














This is a guest blog post written by Gyula Fóra and Mattias Andersson from King.com. The original post can be found on the King Tech Blog.
This blogpost introduces RBEA (Rule-Based Event Aggregator), the scalable real-time analytics platform developed by King's Streaming Platform team. This new platform opens the doors to the world of stream analytics for our data scientists across the company. Here, we will describe what motivated us to build RBEA, how the system works, and how it is implemented on Apache Flink™.
King is a leading interactive entertainment company for the mobile world, with people all around the world playing one or more of our games. We offer games in over 200 countries and regions with franchises including Candy Crush, Farm Heroes, Pet Rescue, and Bubble Witch. With over 300 million monthly unique users and over 30 billion events received every day from the different games and systems, any stream analytics use-case becomes a real technical challenge. It is crucial for our business to develop tools for our data analysts that can handle these massive data streams while keeping maximal flexibility for their applications. We have already been using different stream processing technologies for several years to handle processing tasks on the live event streams, but until now complex stream analytics has only been in the toolbox of the software engineers, and an uncharted territory for the data scientists.
Background
At King we run what we think is a fairly straightforward backend architecture: 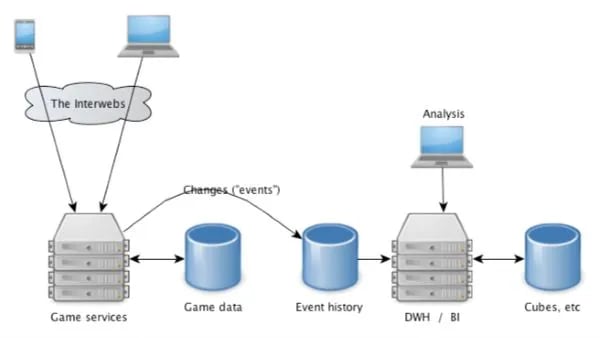 Game services are a set of Java servers that listen to requests or tracking calls from the clients. The player’s current progress and other associated states are stored in sharded MySQL servers (Game data). This data is only used by the actual game and the game teams own the data format. For analysis and other data needs outside of the core game we use the Event data. The Event data is a simple text log with a fixed schema (tab delimited text) that tells you what happened in the game. An example event describing a game start would look like this:
Game services are a set of Java servers that listen to requests or tracking calls from the clients. The player’s current progress and other associated states are stored in sharded MySQL servers (Game data). This data is only used by the actual game and the game teams own the data format. For analysis and other data needs outside of the core game we use the Event data. The Event data is a simple text log with a fixed schema (tab delimited text) that tells you what happened in the game. An example event describing a game start would look like this:
10005 SagaGameStart2(type) coreUserId(long) episode(int) level(int) gameRoundId(long)
In this case SagaGameStart2 indicates that a saga subgame has started, now including a game round id. The rest of the the fields contain information about the event. Example raw event:
0131017T113040.393+0200 17 10005 1006627249 7 12 1382002240393
Incoming events are stored in Kafka and are also written to files in HDFS. In our Hadoop cluster each event is mapped to a Hive table which makes it really easy to compute aggregates over the data and also do more complex batch analysis. A subset of the data is also loaded to an Exasol cluster for faster ad hoc querying and better support for complex SQL. We also compute real-time aggregates over the events using an in-house product called Nuevo, which aggregates data from all the Kafka streams into MySQL and provides a data source for release monitoring and real-time dashboards across King.
Challenges with our event model
Data warehouse engineers and data scientists usually work with relational data and the tools associated with it. Event stream data has a fairly different nature when it comes to complex analysis. As long as you are satisfied with basic aggregates or willing to make some simplifications you can usually solve most problems with basic SQL. But events at their heart are usually related to other events by just time and the context in which they happened. So when you start asking questions around what the user did before a game-start or how they navigated through your game (funnels, sessions, etc.) basic SQL is not the right language (non equi joins are expensive). So we usually have to fall back to a three-part solution whenever we wanted to relate different events:
-
Ask a game developer to add the context we want in game, such as placement, and relational key.
-
Select from the event tables in which we are interested, sort the events on player/time and run them through some code that associates the data, such as custom reducer.
-
Make a simplified model that we can run in SQL.
We want to avoid the first option because we want our game developers to build fun things in the game, not add tracking code. The second option always feels a bit inefficient in the daily processing, we store the events with one table per event and immediately follow up with many different queries that put them back in the order they happened with different constellations of events and you can only see that data when the daily batch has run. The third option is not always possible.
Problem statement
With RBEA, data scientists should be able to make the analysis in real-time that previously was only possible with custom reducers (or other tedious ways of creating event associations) on the already stored events. In practice this means that RBEA should support connecting events in time and storing contextual information for the events in a scalable way, while providing results directly from the live streams. The final product should be accessible to the game teams across King with easy-to-use web interfaces similarly to the systems we currently have in place for real-time aggregations.
What is RBEA?
RBEA is a platform designed to make large-scale complex streaming analytics accessible for everyone at King. We designed RBEA in a way that users can, with a few clicks, deploy Groovy scripts through a simple web interface and get instant results without worrying about the details of the deployment. This architecture relieves data analysts from the burden of managing large streaming clusters and deployments so they can focus on their application logic for maximal productivity. RBEA scripts run on King’s production Flink cluster delivering real-time results from the live event streams. Using RBEA, developers get easy access to wide range of stream analytics tools such as defining and updating user states, writing output to many different output formats or creating global aggregators across all the users. The RBEA API was developed to make everyday stream analytics tasks easy to write without any knowledge of the underlying streaming engine while still achieving good performance at scale.
A simple RBEA script
We will start by writing a simple script that counts all the finished games in 1-minute windows, while also writing the game end events to a text file:
def processEvent(event, context) {
def output = context.getOutput()
def agg = context.getAggregators()
// Create a counter with window size of 1 minutedef gameEndCounter = agg.getCounter("GameEnds", 60000
if (isGameEnd(event)) {// If this is a game end, increment countergameEndCounter.increment()// Simply write the event to a fileoutput.writeToFile("GameEndEvents", event)}}
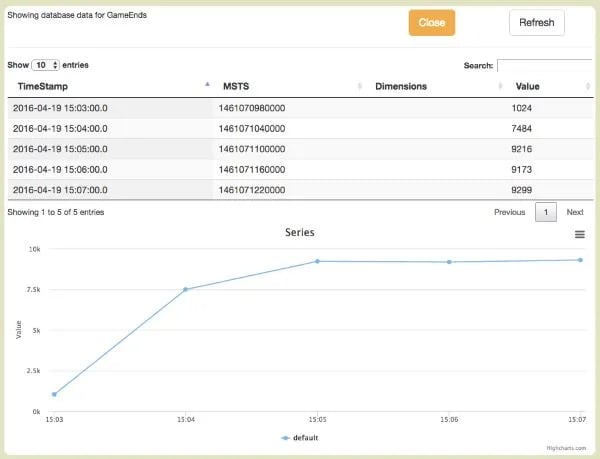
Cool, this looks super simple so let’s actually see what is going on in this script before going any further. Most of the things are self-explanatory: we defined a processEvent method that will receive the live events one-by-one. We get hold of the output object from the context and also create a counter called GameEnds with a window size of 1 minute (i.e., 60,000 milliseconds). For every incoming event we check whether this is a game end, and if so, we increment the counter and write the event to a text file named GameEndEvents. Now we can save our script as FinishedGames and click the Deploy button. The output of our job is accessible using the buttons that will quickly appear under our deployment:

In this case RBEA created a convenient MySQL table for our aggregator output that we can easily access by clicking the Show button for some instant data exploration:
The game end events written to the text file can also be accessed as expected and downloaded on demand from the servers.
State in RBEA programs
In most real-world applications, analysts would like to work with state that they compute for the users, such as the current session or current game. Computing state for the hundreds of millions of users has always been a challenge in analytics applications. While this has been possible to do in batch use-cases it was previously not possible in the real-time setting due to the high data rate and massive state size. This meant that real-time applications could only access stale user state (pre-computed by batch jobs) which often did not meet the application requirements. In RBEA we leverage Flink’s advanced state handling capabilities, allowing developers to create and update user states in real-time. RBEA provides a simple abstraction called Field that lets users define arbitrary user-state in a way that is transparent to the system. We can register new fields by passing them to the registerField(field) method of the Registry in the initialize method of our script. Fields are defined by specifying the following attributes:
-
Field name: String reference for accessing the value from the StateData
-
Update function: Defines how the Field will be updated for each incoming event. The update function comes in two flavors: (State, Event) -> State and (Context, Event) -> State.
-
Initializer: By default states are initialized to null, but we can also define an initializer function (UserID -> State) or the initial state value
The availability of Fields lends itself to very clean pattern for stateful streaming programs:
-
Define any state used by the application as Fields in the initialize method
-
For each event, access the state for the current user from the StateData
-
Enrich the current input and do the processing
Computing total transactions per level
Let’s look at a more exciting use-case where we want to compute total revenue per level in a game every half hour. Basically what we want here from the processEvent method’s perspective is that every time we get a transaction we would like to add the amount to an aggregator for the current level. The problem here is that transaction events don’t contain information about the current level. Whenever a player starts a new game, there is a game start event which contains the level information and subsequent transactions should belong to that level. To solve this use-case in our framework, we need to keep track of the current level for each player as a state. This is exactly the type of stateful application that Fields are designed for:
def agg = ctx.getAggregators()
def state = ctx.getStateData()
// Define sum aggregator with 30 minute window sizedef amountPerLevel = agg.getSumAggregator("Amount", 30*60*1000)
// We will write the aggregated values to a text file instead of MySQLamountPerLevel.writeTo(OutputType.FILE)
if(isTransaction(event)) {// Retrieve current level from stateInteger currentLevel = state.get("CURRENT_LEVEL")
// Increment counter for current levelamountPerLevel.setDimensions(currentLevel).add(getAmount(event))}}
def initialize(registry) {// Define current level state, initialized to -1def currentLevel = Field.create("CURRENT_LEVEL", {// Update the level for each new game startInteger prevLevel, Event e -> isGameStart(e) ? getLevel(e) : prevLevel}).initializedTo(-1)
// We register the state for this job so it is computed automaticallyregistry.registerField(currentLevel)}
We have registered the CURRENT_LEVEL field which automatically keeps track of which level each user is currently playing. This information can be easily accessed for the current player (based on the event) from the StateData as we can see in the processEvent method. Let’s deploy our application:
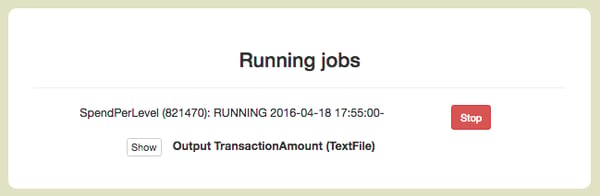
We can see that the TextFile containing the aggregated amounts per level can be accessed through the GUI. Clicking Show gives us what we expect:

Implementing RBEA on Apache Flink™
We have seen that the RBEA interfaces abstract away all the stream-processing internals from the users, including:
-
Reading event streams
-
Parallelizing script execution
-
Creating global windowed aggregators
-
Creating and updating user states
-
Writing output to many target formats
-
Fault-tolerance and consistency
Executing these abstractions in a way that it will scale to many parallel RBEA jobs, on the billions of events and millions of users every day is a challenging task for any streaming technology. Apache Flink™ might be the only open-source technology that supports this use case to the full extent. We have chosen Flink as it has several key features that are required for this use case:
-
Highly scalable state abstractions
-
Support for custom windowing logic
-
Support for cyclic dataflows
-
Exactly-once processing guarantees
Only one deployed and continuously running Flink job serves as a backend for all running RBEA scripts. The scripts are running in regular Flink operators (as described later) sharing the cluster resources in a very efficient way. Scripts deployed on the web frontend are sent to the already running Flink job, and the lifecycle management (adding/removing scripts, handling failures etc.) of the RBEA scripts is handled by the Flink operators themselves. Different RBEA operations (incrementing aggregators, writing output) are translated into different outputs for the Flink operators. Let’s look at a high-level overview of how RBEA scripts are deployed/executed on the Flink engine:
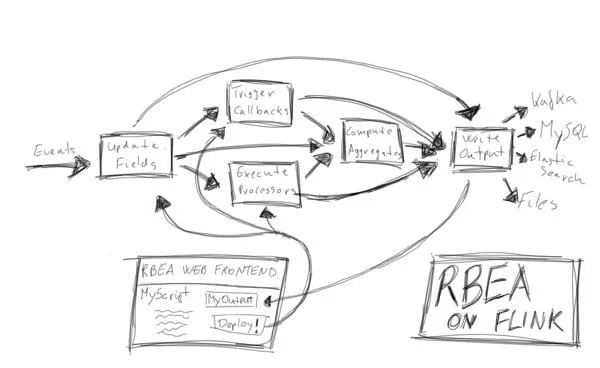
There are four main stages of computation:
-
Read event streams and receive newly deployed scripts
-
Update user states and run the processEvent methods of the deployed scripts
-
Compute windowed aggregates as produced by the scripts
-
Write the outputs to the selected format
Let’s look at these stages one-by-one.
Reading the events and scripts
The live event streams are read from Kafka with a modified Flink Kafka Consumer that tags events with the topic from where they are coming. This is important for us so users can freely decide what Kafka topics they want to listen to when running their scripts. We create a KeyedStream from our event stream keyed by the user id. Groovy scripts are received in text format from the web frontend through Kafka as simple events, and are parsed into to the appropriate Java EventProcessor interface. New scripts are hot-deployed inside the already running Flink job as described in the next section.
Computing states and running the scripts
User states are computed in the same operator where the scripts are executed to exploit data locality with Flink’s key-value state abstractions. For this we use a RichCoFlatMap operator which receives both the partitioned event streams and the broadcasted user scripts as events. For new events, we call the processEvent method of the already deployed RBEA scripts. For new scripts we hot-deploy them inside the operator so it will be executed for subsequent events. The following class shows the simplified implementation of the execution logic:
class RBEAProcessor extends RichCoFlatMapFunction<Event, DeploymentInfo, BEA> {
// Computed fields for the current userValueState<Map<String, Object>> = userStates;
// Omitted details...
public void flatMap1(Event event, Collector<BEA> out) {// Update states for the current userMap<String, Tuple2<?, ?>> updatedFields = updateFields(event, out);
// If any fields have changed we trigger the update callbacks on thosetriggerUpdateCallbacks(updatedFields, out);
// Call the processEvent methods of the user scriptsexecuteScripts(event, out);}
public void flatMap2(DeploymentInfo info, Collector<BEA> out) {// Instantiate the event processorEventProcessor proc = info.createProcessor();
// We add the processor to the listaddProcessor(proc);
// Call the initialize method of the processorinitializeProcessor(proc);}}
When the operator receives a new event it retrieves the current user state from the state backend, updates the states, then executes all the scripts that listen to the current topic. We are using the RocksDB state backend to persist our states, making sure it scales to our needs. During script execution most calls to the API methods are translated directly into output elements which are collected on the output collector. For example, when the user calls output.writeToFile(fileName, myData) in their script, the Flink operator emits an output that encodes the necessary information that our sinks will need to write the user data into the appropriate output format.
Different types of API calls (Aggregators, MySQL output, Kafka output, and so on) will, of course, result in different output information but they always contain the information that is enough for downstream operators to know how to deal with them. The operator also produces some information on the currently deployed processors, such as notification on failures. This is used for removing faulty scripts from all the subtasks and also to report the error back to the frontend so that users can easily fix their scripts. The CoFlatMap operator at the end produces three main types of output: data output, aggregation, and job information.
Computing window aggregates
We use Flink’s windowing capabilities to do the actual aggregation on the aggregator output coming out from our main processing operator. The information we receive is in the form of: (job_id, aggregator_name, output_format, window_size, value) RBEA at this point only supports sum aggregators and counters, but we are planning to extend the support to custom aggregators as well. Computing the window aggregates in this case is not a trivial task. First of all, we need to make sure we process the windows based on event time extracted from the events. Secondly we can’t really use the built-in time windowing implementations that assume fixed windows as every aggregate can have different window sizes. Practically, this means that we want different window sizes per key in our dataflow. Fortunately, Flink has solutions for both of our problems. We define timestamp extractors for the incoming event streams which operate directly on the consumed Kafka partitions for correct behaviour. To create different window sizes on the fly we use Flink’s flexible window mechanisms to define our window assigner that puts each element in the correct bucket based on the user-defined aggregator window. To do this properly, we extend the tumbling event time window assigner:
class AggregtionWindowAssigner extends TumblingEventTimeWindows {
public AggregtionWindowAssigner() {super(0);}
@Overridepublic Collection<TimeWindow> assignWindows(Object in, long timestamp) {BEA aggregateInput = (BEA) in;long size = aggregateInput.getWindowSize();
long start = timestamp - (timestamp % size);long end = start + size;
return Collections.singletonList(new TimeWindow(start, end));}}
Writing the outputs
As we have seen earlier, the user can output to many different output formats in their processing scripts. Each output record generated by calling the one of the output API methods will hold some metadata for the selected output format:
-
File output: file name
-
MySQL output: table name
-
Kafka: topic name
There is one operator for each output format that will write the received events using the metadata attached to them. These operators are not actually sinks in the Flink topology as they will have to produce some information for the web frontend so that it can show the generated output to the user. For instance when the File sink (flatmap) receives the first record to a new output file it outputs some meta-information for the web frontend so that it can display this file for the user for the running script.
Putting it all together
Now that we have seen how the main parts of the system work under the hood, it’s time to put the pieces together into our complete pipeline. There are a lot of subtle details that make the pipeline more complex than the initial description suggests that mostly have to do with communicating with the web frontend and handling script failures in a robust way. The full Flink logical pipeline looks like this:
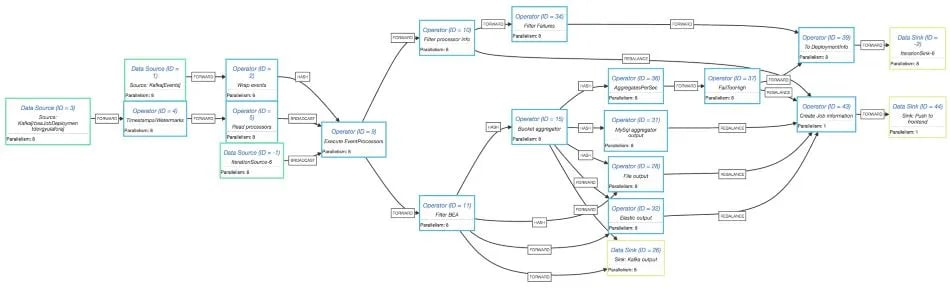
Some notable details:
-
The main processing operator (Execute EventProcessor) outputs two types of events:
-
Actual processing events generated by the scripts
-
Job information about deployment/failures and so on
-
-
Information about the errors in the scripts are shown on the web front-end for easier debugging
-
Output handling happens in FlatMap operators which forward newly created File/Table/...information to the web frontend
-
We use IterativeStreams to propagate job failures from one subtask to another
-
We monitor the number of events each script sends to the outputs and fail the scripts that generate too much to avoid crashing the whole system
-
We use Kafka queues as our communication protocol between the web interface and the Flink job to decouple the two systems
Summary
We have reached the end of our short story on RBEA. We hope you enjoyed learning about this cool piece of technology as much as we enjoy developing and using it. Our goal with RBEA was to build a tool for our data scientists that can be used to do complex event processing on the live streams, easily, without having to worry about any operational details. We believe that we achieved this goal in an elegant and maintainable way by using open-source technologies for all parts of the system.
We developed a DSL that is easy to use without any previous knowledge in distributed stream processing making RBEA accessible to developers across King. RBEA scripts are managed and executed in a novel runtime approach where events and script deployments are handled by single stream processing job that takes care of both processing (script execution) and the life-cycle management of the deployed scripts. We are impressed that Apache Flink™ has reached to a point of maturity where it can serve the needs of such a complex application almost out-of-the box. If you feel that something was unclear or you simply want to learn more about the system and the specific design choices we made, feel free to reach out to us!


About the AuthorsGyula FóraGyula is a Data Warehouse Engineer in the Streaming Platform team at King, working hard on shaping the future of real-time data processing. This includes researching, developing and sharing awesome streaming technologies. Gyula grew up in Budapest where he first started working on distributed stream processing and later became a core contributor to the Apache Flink™ project. Among his everyday funs and challenges, you find endless video game battles, super spicy foods and thinking about stupid bugs at night.
Mattias Andersson Mattias is a Data Scientist in the Streaming Platform team at King, works with almost all kind of data related projects be it data modeling, ab-tests, segmentation, notebooks, building ETL, setting up databases, scripting and lately java programming. Loves video games and Kings puzzle games and have designed a few levels in Candy Crush and Candy Crush Soda saga.

You may also like

Preventing Blackouts: Real-Time Data Processing for Millisecond-Level Fault Handling

Real-Time Fraud Detection Using Complex Event Processing

Meet the Flink Forward Program Committee: A Q&A with Erik Schmiegelow
