














Today’s guest author, Erik de Nooij, is an IT Chapter Lead at ING Bank, headquartered in The Netherlands.
ING serves 36 million customers in over 40 countries. 9 million of those customers are in The Netherlands, where the ING site processes over a billion logins per year and 1 million transactions per day.
Fraudulent transactions cost the banking industry large amounts of money every year. One of our bank’s most important goals is to protect both the bank and our customers from fraudulent transactions, where a bad actor misuses the banking system in some way for personal gains.
Most banks have rule-based alerting in place to detect potential fraud. Rule-based alerting works fine if you already know what you’re looking for, but we are living in a time where fraudsters are becoming more sophisticated.
One of the biggest threats is in the cybersecurity domain, the so-called “advanced persistent threat” (APT). A well-known example is the attack carried out by a group called Carbanak in 2013, which made it possible for the attackers to take over the IT systems of a number of banks (ING was not a target) and remotely distribute cash from compromised ATM machines at prearranged times, where “mules” were waiting to pick up the money. The attack started with a phishing email and ended up as one of the largest bank thefts in history.
It's critical for banks to build risk engines that allow them to respond to new, previously-unknown threats instantly. A year ago, ING started building a risk engine based on Apache Flink to stand up against the ever-evolving tactics of fraudsters.
We had 3 primary goals for our risk engine:
-
Support for a range of machine learning models: The risk engine should support both rule-based alerting and also be able to score machine learning models. I’ll go into detail later about the techniques used for creating versus scoring models.
-
A risk-engine that we built once but could deploy in different environments: The architecture of the Flink application had to be flexible enough so that it could be deployed in different departments and/or countries even if the underlying infrastructures differ.
-
Business users should be able to make changes instantly: Whenever a new fraud scenario or loophole in one of the existing models is detected, a business user should be able to stream a new or updated model into Flink. The new model should be active right away, without downtime or redeployments or any involvement from engineering teams.
Next, I’ll walk through how we achieved each of these 3 goals when building ING’s risk engine.
Support for a Range of Machine Learning Models
Our fraud detection system has 2 different environments: an offline environment and an online environment. In the offline environment, data scientists and other subject matter experts use tools like Knime and Apache Spark to create and train fraud detection models. Once trained, models are streamed into Flink, and Flink scores the model in real-time against incoming events.
For model transfer between the offline and online environments, we use PMML (Persistent Model Markup Language), an XML-based format, to save machine learning models. Many of the tools that data scientists use for model training support PMML as an export format, and so there’s almost no limit in terms of what you can use to build models in the offline environment.
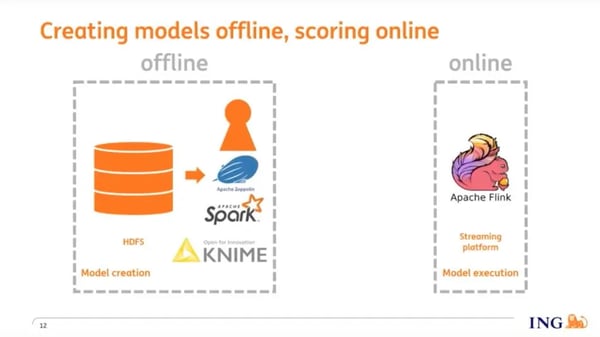 In the online environment, the PMML files are streamed into Kafka as events, then into Flink control streams and broadcast to a model-scoring operator. Within this operator, we use the OpenScoring.io library to:
In the online environment, the PMML files are streamed into Kafka as events, then into Flink control streams and broadcast to a model-scoring operator. Within this operator, we use the OpenScoring.io library to:
-
Parse PMML files into model objects and save them as ‘state’.
-
Pass the feature sets to the models from the data stream.
-
Score the models and emit the scores to a stream.
OpenScoring.io supports a number of different types of models, shown below:

Building the risk-engine once and being able to deploy it in different environments
As mentioned earlier, we wanted to build a risk engine that we are able to deploy in various countries where ING operates even though the IT infrastructures aren't uniform across these countries.
The architecture of our Apache Flink job is Kafka-in and Kafka-out. The input comes from multiple applications such as our banking website, the banking app, and other applications that post events, each on their own topic. Our Flink job ingests events from these topics then transforms them into features that serve as input to our models. The output of the models is then emitted to Kafka.
A problem is that the topics all have different schemas, and schemas can change over time. For example, let’s look at the transaction amount:

We addressed this issue by introducing a second Flink job we call the 'preprocessor'. The preprocessor is a technical filter, and it has 3 functions:
-
It filters out events that aren’t required by the feature extraction & model scoring job.
-
It aggregates multiple raw events (e.g. web clicks) into a single business event, e.g. a transaction, which is an aggregation of the raw events.
-
It consolidates events from all input topics, each with its own schema, into events on a single “business event” topic with a known consolidated schema.
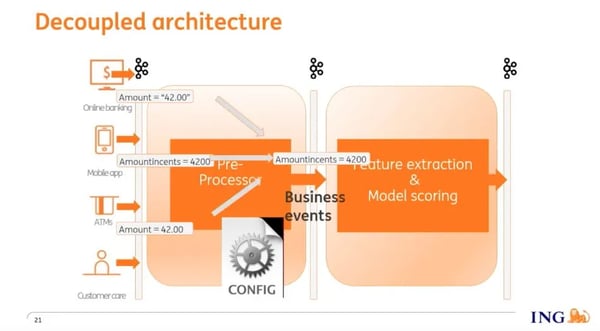 Now our feature extraction & model scoring job has one single, consistent input, the business event topic. This allows us to deploy the risk engine in different environments by prepending it with a preprocessor with the appropriate configuration.
Now our feature extraction & model scoring job has one single, consistent input, the business event topic. This allows us to deploy the risk engine in different environments by prepending it with a preprocessor with the appropriate configuration.
Make Changes Instantly (With No Downtime)
You can see the demo of how we stream in a new machine learning model with no downtime here. I’ll describe the demo in the section below, too.
To illustrate this point, let’s walk through a motivating use case.
Imagine that someone steals your phone which has the ING banking app installed. The thief knows your credentials, perhaps as a result of looking over your shoulder while you were using the app, and is able to sign into your account.
The banking app allows transfers of up to €1000 by default, and so the thief will make transfers of €1000 to a "mule account" until either you're out of money or the activity is detected by our risk engine and stopped.
What sorts of features would we consider in a model to detect fraudulent activity like this?
A few that come to mind are:
-
The transaction amount.
-
The number of recent (e.g. the last hour) transactions.
-
Whether money was sent to this recipient account for the first time in the past 24 hours (in other words, to an “unknown” recipient account).
So let’s assume we’re using a fraud detection model that will flag a transaction as fraudulent if a) the transaction amount is greater than €500, b) the beneficiary account is an ‘unknown’ account, and c) there’s been more than one transaction in the past hour.
Once this model is defined and created, we need to export it to a PMML file and stream that file into Flink via a control stream.
To test the model, we stream in a series of sample €1000 transactions with timestamps within the same hour. Eventually, the model will detect that this is an uncommon pattern and flag it as such. In our production environment, this will enable us to pause or block transactions in real time.
But the fraudster isn’t going to give up that easily and will possibly try a lower transaction amount to test if those larger transactions are not blocked. Our model only flags individual transactions greater than €500, and so the thief will be able to continue to transfer lower amounts to the mule account.
So apparently, there's a loophole in our model and we need to close it ASAP. We can easily change the model to look at the total transaction amount in the past hour rather than the amount of each individual transaction. Then we export the model to a PMML file and stream it in to replace the current one. Further attempted transactions will now be blocked regardless of the amount of the individual transaction, effectively closing the loophole instantly.
This is a simplified example, but hopefully, it clarifies the broader point. We’re able to constantly update our models to account for new types of attacks from fraudsters and have these models deployed by business users without letting down our guard in the meanwhile, with no downtime.
From this example, it’s clear that we use aggregates like count and sum, and to be able to do this we make use of Flink’s stateful operators. These operators enable us to record information from previous events that is used along with the current event to calculate the feature set (the inputs to the model).
What do we need to store into Flink state in this example? In the graphic below, you can see that we're storing when we saw the first transaction from account A to account B, and we are building up a time series of previous transactions that enable us to perform aggregates like the number of previous transactions that have taken place.
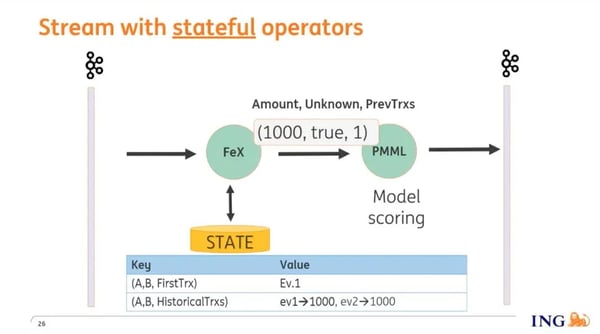
Based on its inputs, the model is able to detect uncommon patterns and flag them as such which allows us to pause or stop transactions.
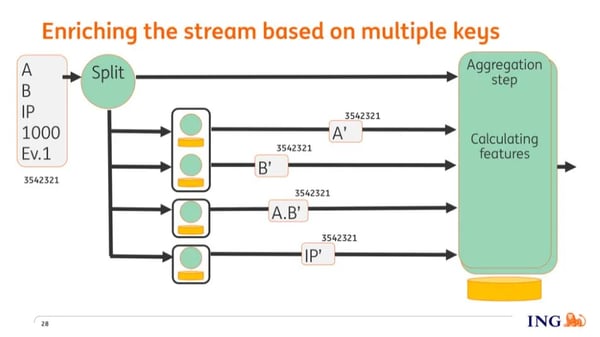
Events may have multiple (‘foreign’) keys, for example, device ID, IP address, etc that we want to enrich and correlate based on historical data. In Flink, however, a so-called "keyed stream" is based on a single key, so we can only enrich information by a single key.
To enrich an event based on multiple keys we extract the various (‘foreign’) keys from an event and emit them all, using a ‘flatMap’ operation, on the stream. Based on the values of the various keys, they end up on nodes where historical information related to those keys are stored, which we then use to enrich the keys.
The enriched keys are now on different nodes in the cluster and we need to get all that information together on a single node where we can compute the feature sets (the inputs needed by the models), so how do we do that?
For each event, we generate a random number that's passed as payload to the key. Once the keys have been enriched, they are keyed again, but this time not based on the value of the key and instead based on this random number. And since each key is now keyed based on the same number, they all end up on the same node where all information is aggregated. The feature sets are calculated and emitted on the stream, where further downstream they are scored by the models.
 Earlier, I mentioned that business users can create models, save them as PMML files, and deploy the models themselves. By now, I think it's clear that a user will also need to define how feature extraction needs to take place, that is, the transformation process from event to input of the model. Since we do not want users to be dependent on developers, we have parameterized everything and provided the user a DSL (domain-specific language) that allows them to describe the feature extraction process and then deploy the DSL along with the PMML file.
Earlier, I mentioned that business users can create models, save them as PMML files, and deploy the models themselves. By now, I think it's clear that a user will also need to define how feature extraction needs to take place, that is, the transformation process from event to input of the model. Since we do not want users to be dependent on developers, we have parameterized everything and provided the user a DSL (domain-specific language) that allows them to describe the feature extraction process and then deploy the DSL along with the PMML file.
To zoom in a bit more on the various parts of the DSL, the following is what needs to be described:
-
Which information from the event needs to be stored as state. Based on this, the Flink application knows which keys need to be extracted from the event and emitted on the stream.
-
How, based on the enriched keys and the current event, the feature sets need to be calculated.
-
The definition of the model and the mapping between the feature sets and the model.
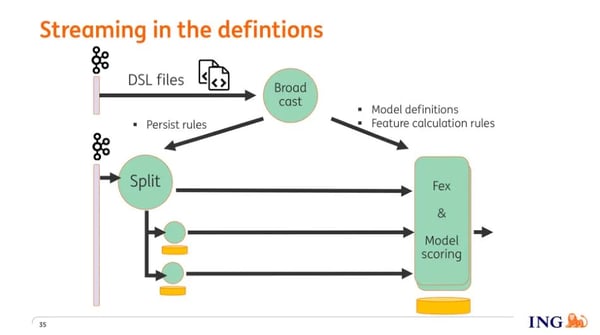
The last question to answer is how these models and definitions make it to the correct operators. Users save their files into version control, from where they are being pulled by a process that puts them on a specific topic on Kafka. The operator that ingests this information from Kafka parses this information and then does a broadcast to all the other operators. From that moment onwards the operators have the new behavior that has just been streamed in.
From Fraud Detection to Customer Notifications
Since we have parameterized everything, we have effectively built a platform that can be used for all kinds of other use cases as well, such as sending customer notifications based on customer profiles and behavior. We don’t foresee any coded changes that would be required to facilitate this sort of extension. It’s merely a matter of creating models and defining the transformations using a DSL.
If you’re interested in learning more about our broader streaming data platform based on Apache Flink, you can watch the Flink Forward Berlin talk from my colleagues Martijn Visser and Bas Geerdink or the keynote from Ferd Scheepers, our Chief Information Architect.


From Kappa Architecture to Streamhouse: Making the Lakehouse Real-Time

Fluss Is Now Open Source

Announcing Ververica Platform: Self-Managed 2.14
