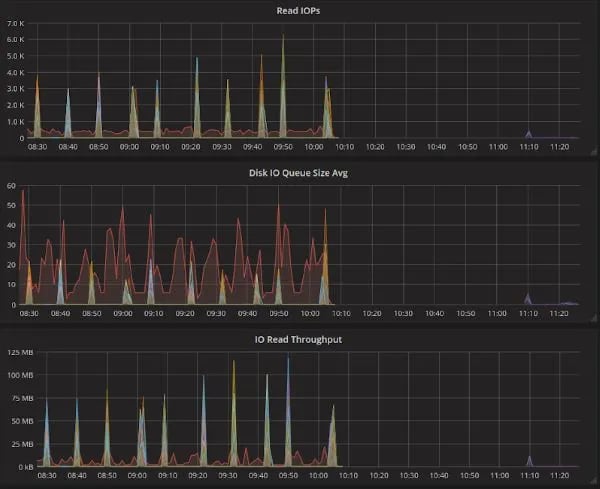
Prior to tuning the RocksDB parameters, our Flink job had high disk read IOPs and throughput, occasionally hitting as high as 9,000 IOPs. After the tuning, the disk read IOPs are mostly in the low hundreds and only spike up to 1,000 IOPs during RocksDB compactions, which is expected.
Flink creates a RocksDB instance for each stateful operator sub-task, each has its own block cache and write buffers. This means that the total amount of memory that can be used by RocksDB is not a function of the number of TaskManagers, but the sum of all stateful operator parallelisms. This long-standing ticket shows how challenging RocksDB memory capacity planning is in Flink. The best way to find out is to use a representative workload to test the job with saturated block caches and write buffers.
Another consequence of per sub-task RocksDB instances is that the TaskManager process may use a large amount of open file descriptors. Running out of file descriptors at runtime is a fatal error, so it is recommended to set the process file descriptor limit higher than needed then dial back after benchmarking or even unlimited if there are a lot of stateful operators in the job.
If you want to find out more about Klaviyo and how we scaled our real-time analytics system with Apache Flink or if you are interested in some performance tuning and code changes we implemented to optimize the performance of our Flink application, you can subscribe to Klaviyo’s Engineering blog. For more information, you can check my Flink Forward presentation or get in touch below.


About the authors:

Ning Shi works with the engineering teams that focus on event processing, data storage, and analytics at Klaviyo. Previously he worked on building distributed in-memory database VoltDB. He is passionate about building high performance distributed systems.

Seed Zeng joined Klaviyo in 2017. He has been working on the event processing pipeline and data storage infrastructure. Seed has lived through two Black Friday Cyber Monday at Klaviyo, contributing to the scaling effort in many key infrastructure systems such as UUID assignment, message queues, Redis clusters, and the real-time analytics system. Seed graduated with Bachelor's degrees in Computer Science and Physics from Washington University in St. Louis.

You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
