














What is Stream Processing
Stream processing is a programming paradigm which views data streams, or sequences of events in time, as the central input and output objects of computation.
This enables organizations to harness the value of data immediately, making it a valuable tool for time-sensitive applications and scenarios requiring up-to-the-minute insights. Stream processing systems excel at handling high-velocity, unbounded data streams, such as click streams, log streams, live sensor data, social media feeds, event streams, transactional data, and IoT device data.
Why Stream Processing?
Organizations are constantly striving to extract timely and actionable insights from their data to gain a competitive edge. Traditional data pipelines, based on batch processing, have long been the go-to approach for data integration and analysis. However, with the increasing demand for real-time insights, companies are now shifting towards stream processing.
Real-Time Insights for Enhanced Decision-Making
A key motivation for companies to embrace stream processing is the ability to obtain real-time insights. Traditional batch processing pipelines operate on static datasets, which may lead to delays in data analysis. Conversely, stream processing allows organizations to both process data and analyze data as it arrives, enabling immediate access to up-to-the-minute insights. This capability enhances decision-making processes, enabling organizations to respond swiftly to changing market conditions, customer demands, and emerging opportunities.
Improved Operational Agility
Stream processing offers unparalleled operational agility, allowing organizations to react swiftly to critical events and anomalies. By continuously processing and analyzing data in real-time, companies can identify patterns, trends, and anomalies as they occur, thus enabling proactive decision-making. Additionally, real-time monitoring and alerting mechanisms provided by stream processing systems enable organizations to promptly detect and respond to operational issues, fraud attempts, security breaches, and other time-critical events, consequently minimizing potential damages and optimizing operational efficiency.
Enhanced Customer Experience
In today's fast-paced digital landscape, delivering exceptional customer experiences is paramount. Stream processing enables organizations to personalize and customize interactions with customers in real-time. By analyzing customer data as it flows, companies can gain deeper insights into customer behavior, preferences, and needs, allowing for personalized recommendations, targeted promotions, and optimized customer journeys. This level of real-time engagement and personalization helps drive customer satisfaction, loyalty, and ultimately, business growth.
Seamless Integration with Modern Technologies
Stream processing seamlessly integrates with modern technologies such as Internet of Things (IoT), real-time analytics, and machine learning. As organizations embrace IoT devices and generate massive amounts of sensor data, stream processing is therefore crucial for real-time data ingestion, analysis, and decision-making. Moreover, stream processing systems serve as a foundation for implementing advanced analytics techniques, such as real-time predictive modeling, anomaly detection, and sentiment analysis. This convergence of stream processing with cutting-edge technologies empowers companies to unlock the full potential of their data assets.
Challenges in Developing Stream Processing Systems
Good streaming processing systems may be difficult to develop, thus we have highlighted the main challenges below:
Fault Tolerance and Resilience
Stream processing systems must exhibit fault tolerance to withstand failures and disruptions. However, achieving fault tolerance in real-time environments is challenging due to the constant flow of data and stringent latency requirements. Implementing fault tolerance mechanisms, such as replication, state management, and checkpointing, is crucial for maintaining data integrity and system availability. Ensuring resilience in the face of failures, network issues, or hardware malfunctions is essential to prevent data loss, maintain consistent processing, and provide uninterrupted insights to downstream applications.
Scalability and Handling Data Volume
Stream processing systems need to handle ever-increasing data volumes while ensuring optimal performance. As data volume grows, the system must scale horizontally to accommodate the load. However, scaling a stream processing system introduces its own challenges. Distributing the workload across multiple processing nodes and managing the dynamic allocation of resources require careful design and implementation. Efficient load balancing, adaptive resource allocation, and parallel processing techniques are vital to achieving scalability without compromising data accuracy or processing speed.
Dynamic Workload Management
Stream processing systems often experience fluctuating workloads due to varying data arrival rates or bursty traffic. Handling such dynamic workloads is crucial for maintaining system stability and performance. Effective workload management strategies, such as load shedding, backpressure, or dynamic resource allocation, are essential to balance the system's processing capacity with the incoming data flow. Proactive monitoring, adaptive buffering, and intelligent workload distribution mechanisms help ensure reliable and efficient data processing in the face of workload variations.
Network and Communication Challenges
Stream processing systems operate in distributed environments, often spanning multiple nodes or clusters. Ensuring reliable communication and continuous data transfer across the network is crucial for fault tolerance, scalability, and reliability. Challenges such as network congestion, latency, or communication failures can significantly impact system performance and data integrity. Implementing robust network protocols, efficient data serialization techniques, and fault-tolerant data transfer mechanisms mitigate these challenges and ensure seamless communication between components.
State Management and Recovery
Stream processing systems often rely on maintaining state for processing real-time streaming data. Managing and recovering state in the event of failures or system restarts is a critical challenge. Stateful stream processing introduces complexities such as consistency, durability, and fault recovery. Implementing reliable state management mechanisms, such as durable storage, distributed snapshots, or event sourcing, ensures that the system can recover state and resume processing from the last known consistent checkpoint, minimizing data loss, and maintaining system reliability.
Monitoring and Observability
Monitoring the health, performance, and behavior of a stream processing system is crucial for maintaining fault tolerance, scalability, and reliability. Effective monitoring and observability enable proactive detection of anomalies, performance bottlenecks, or resource constraints. Incorporating monitoring tools, logging frameworks, and real-time analytics of system metrics and logs into streaming data architecture allows organizations to identify and address issues promptly, ensuring system stability and reliability.
Ververica’s Solutions
Ververica Platform
Ververica Platform, a leading Flink-based stream processing platform, offers a comprehensive set of features and capabilities that make it an excellent choice for organizations looking to harness the power of real-time data analytics.
Ververica Platform is based on Apache Flink®, an open-source data streaming engine that has become an industry standard for stream processing, used by tech giants such as Uber, Ebay, Alibaba, top financial institutions, and more. While based on Apache Flink®, it operates with significantly faster speed and better performance than the open-source Apache Flink®, but maintaining full compatibility with it.
Ververica Platform delivers high-throughput and low-latency stream processing solutions, as well as these leading features:
-
Stream Processing Simplicity
Ververica Platform simplifies the complexities associated with stream processing. With its user-friendly interface and intuitive design, organizations can easily develop, deploy, and manage stream processing applications without the need for extensive expertise in distributed systems or complex programming. The platform provides a visual interface for developing and monitoring streaming workflows, making it easy to use by all engineers, developers and architects
-
Scalability and Elasticity
Ververica Platform is a market leader in handling large-scale stream processing workloads. It leverages Apache Flink, and extends it with additional capabilities for scalability and elasticity. The platform allows organizations to dynamically scale their processing clusters based on workload demands, ensuring high throughput and low latency even as raw data volumes grow significantly. This scalability feature is particularly valuable in scenarios where real-time processing of massive data streams is required.
-
Fault Tolerance and High Availability
Ververica Platform incorporates robust fault tolerance mechanisms, which are crucial for maintaining data integrity and ensuring uninterrupted processing. It leverages the fault tolerance features inherent in Apache Flink, including checkpointing and stateful recovery, to handle failures and system disruptions effectively. By providing high availability and seamless fault recovery, the platform virtually eliminates data loss and guarantees reliable stream processing in the face of unexpected events.
-
Advanced Stream Processing Capabilities
Ververica Platform has advanced features and capabilities that enhance stream processing workflows. It provides support for event time-based operations, allowing organizations to handle out-of-order events and perform time-based aggregations accurately. The platform also facilitates complex event processing with its ability to handle patterns, enrichments, and real-time analytics. These capabilities enable organizations to extract meaningful insights from streaming event data and drive actionable outcomes.
-
Integration and Ecosystem Compatibility
Ververica Platform seamlessly integrates with various data sources, messaging systems, and storage systems commonly used in the data ecosystem. It provides connectors and integrations with popular technologies like Apache Kafka®, Amazon Kinesis®, and more, enabling organizations to leverage their existing data warehouse infrastructure. This compatibility allows for easy integration and interoperability, reducing the complexities of data ingestion and enabling smooth data flow into the stream processing pipelines.
-
Monitoring and Observability
Ververica Platform emphasizes comprehensive monitoring and observability capabilities, critical for ensuring the health and performance of stream processing applications. It offers real-time monitoring dashboards and metrics, enabling organizations to gain insights into the state and behavior of their streaming workflows. With detailed logging, alerting, and visualization features, the platform facilitates proactive monitoring and troubleshooting, empowering organizations to detect and address issues immediately.
-
Enterprise-Grade Security and Compliance
Ververica Platform prioritizes security and compliance, making it suitable for enterprise-level deployments. The platform provides robust security measures, including authentication, authorization, and encryption, to protect sensitive data and ensure compliance with regulatory requirements. Organizations can confidently deploy stream processing applications on the platform, knowing that their data is secure and their operations align with industry standards.
Ververica Cloud
Ververica Cloud is a high-performance, Flink-based cloud-native service for real-time data processing. It democratizes stream processing, making it accessible to all engineers, developers, and architects in companies, big and small. It also maintains full compatibility with open-source Apache Flink, while offering superior performance.
Ververica Cloud offers all the benefits of Ververica Platform. What is more:
- Ververica Cloud is fully managed. It is a ready-to-use cloud platform with no complex infrastructure set-up, just log in and build your streaming application.
- Ververica Cloud is cloud native. With Ververica Cloud, you can easily deploy and manage your data streaming applications on the cloud, and take advantage of the scalability, flexibility, and cost savings that cloud deployment offers.
- Ververica Cloud has even higher performance than Ververica Platform.
- The Ververica team is working hard to add unique new features to Ververica Cloud.
This is a glance of Ververica Cloud’s architecture:
{kind=link}

More information about Ververica Cloud:
Example
A shipping service company, codenamed as SuperFast, wants to develop a new feature in their application to show the users how many stops the delivery is away from the final destination.
At a high level, SuperFast needs to reason the number of remaining stops per package from the information about shipping events and shipping routes, and then send updates about the number of remaining stops to the downstream application which would show the information to the customers.
If they try to develop a stream processing system for this use case from ground up and run it in production, they are likely to face some, or all the challenges, that were discussed earlier.
We will show you how it can be done in Ververica Cloud using Flink SQL.
Note: Ververica Cloud supports other programming languages such as Java, Scala, and Python.
Solve it with Ververica Cloud - the SQL way!
Let us analyze some foundational information briefly:
- Each package has a unique tracking number;
- Each package is assigned a shipping route;
- Each shipping route has a list of ordered stops;
- Each stop has an ID, which is a unique sequence number in its route;
- We can calculate the number of remaining stops for a package by taking the difference between the end stop ID and the current stop ID;
- Each shipping event is an event about a package;
- All events feed into SuperFast’s shipping system as event streams;
- The package tracking system that we are developing is called SuperFastPTS.
SuperFastPTS will consume events from a stream and output into another stream to be consumed by downstream applications.
In this solution, we will abstract all streams into virtual tables, so that we can handle them in SQL.
Abstracting a Stream
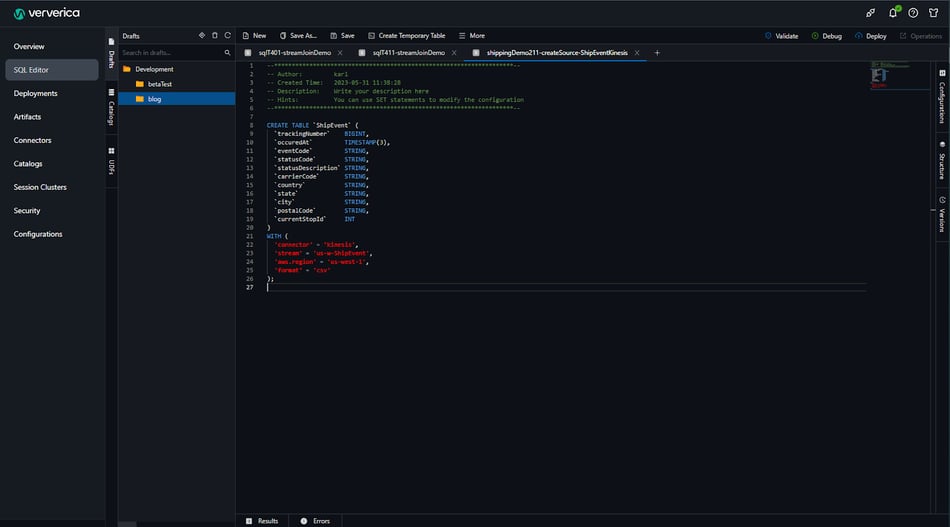
Suppose that the shipping event information is to be consumed from an Amazon Kinesis stream (it can be from Kafka or any data sources that are supported by Ververica Cloud as well). We will abstract it into a table named ShipEvent as the following:
CREATE TABLE `ShipEvent` (
`trackingNumber` BIGINT,
`occurredAt` TIMESTAMP(3),
`eventCode` STRING,
`statusCode` STRING,
`statusDescription` STRING,
`carrierCode` STRING,
`country` STRING,
`state` STRING,
`city` STRING,
`postalCode` STRING,
`currentStopId` INT
)
WITH (
'connector' = 'kinesis',
'stream' = 'us-w-ShipEvent',
'aws.region' = 'us-west-1',
'format' = 'csv'
);Brief procedure in Ververica Cloud:
In the Ververica Cloud workspace:
- Open the SQL Editor;
- Create a new script;
- Write the CREATE TABLE statement in the script and save it;
- Execute the statement;
- This abstracts the stream into the table ShipEvent so that we can use it in Flink SQL queries.
Defining the Stream Processing Job in SQL
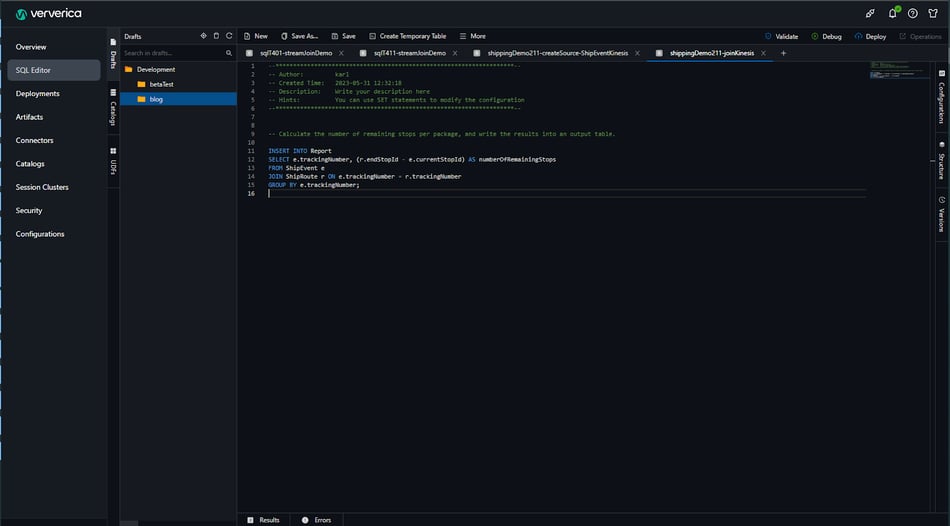
Assume that the shipping route information is in an existing table. It may be backed by an external database table or another stream. The (simplified) table structure is illustrated by the following SQL query:
CREATE TABLE `ShipRoute` (
`routeId` BIGINT,
`trackingNumber` BIGINT,
`endStopId` INT
)
WITH (
-- Details are skipped.
);We can then find the number of remaining stops per package and write the results into an output table which is named “Report”, by the following query. The Report table is an abstraction of another stream (just like ShipEvent) which would be consumed by the downstream application to deliver the updates. Each record in the Report contains:
- A package tracking number
- The number of remaining stops of the package
- The time when it occurred
INSERT INTO Report
SELECT e.trackingNumber, e.occurredAt, (r.endStopId - e.currentStopId) AS numberOfRemainingStops
FROM ShipEvent e
JOIN ShipRoute r ON e.trackingNumber = r.trackingNumber
GROUP BY e.trackingNumber;Brief procedure in Ververica Cloud:
In the same Ververica Cloud SQL Editor:
- Create a new script;
- Write the above query in the script and save it;
- Click the Deploy button;
- A deploy dialog will guide you to deploy the query as a job.
We have now deployed a stream processing job which consumes certain streams (ShipEvent) and outputs to another stream (Report).
As SuperFastPTS is expected to process high volumes of data with low latency, it needs to distribute the workload into a number of computing nodes for efficient parallel processing and aggregate the partial results from those nodes together. In such a distributed system, failure is the norm, and therefore consistency and fault tolerance must be considered into the system design.
- What if some sub tasks fail?
- What if some computing nodes fail?
- What if a whole computer cluster fails?
Ververica Cloud covers all those complexities and heavy-lifting automatically. So the SuperFast team can develop and release new features quickly in SQL or other programming languages of their choice.
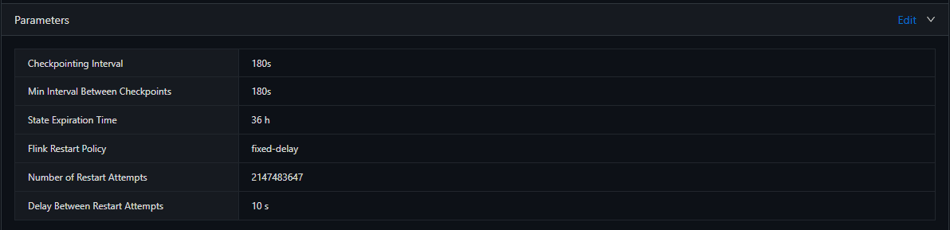
Consistency and Fault Tolerance
In order to ensure their service reliability, the SuperFast team defined their requirements of consistency and fault tolerance. Then they can meet the requirements simply by configuring the job parameters for checkpointing, state expiration, and restart policy in Ververica Cloud.
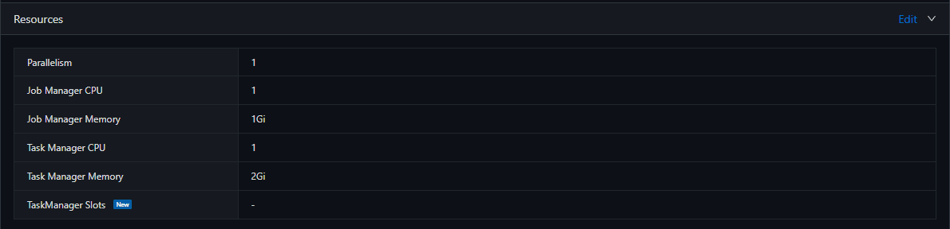
Scaling Up
As SuperFast’s business continued to grow, so did the data volume and system workload. They need more computing power to keep the SuperFastPTS fast and efficient.
With Ververica Cloud, they just needed to configure the resources for the streaming jobs according to their workload. And Ververica Cloud will manage the underlying infrastructure properly.
Managing and Monitoring the Jobs
To start the job:
- Click “Deployments” from the left menu to go to the Deployments page;
- The new SQL deployment should appear at the top of the deployment list;
- Click the “Start” button on the right to run the job.
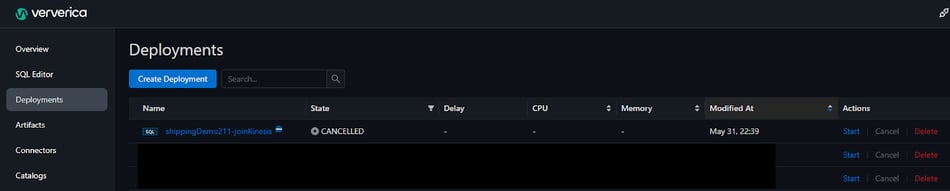
The SuperFast team can use Ververica Cloud to manage the whole lifecycle of their deployments. For example, Ververica Cloud has a built-in graphical user interface to monitor the metrics of the deployments, as seen below.
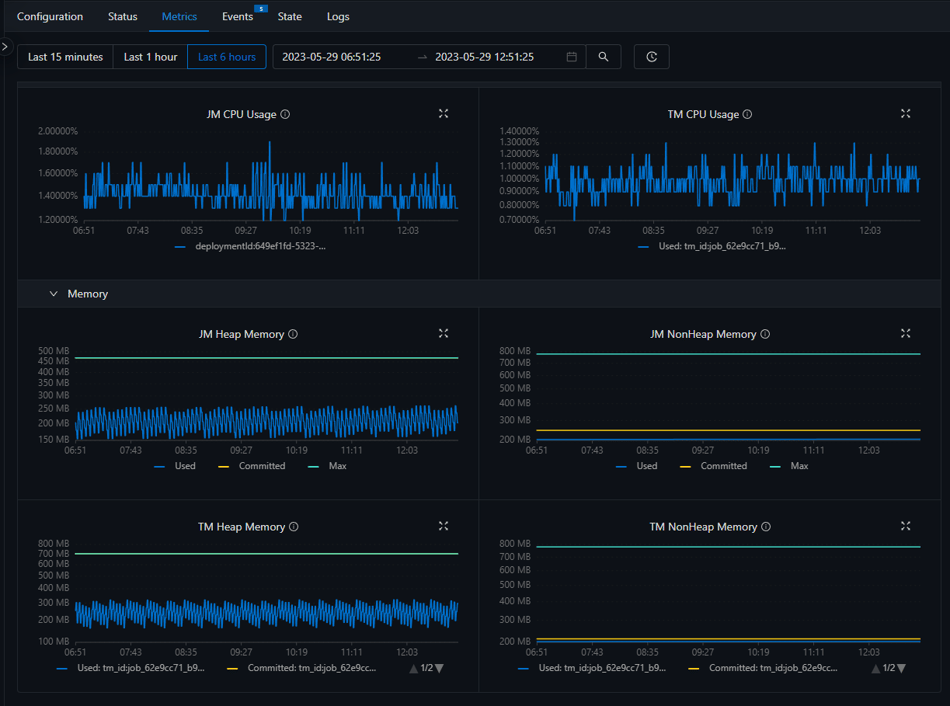
As you can see Veverica Cloud greatly simplifies the development and management of stream processing applications, handling the complexity so that you can focus on your business.
For more detailed instructions on how to use Ververica Cloud, you may view Ververica Cloud documentation.
Related Information

You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
