














While previous blog posts already covered Getting started with Flink SQL on Ververica platform, Creating data pipelines with Flink SQL, and even a complete AdTech Use Case for Real-Time Performance Monitoring, here, we want to focus on sharing common functionality in user-defined functions (UDFs) to make your life even easier.
Flink Community Data Analytics
Initially, this project started with analytics on the commits to github.com/apache/flink by using the Github API. To make things a bitmore interesting and to extract more valuable insights into Flink’s community, with the second version of this project, we added support for looking at pull requests and also at email messages from Flink’s mailing lists. When interpreting the dev mailing list, however, please beware that every ticket that is created in Flink’s Jira is also posted there and you can do basic analytics with it as well (created bug reports, feature requests,…).
We kept the original code for repository analytics in Java and can develop SQL jobs dynamically based on what we are interested in. The whole project is available on Github and can be built with ./gradlew clean check shadowJar or the IDE of your choice. We also provide pre-built packages for things like the data import and user-defined functions that we will use later on. The code and packages I’m describing and using here are from version 2.0 and I will present results from Ververica Platform 2.3.3 which executes SQL statements on Flink 1.11.3.
In order to make our life a bit easier and not have to worry about the Github API throttling our analytics along the way, we will import any data that we want to use into Kafka.
Setting up Apache KafkaTopics
First, let’s create the Kafka topics we will use (replacing the bootstrap-server with one of your own):
kafka-topics --create --bootstrap-server YOUR_KAFKA_SERVER \
--topic flink-commits
kafka-topics --create --bootstrap-server YOUR_KAFKA_SERVER \
--topic flink-pulls
kafka-topics --create --bootstrap-server YOUR_KAFKA_SERVER \
--topic flink-mail-dev --config max.message.bytes=5242940
kafka-topics --create --bootstrap-server YOUR_KAFKA_SERVER \
--topic flink-mail-user --config max.message.bytes=5242940
kafka-topics --create --bootstrap-server YOUR_KAFKA_SERVER \
--topic flink-mail-user-zh --config max.message.bytes=5242940
Note that there are a few emails on the mailing lists that exceed Kafka’s default maximum message size, so make sure to either have a cluster with higher defaults or use the values above. You may also want to set the configuration parameters retention.bytes and retention.ms, depending on your global defaults because we want to do analytics on the whole (historical) data stream and that should still be available when we read it. I will also leave setting appropriate --replication-factor and --partitions to you, but for a simple demo, 1 should suffice.
Importing the Data
The import sub-project (code / package) exposes 3 Flink jobs:
-
com.ververica.platform.FlinkCommitsToKafkaThis job uses the Github API to retrieve commit information from the master branch at github.com/apache/flink and writes it to a Kafka topic of your choice (we will present the schema further below). The job can be configured with main args like these: --start-date 2013-04-17 --kafka-server YOUR_KAFKA_SERVER --kafka-topic flink-commits
- com.ververica.platform.FlinkPullRequestsToKafkaSimilar to the Github commit log import job above, this uses the Github API to fetch pull request data towards Flink’s master. This job can be configured like the one above via main args like these:
--start-date 2013-04-17 --kafka-server YOUR_KAFKA_SERVER --kafka-topic flink-pulls
- com.ververica.platform.FlinkMailingListToKafkaThe third import job will fetch mailing list archives for the dev, user, and user-zh mailing lists and write them to Kafka topics flink-mail[-dev|-user|-user-sh] in a single job with main args like these:
--start-date 2014-04 --kafka-server YOUR_KAFKA_SERVER --kafka-topic flink-mail
All of these three jobs are streaming jobs that you could leave running and would then update the respective Kafka topics along the way. If you just want to work on a bounded data stream though, you can stop the import at any time, or stop with a savepoint and resume it at a later point in time. The current process is logged at INFO level as Fetching commits since <date> until <date>, Fetching pull requests since <date>, and Fetching mails from <date>.
Making the Data Available to Flink SQL
As you may know, in order to make any data available to Flink SQL, we have to create a (dynamic) table telling Flink how to access and de/serialize it. This can be easily done in a couple of CREATE TABLE DDL statements which can be executed one after another in Ververica Platform’s SQL editor. They will register the input streams with Ververica Platform’s internal SQL catalog so you can use these again in the future or make them available to your fellow colleagues.
The following two statements exemplify the table format for the commits table and the user mailing list table. A complete list of DDL statements to create all tables that were imported above is provided in our project’s README file. As you can see, they also contain a few specialities, e.g. flink_commits.filesChanged is a structured type on its own (an array of rows). For our purposes, a watermark delay of 1 day is also sufficient to account for any late input but beware, that in this case, you would have to wait for 1 day to pass before getting statistics (feel free to adapt). Similarly, adapt if you do not always want to read from the earliest offset - actually, you can also override any connector settings in your queries by specifying Dynamic Table Options. For our demo here, though, we will always do the same and can thus simplify our queries with a proper default definition.
flink_commits
CREATE TABLE `flink_commits` (
`author` STRING,
`authorDate` TIMESTAMP(3),
`authorEmail` STRING,
`commitDate` TIMESTAMP(3),
`committer` STRING,
`committerEmail` STRING,
`filesChanged` ARRAY<ROW<filename STRING, linesAdded INT, linesChanged INT, linesRemoved INT>>
`sha1` STRING,
`shortInfo` STRING,
WATERMARK FOR `commitDate` AS `commitDate` - INTERVAL '1' DAY
)
COMMENT 'Commits on the master branch of github.com/apache/flink'
WITH (
'connector' = 'kafka',
'topic' = 'flink-commits',
'properties.bootstrap.servers' = 'YOUR_KAFKA_SERVER',
'properties.group.id' = 'flink-analytics',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json',
'json.fail-on-missing-field' = 'false',
'json.ignore-parse-errors' = 'true'
);</row<filename>flink_ml_dev
CREATE TABLE `flink_ml_dev` (
`date` TIMESTAMP(3),
`fromEmail` STRING,
`fromRaw` STRING,
`htmlBody` STRING,
`subject` STRING,
`textBody` STRING,
WATERMARK FOR `date` AS `date` - INTERVAL '1' DAY
)
COMMENT 'Email summary of all messages sent to dev@flink.apache.org>'
WITH (
'connector' = 'kafka',
'topic' = 'flink-mail-dev',
'properties.bootstrap.servers' = 'YOUR_KAFKA_SERVER',
'properties.group.id' = 'flink-analytics',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json',
'json.fail-on-missing-field' = 'false',
'json.ignore-parse-errors' = 'true'
);Verifying the Setup
You can use each of the following statements to evaluate the expected input data as well as checking whether the setup itself is working. If you are prompted to create a session cluster for the SQL preview, then follow along and come back to the editor after it is running.
SELECT * FROM flink_commits LIMIT 10;
SELECT * FROM flink_pulls LIMIT 10;
SELECT * FROM flink_ml_dev LIMIT 10;
SELECT * FROM flink_ml_user LIMIT 10;
SELECT * FROM flink_ml_user_zh LIMIT 10;Note the preview can only show the result of one query at a time. You can select the query of interest and click “Run Selection” (or press Ctrl+Enter) to run the selection as shown below.
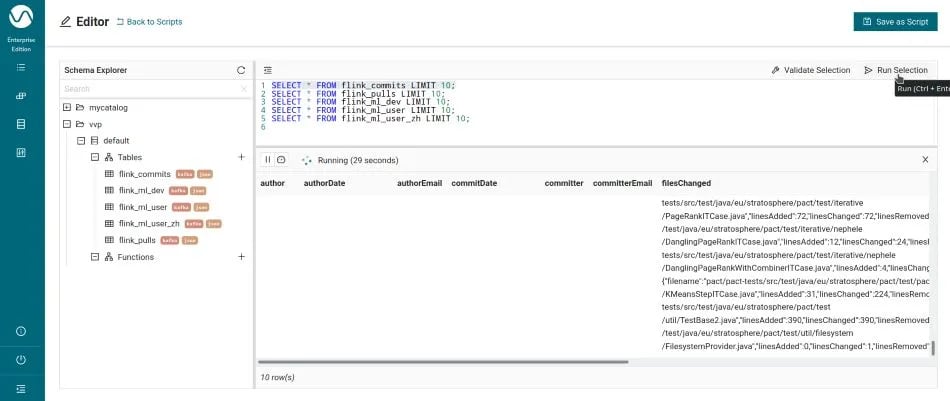
First Analytics
Given the data sets we imported above and the power of Flink SQL, you can easily derive a lot of insights into the Flink community. I actually presented a couple of insights in my special “A Year in Flink” talk during Flink Forward Global 2020 which featured a live coding session. Let me name a few (more) examples here:
-
number of distinct users/developers on the mailing list / the project, e.g. via
SELECT TUMBLE_END(`date`, INTERVAL '365' DAY(3)) as windowEnd, COUNT(DISTINCT fromEmail) AS numUsers FROM flink_ml_user GROUP BY TUMBLE(`date`, INTERVAL '365' DAY(3)); -
emails on the user mailing list with no reply within 30 days (similarly, you can also check the number of emails which got a reply to interpret the numbers here), e.g. via
SELECT SESSION_END(`date`, INTERVAL '30' DAY) AS windowEnd, thread, COUNT(*) as numMessagesInThread FROM ( SELECT *, REGEXP_REPLACE( TRIM(subject), '^(((?i)Re|AW):[ ]*)+', '') AS thread FROM flink_ml_user) WHERE `date` > (CURRENT_TIMESTAMP - INTERVAL '1' YEAR) GROUP BY SESSION(`date`, INTERVAL '30' DAY), thread HAVING COUNT(*) < 2; -
commit activity per month and Flink component
SELECT TUMBLE_END(commitDate, INTERVAL '30' DAY) AS windowEnd, component, SUM(linesChanged) AS linesChanged FROM ( SELECT *, REGEXP_EXTRACT(filename, '^(' || '.+?(?=/src/.*|pom.xml|README.md)' || '|(?:flink-)?docs(?=/.*)' || '|tools(?=/.*)' || '|flink-python(?=/.*)' || '|flink-end-to-end-tests/test-scripts(?=/.*)' || '|flink-scala-shell(?=/start-script/.*)' || '|flink-container(?=/.*)' || '|flink-contrib/docker-flink(?=/.*)' || '|flink-table/flink-sql-client(?=/.*)' || '|flink-end-to-end-tests(?=/[^/]*\.sh)' || ')', 1) AS component FROM flink_commits CROSS JOIN UNNEST(filesChanged) AS t) WHERE commitDate > (CURRENT_TIMESTAMP - INTERVAL '1' YEAR) GROUP BY TUMBLE(commitDate, INTERVAL '30' DAY), component HAVING SUM(linesChanged) > 1000; -
Jira tickets created per month and Jira component
SELECT TUMBLE_END(`date`, INTERVAL '30' DAY) as windowEnd, component, COUNT(*) as createdTickets FROM ( SELECT *, `KEY`) AS component FROM flink_ml_dev CROSS JOIN UNNEST( STR_TO_MAP( COALESCE( REGEXP_EXTRACT(textBody, '.* Components: ([^\n\r]*).*', 1), '' ), ', ', '$$$$THIS_SHOULD_NEVER_MATCH$$$$')) ) WHERE `date` > (CURRENT_TIMESTAMP - INTERVAL '1' YEAR) AND REGEXP(fromRaw, '"(.*)\s*\((?:Jira|JIRA)\)"\s*<jira@apache.org>') GROUP BY TUMBLE(`date`, INTERVAL '30' DAY), component HAVING COUNT(*) > 10;This seems rather complex and we will go into details further below where we see how to further simplify it with UDFs.
As you can see, a few of these queries need some regular expressions to interpret the raw data that we got from our sources. The flavour to use here is Java-based regular expressions, something that your data analysts may or may not be comfortable with. It is quite powerful though and gives us access to data we would otherwise not have, e.g. the Flink source component which we derived from the filename.
Using User-Defined Functions (UDFs)
For the remainder of this blog post, I would like to focus on leveraging user-defined functions to reduce the complexity of your SQL analytics, hide details like the Java-based regular expressions, and thus simplify usage for a wider audience.
Alternatively, you can already simplify a few things from SQL alone, e.g. by creating (temporary) views including derived fields so that your users can use these directly without knowing the details. Accounting for all derived fields may eventually become messy though. Your users can also create (temporary) views themselves but then need to know whenever the data format changes and need to adapt these views accordingly.
UDFs for Community Data Analytics
We would like to use user-defined functions to abstract the data extraction details away. For this, our development team has written a couple of Scalar Functions and put them into the sql-functions sub-project for us to use (code / package). We will focus on the following subset of functions:
-
NormalizeEmailThread(subject): STRING (code)Takes the subject field from a mailing list table and returns the normalized email-thread name, e.g. stripping it from any “Re:” and removing whitespaces as above.If needed, this can be extended as desired to further rule out false-positives from e.g. mismatches in spaces in the middle of the subject or other subtleties.
-
GetSourceComponent(filename): STRING (code)Takes a filename (relative to the Flink repository) and returns the Flink source code component it is associated with.
-
IsJiraTicket(fromRaw): BOOLEAN (code)Takes the fromRaw field from the dev mailing list table and returns whether the message originated from a mirrored Jira interaction (rather than from a user/developer).
-
GetJiraTicketComponents(textBody): ARRAY<STRING> (code)Parses the textBody field from the dev mailing list table and searches for a list of components in emails that come from created Jira tickets. If textBody is NULL, the result will be NULL as well, if no match is found, the result will be an empty array. In order to reduce load and reduce the chance for false positive matches, we recommend filtering out non-Jira messages with the IsJiraTicket function above.
You can either use the binaries that you created when building the project as presented above, or use the binaries that we created with the help of Github Actions and that we publish to Github Packages.
Making UDFs Available for Flink SQL in Ververica Platform
After retrieving (or building) the UDF artifact flink-repository-analytics-sql-functions-2.0.jar, we need to register it with Ververica Platform so that we can use it in SQL queries from then on. We will do that through Ververica Platform’s Web UI but you can also perform every of these steps in the REST API
-
Navigate to the Ververica Platform Web UI → SQL → Functions
-
Click “Register UDF Artifact” and select your flink-repository-analytics-sql-functions-2.0.jar. You should see the screen below
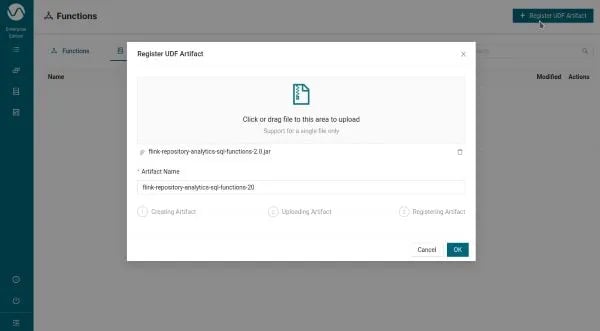
-
After clicking OK, you will be taken to the next screen where you can choose which functions in your jar file you want to be made available. You can continue with the defaults (all of them) or select a subset as needed.
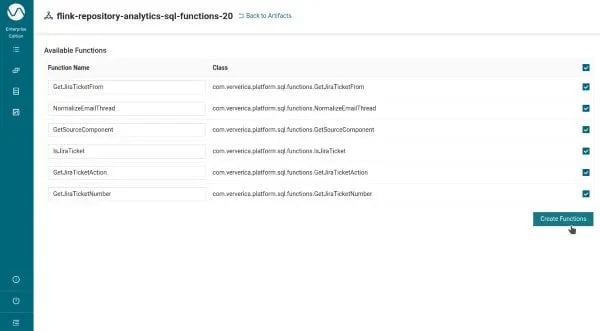 Feel free to customize the function names independently of the implementation class’ name if that one feels unnatural to SQL, and maybe use IS_JIRA_TICKET instead of IsJiraTicket, for example.
Feel free to customize the function names independently of the implementation class’ name if that one feels unnatural to SQL, and maybe use IS_JIRA_TICKET instead of IsJiraTicket, for example. -
Once created, you can go back to the SQL editor. You should see each of the registered functions in the default catalog:
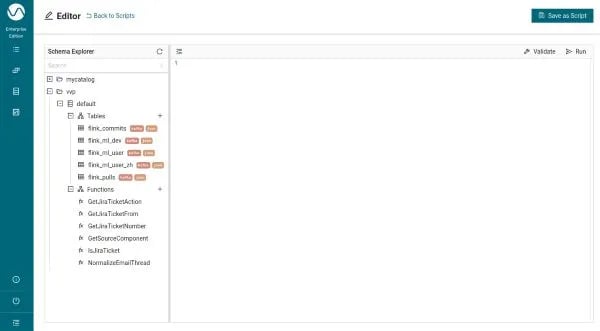
Using UDFs in SQL Queries with Ververica Platform
Once your functions are available in a SQL catalog, you can just use them right-away. Let’s take them for a test-drive, simplifying the queries we introduced above.
Emails on the user mailing list which haven’t received an answer within 30 days
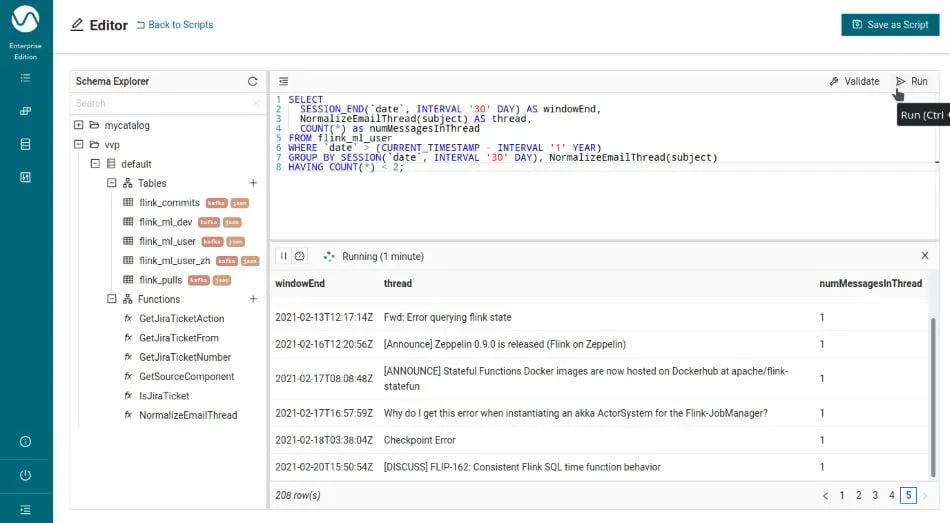
Since we do not have to repeat the (potentially complex) regular expression, we cannot only replace that with the UDF, but also flatten the query at the cost of repeating NormalizeEmailThread(subject) in two places. The query then simplifies to:
SELECT
SESSION_END(`date`, INTERVAL '30' DAY) AS windowEnd,
NormalizeEmailThread(subject) AS thread,
COUNT(*) as numMessagesInThread
FROM flink_ml_user
WHERE `date` > (CURRENT_TIMESTAMP - INTERVAL '1' YEAR)
GROUP BY SESSION(`date`, INTERVAL '30' DAY), NormalizeEmailThread(subject)
HAVING COUNT(*) < 2;After putting this into the SQL editor, you can just run the query with a click (or Ctrl+Enter) and see the results building up in the preview pane. Note that if you write the query yourself (or create a new one), you will actually also get auto-completion for SQL keywords and functions including the UDF we registered.
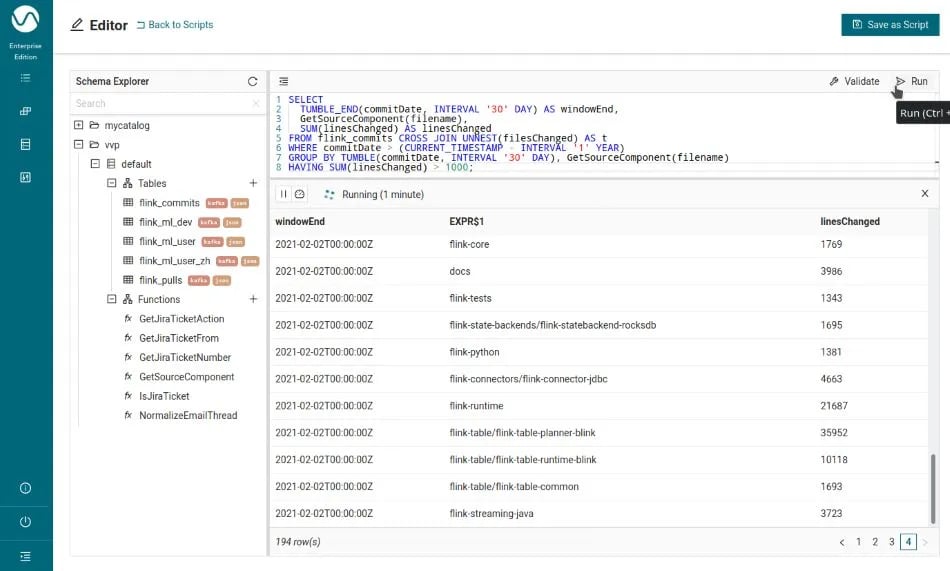
Commit activity per month and Flink component
This query can be simplified just like the query above, and once the UDF is available, we can concentrate on the actual analytics we want to do:
SELECT
TUMBLE_END(commitDate, INTERVAL '30' DAY) AS windowEnd,
GetSourceComponent(filename) AS component,
SUM(linesChanged) AS linesChanged
FROM flink_commits CROSS JOIN UNNEST(filesChanged) AS t
WHERE commitDate > (CURRENT_TIMESTAMP - INTERVAL '1' YEAR)
GROUP BY TUMBLE(commitDate, INTERVAL '30' DAY), GetSourceComponent(filename)
HAVING SUM(linesChanged) > 1000;The results are also not surprising with most of the changed lines in flink-runtime as well as the flink-table submodules:
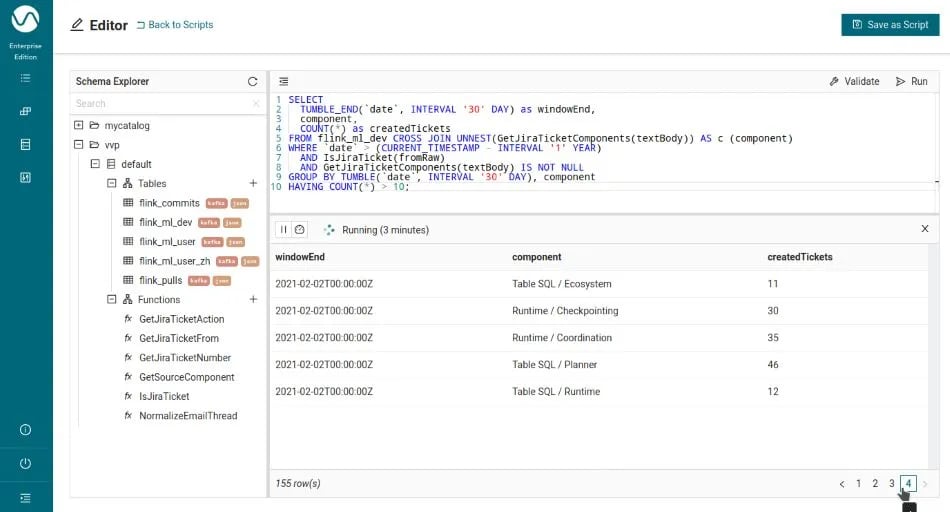
Jira tickets created per month and Jira component
First of all, let us digest the presented query a bit to understand it better. This is the original query:
SELECT
TUMBLE_END(`date`, INTERVAL '30' DAY) as windowEnd,
component,
COUNT(*) as createdTickets
FROM (
SELECT *, `KEY` AS component
FROM flink_ml_dev
CROSS JOIN UNNEST(
STR_TO_MAP(
COALESCE(
REGEXP_EXTRACT(textBody, '.* Components: ([^\n\r]*).*', 1),
''
),
', ', '$$$$THIS_SHOULD_NEVER_MATCH$$$$'))
)
WHERE `date` > (CURRENT_TIMESTAMP - INTERVAL '1' YEAR)
AND REGEXP(fromRaw, '"(.*)\s*\((?:Jira|JIRA)\)"\s*<jira@apache.org>')
GROUP BY TUMBLE(`date`, INTERVAL '30' DAY), component
HAVING COUNT(*) > 10;Although the source table flink_ml_dev contains a message for every created Jira ticket, this information is not structured and only available in the textBody field of the email such as this example:
Nico Kruber created FLINK-20099:
-----------------------------------
Summary: HeapStateBackend checkpoint error hidden under cryptic message
Key: FLINK-20099
URL: https://issues.apache.org/jira/browse/FLINK-20099
Project: Flink
Issue Type: Bug
Components: Runtime / Checkpointing, Runtime / State Backends
Affects Versions: 1.11.2
Reporter: Nico Kruber
Attachments: Screenshot_20201112_001331.png
<ticket contents>
Since this format is well-defined, we should be able to parse the ticket’s components out of the textBody field. For all content in the “Components” section, we use an appropriate regular expression that matches the start of the line and then extracts everything after “Components: “. What complicates things a little further is that there can actually be multiple components that are separated by commas. The current list of built-in SQL functions, however, does not include any that splits a string into an array of sub-strings based on a delimiter. We go around this by using STR_TO_MAP to create a map instead and put the substrings into its keys by using a key-value delimiter that never matches anything (alternatively, we could create our own SPLIT UDF and use that here, but once we start creating UDFs, we could just as well cover the whole use case as seen below). Finally, we can UNNEST this map with a CROSS JOIN as shown above.
Unfortunately, this query does not give us a perfect result either: there are a few Jira components that contain a comma themselves and break up into individual components with the code above. We are going to fix this in our UDF implementation where we have more possibilities to (iteratively) split strings up. You can find the details in the implementation of GetJiraTicketComponents. With that UDF and the additional help from the IsJiraTicket UDF to filter rows out early, the final SQL query simplifies to this:
-- Jira tickets created per month and Jira component with UDFs
SELECT
TUMBLE_END(`date`, INTERVAL '30' DAY) as windowEnd,
component,
COUNT(*) as createdTickets
FROM flink_ml_dev
CROSS JOIN UNNEST(GetJiraTicketComponents(textBody)) AS c (component)
WHERE `date` > (CURRENT_TIMESTAMP - INTERVAL '1' YEAR)
AND IsJiraTicket(fromRaw)
AND GetJiraTicketComponents(textBody) IS NOT NULL
GROUP BY TUMBLE(`date`, INTERVAL '30' DAY), component
HAVING COUNT(*) > 10;
If you run this query and compare the number of result rows in the preview pane with the number of the non-UDF query, you will also see that this gives fewer results which is due to the fixed matching of components that have commas in their names themselves. Feel free to browse through the set of pages at the bottom of the SQL editor to see further results. As more results come in, this list will be extended dynamically since any query you run here will be executed in streaming mode.
Behind the Scenes
Using UDFs in Ververica Platform does feel natural and as a user of the SQL editor, you do not have to worry about the details of how this works. This is exactly how it should be. You should not feel any difference between a built-in SQL function and a user-defined SQL function and Ververica Platform aims at providing this experience. Behind the scenes, of course, a couple of things are executed in order to provide this seamless integration experience to our users.
UDFs are registered in your SQL catalogs, e.g. by uploading them through the UI as shown above. This basically creates a link between the function names and the function implementation (a class inside a jar file). From then on, whenever you use a UDF in the SQL editor, the platform knows which artifact to deploy alongside your SQL statements so that the Flink job they create has all the necessary code to run. This applies to the preview job that is running in a special session cluster, as well as any (long-lived) SQL streaming application you create a deployment for, through (multiple) INSERT INTO statements.
Conclusion
In this blog post, we have shown how to do SQL analytics with user-defined functions (UDFs) in Ververica Platform. UDFs are a great way of sharing code across teams and projects, abstracting away complex logic, e.g. for parsing input data and extending the functionality of Flink’s SQL ecosystem in general. We have shown that, with the help of Ververica Platform, using UDFs is just as simple as using any other of Flink’s built-in functions. This allows you and your data scientists to get started easily without having to worry about the details behind the scenes. Make sure to also check our next article that extends our SQL analytics application by exploring Flink SQL queries in Ververica Platform that produce changelog streams, such as non-windowed aggregations, top-n queries, and more.
We encourage you to try out the steps above and take a closer look into the Flink community by using Flink itself to do the analytics. You can look into the user and developer mailing lists, Flink repository commits and pull requests and initial ticket (created) information. We are curious to hear about anything new and interesting that you can find out about the community with the help of this toolkit.

You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
