














PyFlink is a Python API for Apache Flink. It provides a way to write Flink programs in Python and execute them on a Flink cluster.
Some existing Ververica Platform users may be wondering whether they can run PyFlink jobs on Ververica Platform while other non-users may think that it is not possible to run their Flink jobs coded in Python on the platform. This tutorial will show you how you can run PyFlink jobs and Python User Defined Functions (UDFs) via a custom Flink Docker image with Python and PyFlink installed.
We will show you two ways to run Python code in your Flink jobs on Ververica Platform:
- run PyFlink jobs directly
- call Python UDFs in your Table API programs written in Java
If you would like to follow along, you can download the full example code from this post. We will be using Ververica Platform 2.8, Flink 1.15.2, and Python 3.8 in our example. Please change accordingly if you use different versions.
Prerequisites
This tutorial assumes that you have the following:
- A recent Ververica Platform installed and running with a Universal Blob Storage configured. Refer to the Ververica Platform Getting Started instructions if you do not have this set up yet.
- Familiarity with the Flink job lifecycle management on Ververica Platform. This short video will help you get started if you are not.
If you are running Ververica Platform 2.8 or earlier, or Ververica Platform 2.9 with Flink 1.13 or 1.14, you will need:
- A docker runtime to build Docker images
- A container registry to push your Docker images to
Create a custom Flink image that includes Python and PyFlink
In order to run PyFlink jobs or call Python UDFs, you first need a Python interpreter and PyFlink. These are included in the Flink 1.15.3 (or later) images that come with Ververica Platform 2.9 (or later). You can skip this section and use the built-in Flink images if you are using these Ververica Platform versions.
If you are using Ververica Platform 2.8 or earlier, or if you are using Flink 1.13/1.14 with Ververica Platform 2.9, follow these steps to build new Flink images that include a Python interpreter and PyFlink.
In your terminal, create an empty directory. In the directory, create a file named Dockerfile with the following content:
FROM registry.ververica.com/v2.8/flink:1.15.2-stream4-scala_2.12-java11
USER root:root
RUN apt update \
&& apt -y install python3.8 python3-pip \
&& python3.8 -m pip install apache-flink==1.15.2 \
&& apt clean \
&& ln -s /usr/bin/python3.8 /usr/bin/python \
&& rm -rf /var/lib/apt/lists/*
USER flink:flinkThis Dockerfile uses a Flink 1.15.2 image (provided by Ververica Platform 2.8) as its base image.
Build the docker image by using the docker build command:
docker build -t 1.15.2-stream4-scala_2.12-java11-python3.8-pyflink .Once the image is built, you can tag and push the image to a public or private container registry that is reachable by Ververica Platform:
docker tag
1.15.2-stream4-scala_2.12-java11-python3.8-pyflink:latest
<your container registry>/flink:1.15.2-stream4-scala_2.12-java11-python3.8-pyflink
docker push
<your container registry>/flink:1.15.2-stream4-scala_2.12-java11-python3.8-pyflinkCreate a Python UDF
In PyFlink, a Python UDF is a function written in Python that can be used in a Flink program. PyFlink provides a number of APIs for defining and using Python UDFs in Flink programs. Python UDFs are useful when you want to perform custom operations on your data that are not provided by the built-in functions in Flink, or when you want to use existing Python libraries in your Flink programs.
Throughout this tutorial, you will use a simple Python UDF which takes a string as input and returns it in capitalized form. This UDF can be found here if you want to follow along.
from pyflink.table.udf import udf
from pyflink.table import DataTypes
@udf(result_type=DataTypes.STRING())
def py_upper( str ):
"This capitalizes the whole string"
return str.upper()The annotation @udf(result_type=DataTypes.STRING()) is the glue that is needed to make this function available as a Python UDF. For other ways to define Python UDFs, please consult the official Flink documentation.
Run PyFlink Jobs on Ververica Platform
You will be running this PyFlink job on Ververica Platform. This job relies on the aforementioned Python UDF to work. You will run it with Flink’s PythonDriver in flink-python_2.12-1.15.2.jar. This is also how Apache Flink runs Python pipelines internally.
First, upload pyflink_table_example.py and my_udfs.py to Ververica Platform’s Universal Blob Storage via the menu bar on the left: Deployments > Artifacts
Then create your deployment with the following values:
|
Flink registry |
<your own container registry> (or registry.ververica.com/v2.9 if you are using the built-in images from Ververica Platform 2.9) |
|
Flink repository |
flink |
|
Flink Image Tag |
1.15.2-stream4-scala_2.12-java11-python3.8-pyflink (or use the built-in Flink images if it has Python and PyFlink included) |
|
Jar URI |
https://repo1.maven.org/maven2/org/apache/flink/flink-python_2.12/1.15.2/flink-python_2.12-1.15.2.jar (change the two Flink versions in the URL if you are using a different version) |
|
Entrypoint Class |
org.apache.flink.client.python.PythonDriver |
|
Entrypoint |
--python /flink/usrlib/pyflink_table_example.py --pyFiles /flink/usrlib/my_udfs.py |
|
Additional Dependencies |
Select both pyflink_table_example.py and my_udfs.py in the dropdown menu. |
The screenshot below is an example of how to do it on the Ververica Platform UI:
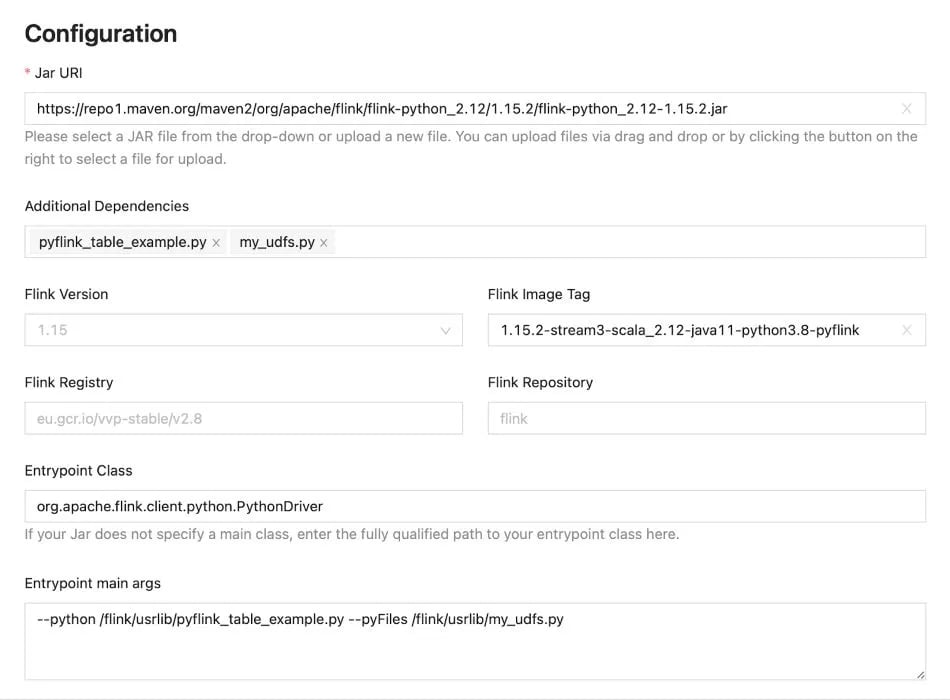
The directory /flink/usrlib is used in main args. When a Flink job starts, Ververica Platform will download the artifacts from its Universal Blob Storage to /flink/usrlib.
Now, you can start this deployment, which will run the PyFlink job. Since the job has a bounded data input, the deployment will eventually go to the FINISHED state with Flink pods being torn down. But you should be able to get the following result in the logs of the JobManager pod where the city column is capitalized as expected:
+----+----------------------+--------------------------------+
| op | id | city |
+----+----------------------+--------------------------------+
| +I | 1 | BERLIN |
| +I | 2 | SHANGHAI |
| +I | 3 | NEW YORK |
| +I | 4 | HANGZHOU |
+----+----------------------+--------------------------------+
Call Python UDFs in a Java Table API Job
Now that you have seen how to run PyFlink jobs on Ververica Platform, you can try calling Python UDFs from a Table API program written in Java. This is useful when several teams collaborate on Python UDFs. For example, one team of domain experts may develop Python UDFs and provide them to another team of Java developers for use in their Table API jobs. You will use this Table API job in this example, which also calls the aforementioned Python UDF my_udfs.py.
Before you run the Table API job, let's go over the essential pieces that make this work.
The first step is to add a job dependency. More specifically, youneed to add the dependency flink-python into our project and package it into the job jar. See the full pom.xml file for details. The dependency is where Flink’s PythonDriver exists.
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-python_2.12</artifactId>
<version>1.15.2</version>
<scope>compile</scope>
</dependency>Then, in the Table API job JavaTableExample, you need to inform your job where it can look for any UDF files. You can do this via PyFlink’s configuration python.files. Remember, /flink/usrlib is the directory where Ververica Platform downloads the artifacts to when it starts a Flink job.
tableEnv.getConfig().getConfiguration()
.setString("python.files", "/flink/usrlib/my_udfs.py");Next, call executeSql() to map the Python function my_udfs.py_upper (since the Python UDF is in a separate file, youneed to reference it with this format python_module.function_name) to a temporary system function PY_UPPER in Flink SQL.
tableEnv.executeSql("create temporary system function PY_UPPER as
'my_udfs.py_upper' language python");Now that PY_UPPER is registered in Flink SQL, you can use the function in your SQL statement.
tableEnv.sqlQuery(
"SELECT user, PY_UPPER(product), amount FROM " + table)Before you can run the job, you need to upload the Python UDF file my_udfs.py to Ververica Platform’s Universal Blob Storage. You can skip this if you have done so by following the steps in the earlier part of this blog post.
Then, package the job as a jar: go to the directory with the pom.xml file, run mvn clean package, and you will get the JAR file JavaTableExample-1.0-SNAPSHOT.jar under the directory target.
With the produced jar file, you can create a deployment as you normally do with any other jar-based deployments. The only two differences here are that you have to:
- make sure the custom Flink image
1.15.2-stream4-scala_2.12-java11-python3.8-pyflink(or the built-in one if it has Python and PyFlink included) is used - add the Python UDF file
my_udfs.pyas an additional dependency.
Now start this deployment. The Python UDF will be called during the job run. Similar to the previous example, this job also has a bounded data input, so the deployment will eventually go to the FINISHED state with Flink pods being torn down. But you should be able to get the following result in the Jobmanager pod logs where the product column is capitalized as expected:
+----+----------------------+--------------------------------+-------------+
| op | user | product | amount |
+----+----------------------+--------------------------------+-------------+
| +I | 1 | BEER | 3 |
| +I | 2 | APPLE | 4 |
+----+----------------------+--------------------------------+-------------+
Review the steps
Hopefully, you have successfully gone through this guide and have now seen how to run PyFlink jobs and Python UDFs on Ververica Platform. Let’s review the steps we just covered:
- Create a custom Flink container image with Python and PyFlink installed
- Run PyFlink jobs
- Upload PyFlink jobs and its UDFs to Ververica Platform’s Universal Blob Storage
- Use Flink’s PythonDriver to run PyFlink Jobs
- Reference the Python files in the main args.
- Deploy with the Python files as additional dependencies.
- Call Python UDFs in a Java based Table API program
- Upload Python UDFs to Ververica Platform’s Universal Blob Storage
- Include
flink-python_2.12as a dependency and package it into the job jar - Set
python.filesand register Python UDFs in the table environment - Deploy with the Python files as additional dependencies.
Summary
In this tutorial you created a custom Flink image with a Python interpreter and PyFlink in it. You then ran Python code in Flink jobs on Ververica Platform in two different ways:
- run PyFlink jobs with Flink’s PythonDriver
- call Python UDFs in a Java-based Table API program
Ververica Platform 2.9 makes it easier by providing a Python interpreter and PyFlink in its Flink 1.15.3 images out of the box.
As a next step, we are working on the native integration of PyFlink into Ververica Platform in order to further improve the overall PyFlink user experience. Stay tuned!

You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
