














The latest release of Ververica Platform introduces autoscaling for Apache Flink and support for Apache Flink 1.11
We are very excited to announce the release of Ververica Platform 2.2, the enterprise stream processing platform by the original creators of Apache Flink.
Ververica Platform enables every enterprise to continuously derive immediate insight from its data and better serve its customers in real-time. It is powered by the leading stream processing framework, Apache Flink, and provides an integrated, enterprise-ready solution for secure, scalable, and cost-effective stateful stream processing and streaming analytics.
Let us focus on what's new in Ververica Platform 2.2: Ververica Platform 2.2 comes with two major features, autoscaling of Apache Flink applications and support for Apache Flink 1.11, as well as a number of minor improvements.
Besides working on the functionality for this release, the team at Ververica has already put countless development hours into our integrated solution for Flink SQL. If you are interested to learn more about Flink SQL on Ververica Platform.
Ververica Platform Autopilot: Autoscaling for Apache Flink
Stream processing applications are by nature long-running, continuous applications. As such, their workload usually varies greatly over their lifetime due to, for example,
-
daily, weekly or seasonal load patterns
-
higher or lower popularity of a service, feature or product over its lifetime
-
processing a surge of data
When a stream processing application cannot keep up anymore, records will start to pile up in your streaming storage system (e.g. Apache Kafka® or Apache Pulsar®) and your application will process records with increasing delay. Consequently, you might break your latency objectives, drop end user requests, or lose data that is not consumed within its retention time. Operators of such systems will, on the one hand, continuously monitor the application and, on the other hand will err on the side of caution and overprovision the application as the cost of underprovisioning often exceeds the cost of overprovisioning. The result is a wastage of human and computational resources.
Autoscaling Apache Flink
Ververica Platform aims to tackle this challenge for stream processing with Apache Flink. More specifically, it continuously monitors your Apache Flink applications and tries to converge to a resource configuration that is backpressure-free while also minimizing excess capacity.
When data rates increase, Ververica Platform Autopilot — available in the Stream and River Editions of Ververica Platform — will scale out your application so that it continues to keep up with all of its sources. In such a backpressure-free configuration, latency is automatically kept to a minimum.
When data rates decrease, Autopilot will scale in based on the utilization of your pipeline while still maintaining a backpressure-free configuration.
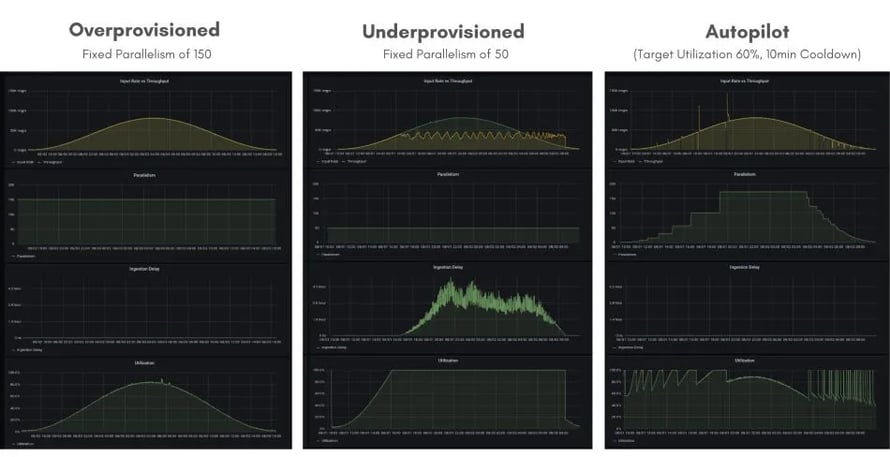 Figure 1: Throughput, parallelism, ingestion delay and utilization of a Flink application over 24 hours under varying loads. On the left the application is overprovisioned with a fixed parallelism of 150, in the middle the application is overprovisioned or underprovisioned depending on the time of the day with a fixed parallelism of 50 and on the right autopilot rescales the application based on the incoming data rate as well as the utilization of the pipeline.
Figure 1: Throughput, parallelism, ingestion delay and utilization of a Flink application over 24 hours under varying loads. On the left the application is overprovisioned with a fixed parallelism of 150, in the middle the application is overprovisioned or underprovisioned depending on the time of the day with a fixed parallelism of 50 and on the right autopilot rescales the application based on the incoming data rate as well as the utilization of the pipeline.
When developing a new stream processing application it is initially very hard to define parallelism and resource limits that sustain the anticipated throughput. With Autopilot this becomes a much easier task: start your application with parallelism of 1 (or a best guess) and let Autopilot converge to a resource efficient, backpressure-free state.
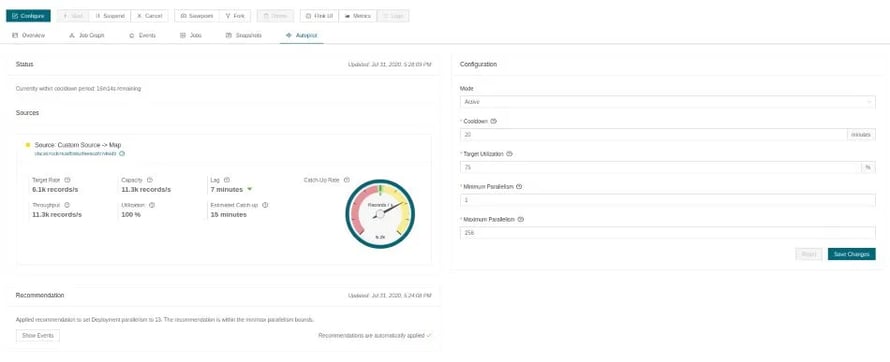
Figure 2: The Ververica Platform Autopilot web user interface showing the status of the job (left) and the autoscaling configuration (right). In this figure, the job is currently processing a backlog of data and catching up.
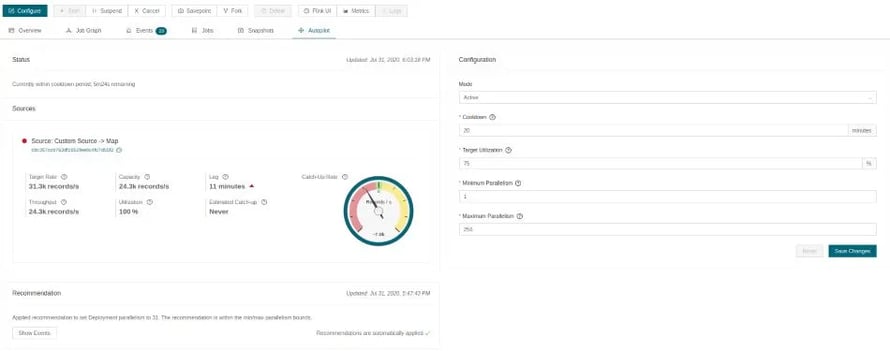
Figure 3: The Ververica Platform Autopilot web user interface showing the status of the job (left) and the autoscaling configuration (right). In this figure, the job is slowly falling behind and Autopilot will soon recommend to scale out.
Please check out the Ververica Platform documentation for more details about the concepts, configuration options and assumptions of Ververica Platform Autopilot.
Future Work
This release only marks the beginning of our efforts in the area of Flink-specific autoscaling and auto-configuration features. There are a lot of exciting ideas and approaches to be pursued mid-term, but three specific improvements are already under way: support for additional sources, vertical scaling, and improved down-scaling controls.
Support for Additional Sources
Ververica Platform Autopilot relies on an estimate of the target input rate for all sources of your Apache Flink application. In this release, we can automatically estimate this rate only for Apache Kafka® sources. Over the next months we will add support for more sources as well as the ability to specify the desired throughput manually, in case it cannot be derived automatically for the current source connector.
Vertical Scaling
In this initial release, Ververica Autopilot is limited to horizontal scaling, i.e. Autopilot will adjust the parallelism of the application as well as the number of TaskManagers. As of now, Autopilot will not scale the TaskManagers vertically before scaling them out horizontally. Support for vertical scaling is planned for upcoming Ververica Platform releases.
Improved Downscaling Controls
As you can see in Figure 1, our algorithm tends to scale down conservatively leading to many subsequent downscaling operations when load decreases monotonically over a longer period of time. While this behavior is already configurable internally we believe there is great benefit in exposing this in a more explicit and consistent way in the future.
Apache Flink/Flink 1.11
Ververica Platform 2.2.0 comes with support for Flink 1.11 and Flink 1.10. Apache Flink 1.9 is deprecated in this platform release and only supported on a best-effort basis.
Apache Flink 1.11 was released on July 6 and came with many exciting features throughout the whole stack, too many to cover them all in this post. In the following sections I will focus on the features and improvements that I believe impact Ververica Platform users and customers the most.
Operations & Deployment
Unaligned Checkpoints (FLINK-14551)
Asynchronous Barrier Snapshots (short: Checkpointing) are the foundation of Flink’s lightweight fault-tolerance mechanism. The system takes periodic, consistent checkpoints of the application state and rolls back to the latest completed checkpoint when recovering from a failure. “Checkpoint Alignment”, one of the steps of performing a checkpoint, has proven to be problematic under backpressure. More specifically, alignment times can become high and unpredictable resulting in stalled pipelines & checkpoint timeouts.
To improve the performance of checkpointing under backpressure, the community has rolled out the first iteration of unaligned checkpoints with Flink 1.11. When enabled, checkpoint duration becomes independent of the current throughput of the pipeline. For more information and current limitations checkout the Apache Flink documentation.
Relocatable Savepoints (FLINK-5763)
Savepoints are a consistent, point-in-time snapshot of the distributed state of a Flink application. They are typically used for application or framework upgrades, migration or simply as backups. So far, it was not possible to move a savepoint move a savepoint after it has completed. Hence, when migrating an application from one cluster to another both clusters needed access to the same distributed file system. Flink 1.11 makes savepoints fully self-contained and relocatable.
Execution Configuration via the Flink Configuration (FLINK-14785)
Flink 1.11 (and Flink 1.10) allows to pass all execution configurations via the flink-conf.yaml. This includes configuration options like the checkpointing interval, the auto-watermark interval or time characteristic, all of which were previously only configurable in code. Being able to control such operational aspects or your application via the configuration is very valuable. Passing execution configurations through the Flink configuration in Ververica Platform allows to, first, set reasonable defaults for such configurations and, second, to warn users if they are using platform features like the LATEST_STATE upgrade strategy without configuring the execution environment accordingly.
Improvements to the Flink Web User Interface
Flink 1.11 includes a number of improvements to its web user interface. Most notable features are the ability to trigger and analyze TaskManager thread dumps directly from the web user interface (FLINK-14816) and improved backpressure detection (FLINK-14127).
Metrics Reporters as Plugins (FLINK-16222)
Like file systems, metrics reporters can now be loaded as plugins. This allows us to bundle more metrics reporters in our distribution of Apache Flink without risking additional classloading conflicts.
Table API & SQL
A Good File System Connector
Flink 1.11 introduces a new file system connector for the Table API & SQL. It is based on the battle-tested StreamingFileSink of the DataStream API providing exactly-once delivery guarantees and handling bounded and unbounded inputs transparently. While the legacy filesystem connector only supported CSV, the new file system connector introduced in Flink 1.11 supports CSV, Apache Parquet®, ORC, Apache Avro® and JSON formats.
In addition, the new connector comes with a special treat for all Hive users: when ingesting a stream into a partitioned Hive table, the file system connector will add the partition to the HiveMetastore once partitioning is complete.
Ingestion of Changelogs & CDC Formats
So far, Flink’s SQL engine has only been able to ingest so-called append streams, meaning every ingested record is interpreted as a new row in a dynamic table. With Flink 1.11 the community added support for ingesting upsert streams or changelogs.
In practice, you can now read changelogs created by popular change data capture (CDC) tools like Debezium or Canal, further process them with Flink SQL and finally write them to any downstream system supported by Apache Flink. A particularly popular application is materialized view maintenance using Flink SQL in order to reduce load on source systems and benefit from Flink’s advanced SQL features like temporal table joins.
Other Improvements
Universal Blob Storage
Ververica Platform comes with Universal Blob Storage, a feature that centrally manages the blob storage requirements of all platform components. For example, all your Apache Flink clusters can be automatically configured to consistently use the desired blob storage provider for savepoints, checkpoints and high-availability storage.
So far, Ververica Platform has been supporting AWS S3 and Azure Blob Storage. With Ververica Platform 2.2.0 we are adding support for Apache Hadoop® HDFS 2.x and Apache Hadoop® HDFS 3.x including authentication & authorization via Kerberos.
Suspend with Draining
When a Deployment is suspended or a stateful upgrade is triggered, Ververica Platform shuts down the Apache Flink application via the stop command. This will atomically trigger a savepoint and stop the job. In addition to that, you can now instruct Ververica Platform to additionally drain the pipeline prior to stopping it.
This allows you to fully shut down your job without leaving any unhandled events or state behind. Another common scenario for this is an incompatible job upgrade: draining allows you to preserve important state such as Kafka offsets while flushing out incompatible state entries prior to the upgrade.
SQL Server Support for Platform Persistence
Besides MySQL and PostgreSQL, Ververica Platform now supports SQL Server as a persistence backend. On Microsoft Azure, support for SQL Server was the missing building block for automatic availability zone failover for your Apache Flink applications.
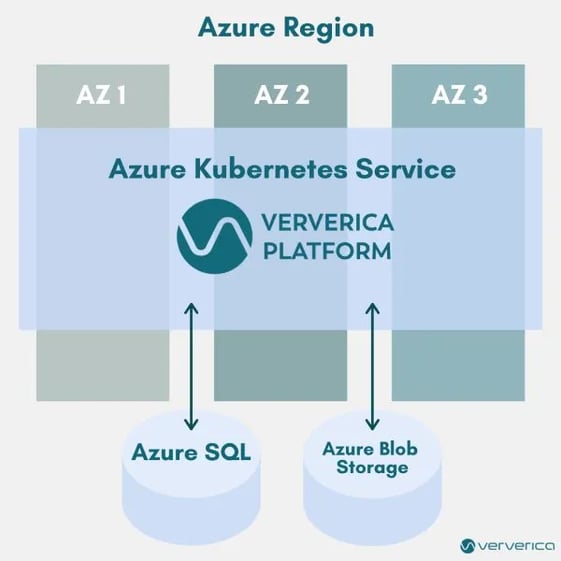 Figure 4: High Level Architecture of multi-availability zone of Ververica Platform installation on Microsoft Azure
Figure 4: High Level Architecture of multi-availability zone of Ververica Platform installation on Microsoft Azure
What’s next?
With the wide variety of improvements in Flink 1.11 on the one hand, and Ververica Platform Autopilot on the other hand, Ververica Platform 2.2 is probably one of the most anticipated platform releases so far. And that’s probably only until the next one: the team at Ververica — together with our Early Access Program users — is already working full steam ahead towards the general availability of Flink SQL in Ververica Platform later this year. Excited? Stay tuned for more updates and announcements in the coming months!
As always we are looking forward to your feedback and thoughts on the current release and latest features. Please do not hesitate to reach out directly to our product team.



You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
