














This tutorial will show how to quickly build streaming ETL for MySQL and Postgres based on Flink CDC. The examples in this article will all be done using the Flink SQL CLI, requiring only SQL and no Java/Scala code or the installation of an IDE.
Let’s assume that you are running an e-commerce business. The data of products and orders is stored in MySQL and the shipments corresponding to the orders are stored in Postgres. In order to make an analysis of the order table easier, you need to combine it with the relevant commodity and logistics data to create a new table and write it to ElasticSearch in real time.
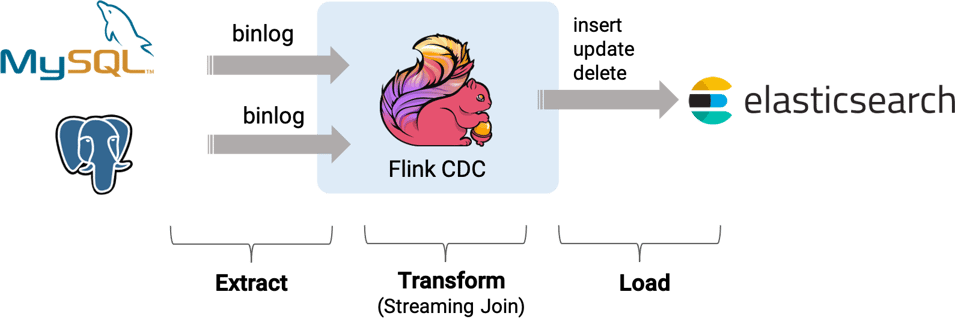
The overall architecture of the system can be summarized in the following figure:
Prerequisites
- preferably, a clean Linux installation on bare metal or virtual machine
- install Docker Engine
- download Flink 1.16.0
- download flink-sql-connector-elasticsearch7-1.16.0.jar
- download flink-sql-connector-mysql-cdc-2.4-SNAPSHOT.jar
- download flink-sql-connector-postgres-cdc-2.4-SNAPSHOT.jar
Step 1: Create a docker-compose.yml file
Copy the following content into your docker-compose.yml file:
version: '2.1'
services:
postgres:
image: debezium/example-postgres:1.1
ports:
- "5432:5432"
environment:
- POSTGRES_DB=postgres
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=postgres
mysql:
image: debezium/example-mysql:1.1
ports:
- "3306:3306"
environment:
- MYSQL_ROOT_PASSWORD=123456
- MYSQL_USER=mysqluser
- MYSQL_PASSWORD=mysqlpw
elasticsearch:
image: elastic/elasticsearch:7.6.0
environment:
- cluster.name=docker-cluster
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- discovery.type=single-node
ports:
- "9200:9200"
- "9300:9300"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
kibana:
image: elastic/kibana:7.6.0
ports:
- "5601:5601"The containers in this docker-compose file include:
- MySQL: products table and order table will be stored in this database
- Postgres: shipments table will be stored in this database
- Elasticsearch: the final enriched_orders table will be written to Elasticsearch
- Kibana: will be used to visualize ElasticSearch data
Create a directory for this project, e.g. <my-project> directory and move the docker-compose file to that directory.
Execute the following command in the same directory to install the components needed for this how-to guide:
docker-compose up -dThis command will automatically start all containers defined in the Docker Compose configuration in the detached mode. You can use “docker ps” to observe whether the mentioned containers are running or not, visit http://localhost:5601/ to check Kibana.
Step 2: Download Flink and the required dependencies
Download Flink 1.16.0 and extract it in your <my-project> directory.The extracted directory will simply be called Flink 1.16.0.
tar -xvf flink-1.16.0-bin-scala_2.12.tgzDownload the dependencies listed below:
- flink-sql-connector-elasticsearch 7-1.16.0.jar,
- flink-sql-connector-mysql-cdc-2.4-SNAPSHOT.jar,
- flink-sql-connector-postgres-cdc-2.4-SNAPSHOT.jar,
You can also compile the snapshots locally. Clone the repository and follow these instructions. Remember that the snapshots must be 2.4 CDC version.
Place these dependencies in
flink-1.16.0/lib/Step 3: Check MySQL server timezone
Make sure that the MySQL server has a timezone offset that matches the configured time zone on your machine.
Enter the MySQL container.
sudo docker-compose exec mysql bashCheck MySQL timezone of My SQL time by running one of the commands below:
mysql -e "SELECT @@global.time_zone;" -p123456or
mysql -e "SELECT NOW();" -p123456Set the time that matches your local machine if there is a time discrepancy. Remember to change the UTC accordingly in the command below.
mysql -e "SET GLOBAL time_zone = '+1:00';" -p123456Make sure that the timezone has been set.
mysql -e "SELECT @@global.time_zone;" -p123456Leave the container.
exitStep 4: Prepare data in the MySQL database
Enter the MySQL container.
docker-compose exec mysql mysql -uroot -p123456Create a database, products table, orders table, and insert data.
-- MySQL
CREATE DATABASE mydb;
USE mydb;
CREATE TABLE products (
id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
description VARCHAR(512)
);
ALTER TABLE products AUTO_INCREMENT = 101;
INSERT INTO products
VALUES (default,"scooter","Small 2-wheel scooter"),
(default,"car battery","12V car battery"),
(default,"12-pack drill bits","12-pack of drill bits with sizes ranging from #40 to #3"),
(default,"hammer","12oz carpenter's hammer"),
(default,"hammer","14oz carpenter's hammer"),
(default,"hammer","16oz carpenter's hammer"),
(default,"rocks","box of assorted rocks"),
(default,"jacket","water resistent black wind breaker"),
(default,"spare tire","24 inch spare tire");
CREATE TABLE orders (
order_id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,
order_date DATETIME NOT NULL,
customer_name VARCHAR(255) NOT NULL,
price DECIMAL(10, 5) NOT NULL,
product_id INTEGER NOT NULL,
order_status BOOLEAN NOT NULL -- Whether order has been placed
) AUTO_INCREMENT = 10001;
INSERT INTO orders
VALUES (default, '2020-07-30 10:08:22', 'Jark', 50.50, 102, false),
(default, '2020-07-30 10:11:09', 'Sally', 15.00, 105, false),
(default, '2020-07-30 12:00:30', 'Edward', 25.25, 106, false);Leave the container.
exitStep 5: Prepare data in the Postgres database
Enter the Postgres container.
docker-compose exec postgres psql -h localhost -U postgresCreate a shipments table and insert data.
-- PG
CREATE TABLE shipments (
shipment_id SERIAL NOT NULL PRIMARY KEY,
order_id SERIAL NOT NULL,
origin VARCHAR(255) NOT NULL,
destination VARCHAR(255) NOT NULL,
is_arrived BOOLEAN NOT NULL
);
ALTER SEQUENCE public.shipments_shipment_id_seq RESTART WITH 1001;
ALTER TABLE public.shipments REPLICA IDENTITY FULL;
INSERT INTO shipments
VALUES (default,10001,'Beijing','Shanghai',false),
(default,10002,'Hangzhou','Shanghai',false),
(default,10003,'Shanghai','Hangzhou',false);Leave the Container.
exitStep 6: Start Flink cluster and Flink SQL CLI
Use the following command to change to the Flink directory.
cd flink-16.0Start the Flink cluster with the following command:
./bin/start-cluster.shIf the start-up is successful, you can access the Flink Web UI at http://localhost:8081/, as shown below.
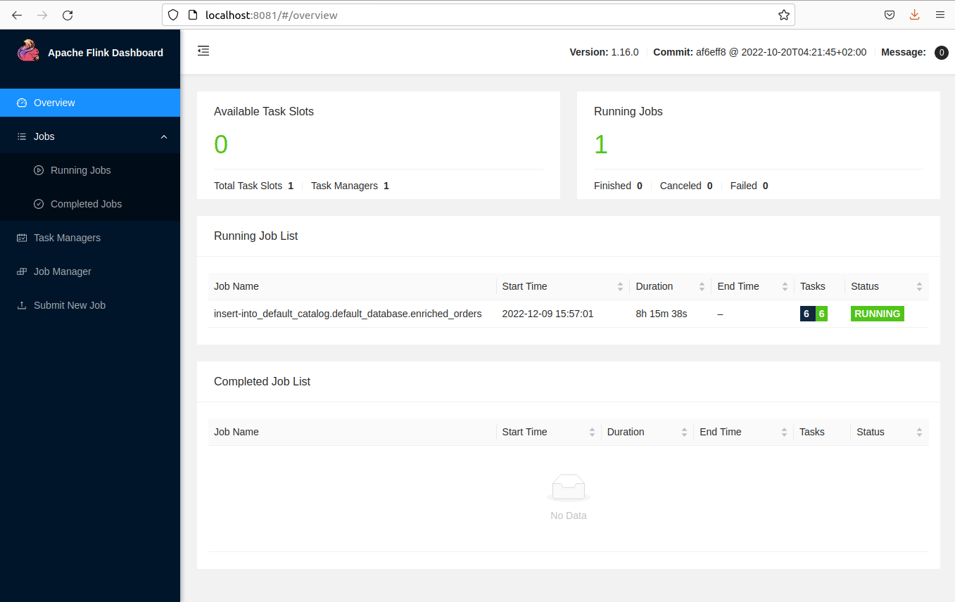
Start the Flink SQL CLI with the following command.
./bin/sql-client.shAfter the start-up is successful, you can see the following page:

Step 7: Create tables using Flink DDL in Flink SQL CLI
First turn on the checkpoint and do a checkpoint every 3 seconds.
SET execution.checkpointing.interval = 3s;Using the Flink SQL CLI, create tables that correspond to the products, orders, and shipments tables in the database for the purpose of synchronizing the data from these databases.
CREATE TABLE products (
id INT,
name STRING,
description STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'mydb',
'table-name' = 'products'
);
CREATE TABLE orders (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'mydb',
'table-name' = 'orders'
);
CREATE TABLE shipments (
shipment_id INT,
order_id INT,
origin STRING,
destination STRING,
is_arrived BOOLEAN,
PRIMARY KEY (shipment_id) NOT ENFORCED
) WITH (
'connector' = 'postgres-cdc',
'hostname' = 'localhost',
'port' = '5432',
'username' = 'postgres',
'password' = 'postgres',
'database-name' = 'postgres',
'schema-name' = 'public',
'table-name' = 'shipments'
);Finally, create an enriched_orders table to write the associated orders data to Elasticsearch.
CREATE TABLE enriched_orders (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
product_name STRING,
product_description STRING,
shipment_id INT,
origin STRING,
destination STRING,
is_arrived BOOLEAN,
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://localhost:9200',
'index' = 'enriched_orders'
);Step 8: Join the orders data and write it to Elasticsearch
Use Flink SQL to join the orders table with the product table and shipments table, and write the enriched_orders table into Elasticsearch.
INSERT INTO enriched_orders
SELECT o.*, p.name, p.description, s.shipment_id, s.origin, s.destination, s.is_arrived
FROM orders AS o
LEFT JOIN products AS p ON o.product_id = p.id
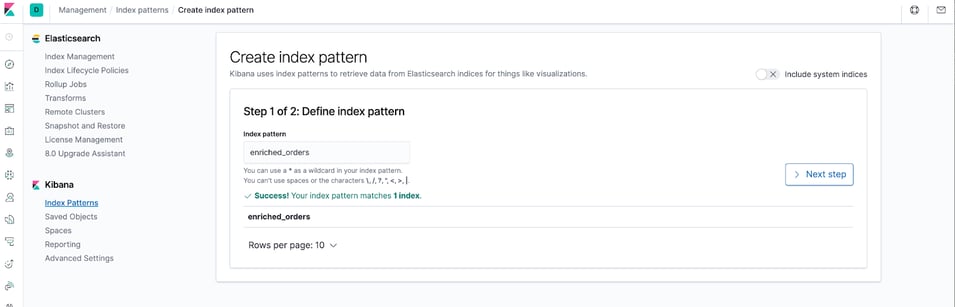
LEFT JOIN shipments AS s ON o.order_id = s.order_id;Visit Kibana on your local machine (http://localhost:5601/app/kibana#/management/kibana/index_pattern) to create an index pattern enriched_orders.
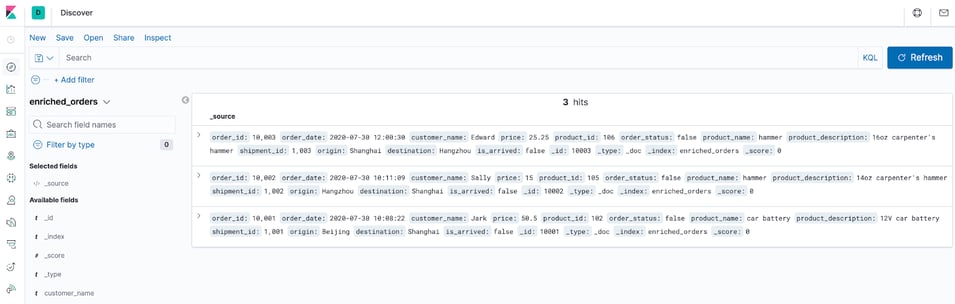
You can see the written data at http://localhost:5601/app/kibana#/discover.
Next, modify the data in the tables in the MySQL and Postgres databases and the orders data displayed in Kibana will also be updated in real time.
Insert a piece of data into a MySQL orders table
INSERT INTO orders
VALUES (default, '2020-07-30 15:22:00', 'Jark', 29.71, 104, false);Update the status of an order in the MySQL orders table
UPDATE orders SET order_status = true WHERE order_id = 10004;Insert a piece of data into the Postgres shipments table
INSERT INTO shipments
VALUES (default,10004,'Shanghai','Beijing',false);Update the status of a shipment in the Postgres shipments table
UPDATE shipments SET is_arrived = true WHERE shipment_id = 1004;Delete a piece of data in the MYSQL orders table.
DELETE FROM orders WHERE order_id = 10004;Refresh Kibana to see the updated data.
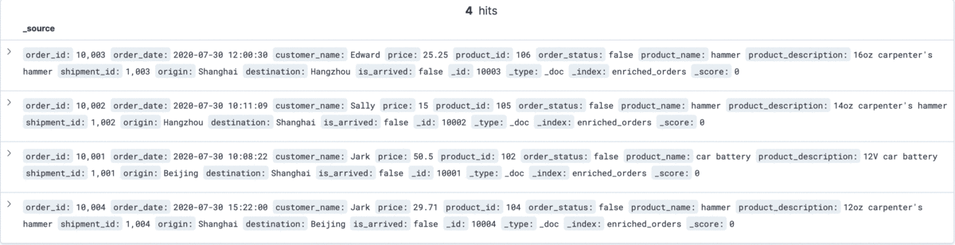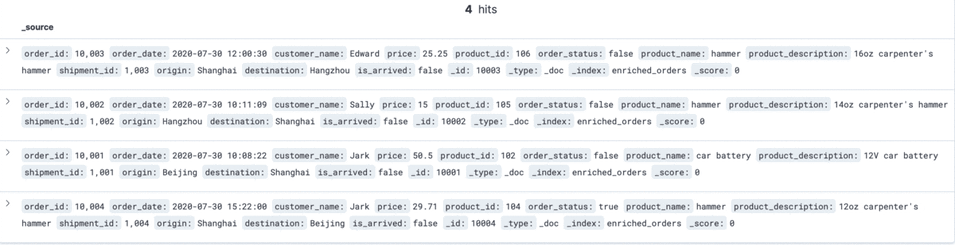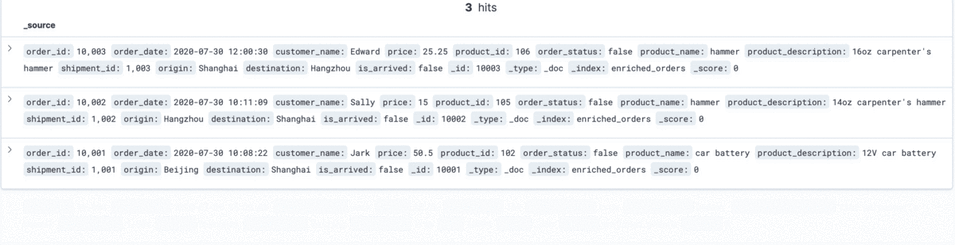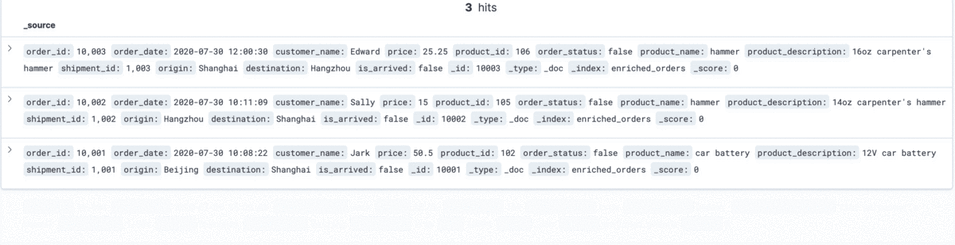
Step 9: Clean the environment
After performing all the steps, run the following command in <my-project> directory to stop all the containers.
docker-compose downChange directory to flink-1.16.0 and execute the following command to stop the Flink cluster.
./bin/stop-cluster.sh
You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
