














In this article, we describe the setup of Ververica Platform using Amazon Web Services Elastic Container Service for Kubernetes (AWS EKS). Ververica Platform is built on Kubernetes as the underlying resource manager. Kubernetes is available in all major cloud providers, on-premise and also on single machines.
A previous blog post describes the necessary steps for a successful deployment of Ververica Platform using Google Cloud’s Kubernetes Engine. We will soon be providing documentation about how to get started with the platform on Microsoft Azure, which also provides a hosted Kubernetes service called AKS (“Azure Kubernetes Service”). In the meantime, thedocumentation of Ververica Platform provides some initial guidance.

In the following sections, we take you through the process of setting up successfully Ververica Platform on AWS. The process consists of three main steps: Firstly, we guide you through the process of creating an Amazon EKS Cluster. Then, we discuss how to effectively launch Amazon EKS worker nodes and finally, we review the process to successfully grant access and install Ververica Platform to your Kubernetes environment.
Prerequisites
Before getting started, please make sure that you have the following resources installed in your machine:
-
Download the Ververica Platform Kubernetes trial.
-
Install the AWS CLI, Kubectl and Helm on your local machine.
Creating an Amazon EKS Cluster for your Ververica Platform deployment
1. Open the Amazon EKS console at https://console.aws.amazon.com/eks/home#/clusters.
2. Choose Create cluster.
If your IAM user does not have administrative privileges, you must explicitly add permissions for that user to call the Amazon EKS API operations. For more information, see Creating Amazon EKS IAM Policies.
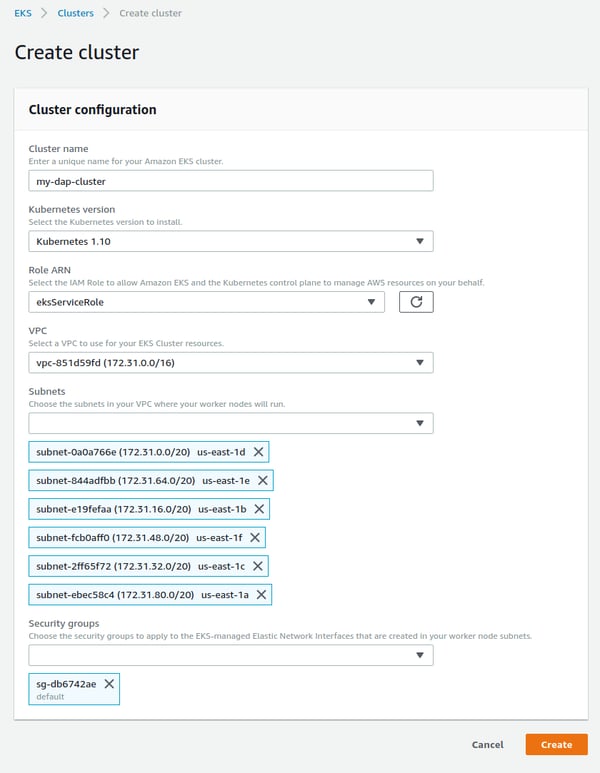
3. On the Create cluster page, fill in the following fields and then choose Create:
-
Cluster name: A unique name for your cluster.
-
Kubernetes version: The version of Kubernetes to use for your cluster. By default, the latest available version is selected.
-
Role ARN: The Amazon Resource Name (ARN) of your Amazon EKS service role. For more information, see Amazon EKS Service IAM Role
-
VPC: The VPC to use for your cluster.
-
Subnets: The subnets within the above VPC to use for your cluster. By default, the available subnets in the above VPC are preselected. Your subnets must meet the requirements for an Amazon EKS cluster. For more information, see Cluster VPC Considerations.
-
Security Groups: Specify one or more (up to a limit of 5) security groups within the above VPC to apply to the cross-account elastic network interfaces for your cluster. Your cluster and worker node security groups must meet the requirements for an Amazon EKS cluster. For more information, see Cluster Security Group Considerations.
The worker node AWS CloudFormation template modifies the security group that you specify here, so we recommend that you use a dedicated security group for your cluster control plane. If you share it with other resources, you may block or disrupt connections to those resources.You may receive an error that one of the Availability Zones in your request does not have sufficient capacity to create an Amazon EKS cluster. If this happens, the error output contains the Availability Zones that can support a new cluster. Retry creating your cluster with at least two subnets that are located in the supported Availability Zones for your account.
4. On the Clusters page, choose the name of your newly created cluster to view the cluster information. 5. The Status field shows CREATING until the cluster provisioning process completes. When your cluster provisioning is complete (usually less than 10 minutes), and note the API server endpoint and Certificate authority values. These are used in your kubectl configuration.
5. The Status field shows CREATING until the cluster provisioning process completes. When your cluster provisioning is complete (usually less than 10 minutes), and note the API server endpoint and Certificate authority values. These are used in your kubectl configuration.
6. Now that you have created your cluster, follow the procedures in Configure kubectl for Amazon EKS and Create a kubeconfig for Amazon EKS to enable communication with your new cluster.
To create your cluster with the AWS CLI
1. Create your cluster with the following command. Substitute your cluster name, the Amazon Resource Name (ARN) of your Amazon EKS service role that you created in Create your Amazon EKS Service Role and the subnet and security group IDs for the VPC you created in Create your Amazon EKS Cluster VPC. You must use IAM user credentials for this step, not root credentials. If you create your Amazon EKS cluster using root credentials, you cannot authenticate to the cluster. For more information, see How Users Sign In to Your Account in the IAM User Guide.
aws eks create-cluster --name devel --role-arn
arn:aws:iam::111122223333:role/eks-service-role-AWSServiceRoleForAmazonEKS-EXAMPLEBKZRQR
--resources-vpc-config subnetIds=subnet-a9189fe2,subnet-50432629,securityGroupIds=sg-f5c54184
If your IAM user does not have administrative privileges, you must explicitly add permissions for that user to call the Amazon EKS API operations. For more information, see Creating Amazon EKS IAM Policies.Output:
"cluster": {
"name": "devel",
"arn": "arn:aws:eks:us-west-2:111122223333:cluster/devel",
"createdAt": 1527785885.159,
"version": "1.10",
"roleArn": "arn:aws:iam::111122223333:role/eks-service-role-AWSServiceRoleForAmazonEKS-AFNL4H8HB71F",
"resourcesVpcConfig": {
"subnetIds": [
"subnet-a9189fe2",
"subnet-50432629"
],
"securityGroupIds": [
"sg-f5c54184"
],
"vpcId": "vpc-a54041dc"
},
"status": "CREATING",
"certificateAuthority": {}
}
2. Cluster provisioning usually takes less than 10 minutes. You can query the status of your cluster with the following command. When your cluster status is ACTIVE, you can proceed.
aws eks describe-cluster --name devel --query cluster.status
3. When your cluster provisioning is complete, retrieve the endpoint and certificateAuthority.data values with the following commands. These must be added to your kubectl configuration so that you can communicate with your cluster. Retrieve the endpoint:
aws eks describe-cluster --name devel --query cluster.endpointRetrieve the certificateAuthority.data:
aws eks describe-cluster --name devel
--query cluster.certificateAuthority.data
4. Now that you have created your cluster, follow the procedures in Configure kubectl for Amazon EKS and Create a kubeconfig for Amazon EKS to enable communication with your new cluster
Launching Amazon EKS Worker Nodes
Before launching your Amazon EKS Worker Nodes, please make sure that you have:
-
created a VPC and security group that meets the requirements for an Amazon EKS cluster.
-
created an Amazon EKS cluster and specified that it uses the above VPC and security group. For more information.
1. Open the AWS CloudFormation console at https://console.aws.amazon.com/cloudformation.
2. From the navigation bar, select a Region that supports Amazon EKS.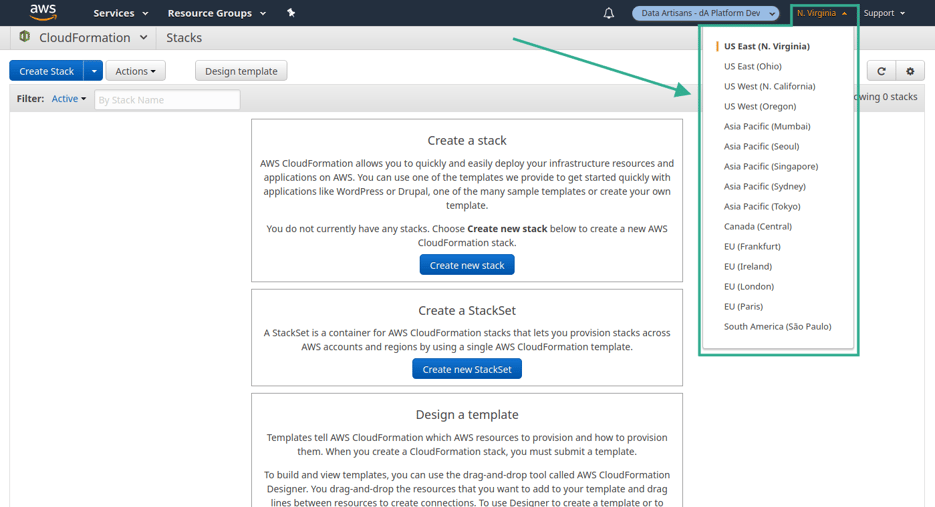 Amazon EKS is available in the following Regions at this time
Amazon EKS is available in the following Regions at this time
-
US West (Oregon) (us-west-2)
-
US East (N. Virginia) (us-east-1)
-
EU West (Ireland) (eu-west-1)
3. Choose Create stack.
4. For Choose a template, select Specify an Amazon S3 template URL.
5. Paste the following URL into the text area and choose Next:
https://amazon-eks.s3-us-west-2.amazonaws.com/1.10.3/2018-06-05/amazon-eks-nodegroup.yaml
6. On the Specify Details page, fill out the following parameters accordingly, and choose Next:
-
-
Stack name: Choose a stack name for your AWS CloudFormation stack. For example, you can call it <cluster-name>-worker-nodes.
-
ClusterName: Enter the name that you used when you created your Amazon EKS cluster.
-
-
ClusterControlPlaneSecurityGroup: Enter the security group or groups that you used when you created your Amazon EKS cluster. This AWS CloudFormation template creates a worker node security group that allows traffic to and from the cluster control plane security group specified.
-
NodeGroupName: Enter a name for your node group that is included in your Auto Scaling node group name.
-
NodeAutoScalingGroupMinSize: Enter the minimum number of nodes to which your worker node Auto Scaling group can scale in.
-
NodeAutoScalingGroupMaxSize: Enter the maximum number of nodes to which your worker node Auto Scaling group can scale out.
-
NodeInstanceType: Choose an instance type for your worker nodes.
-
NodeImageId: Enter the current Amazon EKS worker node AMI ID for your Region.
| Region | Amazon EKS-optimized AMI ID |
| US West (Oregon) (us-west-2) | ami-73a6e20b |
| US East (N. Virginia) (us-east-1) | ami-dea4d5a1 |
The Amazon EKS worker node AMI is based on Amazon Linux 2. You can track security or privacy events for Amazon Linux 2 at the Amazon Linux Security Center or subscribe to the associated RSS feed. Security and privacy events include an overview of the issue, what packages are affected, and how to update your instances to correct the issue.
-
-
KeyName: Enter the name of an Amazon EC2 SSH key pair that you can use to connect using SSH into your worker nodes with after they launch.
-
VpcId: Enter the ID for the VPC that your worker nodes should launch into.
-
Subnets: Choose the subnets within the above VPC that your worker nodes should launch into.
-
7. On the Options page, you can choose to tag your stack resources. Choose Next.
8. On the Review page, review your information, acknowledge that the stack might create IAM resources, and then choose Create.
9. When your stack has finished creating, select it in the console and choose Outputs.
10. Record the NodeInstanceRole for the node group that was created. You need this when you configure your Amazon EKS worker nodes.
To enable worker nodes to join your cluster
1. Download, edit, and apply the AWS authenticator configuration map.
-
-
Download the configuration map:
curl -O https://amazon-eks.s3-us-west-2.amazonaws.com/1.10.3/2018-06-05/aws-auth-cm.yaml -
Open the file with your favorite text editor. Replace the <ARN of instance role (not instance profile)> snippet with the NodeInstanceRole value that you recorded in the previous procedure, and save the file.
-
apiVersion: v1
kind: ConfigMap
metadata:
name: aws-auth
namespace: kube-system
data:
mapRoles: |
- rolearn: <ARN of instance role (not instance profile)>
username: system:node:
groups:
- system:bootstrappers
- system:nodes
- Apply the configuration. This command may take a few minutes to finish.
kubectl apply -f aws-auth-cm.yaml
If you receive the error "heptio-authenticator-aws": executable file not found in $PATH, then your kubectl is not configured for Amazon EKS. For more information, see Configure kubectl for Amazon EKS.
2. Watch the status of your nodes and wait for them to reach the Ready status.
kubectl get nodes --watchCreate default storage class
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
annotations:
storageclass.kubernetes.io/is-default-class: “true”
name: gp2
provisioner: kubernetes.io/aws-ebs
Parameters:
Type: gp2
reclaimPolicy: Delete
mountOptions:
- debugCreate tiller service account and role binding
$ kubectl --namespace kube-system create sa tiller
$ kubectl create clusterrolebinding tiller --clusterrole cluster-admin --serviceaccount=kube-system:tiller
$ helm init --service-account tillerCreate Ververica Platform namespace
$ kubectl create namespace daplatformGenerate chart values
$ ./bin/generate-chart-values --with-rbac > values.yamlInstall the Helm chart
$ helm install --name my-da-platform --values values.yaml daplatform-1.2.tgzAccess the Web UI
To access Application Manager, VervericaPlatform’s central orchestration and lifecycle management component, we’ll set up a port forward with kubectl.For a permanent, production setup, we recommend setting up an Ingress or something else suitable for the environment.Run the following commands for setting up the port forward:
$ POD_NAME=$(kubectl get pod -l release=my-da-platform,component=appmanager -o jsonpath='{.items[0].metadata.name}')<
$ kubectl port-forward $POD_NAME 8080Application Manager is now available on http://localhost:8080/.
Create your first Application Manager Deployment to launch a Flink job
For the first deployment, we’ll just submit a Flink example that is hosted on Maven Central.To create a new Deployment, open the Application Manager user interface, and click the “Create Deployment” button on the top right.Fill the form with the following values:
-
Name: Enter any name
-
Deployment Target: Kubernetes
-
Upgrade Strategy: Stateless
-
Initial State: Cancelled
-
Start from Savepoint: None
-
Parallelism: 1
-
Jar URI
-
For JobManager and TaskManager CPU: 1
Finally, press the “Create Deployment” button, select the newly created Deployment from the list, and press “Start” to launch a Flink cluster on Kubernetes for the job.In this example, we used a jar from Maven. For running your own jar files, you need to store the file in cloud storage accessible by the Application Manager (for example publicly on GitHub or in Google Cloud Storage Bucket). Alternatively, deploy Minio into the Kubernetes cluster. Minio is an S3-compatible object storage server.
Advanced: Set up access to AWS S3 for checkpoints and savepoints.
Ververica Platform unfolds its full capabilities when it’s able to use a central state store for Flink. In most cases, S3, HDFS or Google’s cloud storage act as such a central state store for our existing customers.
In the case of Amazon Web Services, Flink comes with built-in support for S3. All stateful life-cycle operations (such as suspending a deployment or executing a stateful upgrade) require savepoints to be configured. Below are the steps to successfully configure checkpoints and savepoints for AWS S3:
Provide an entry in the flinkConfiguration map with the key state.savepoints.dir:
flinkConfiguration:
state.savepoints.dir: s3://flink/savepoints
Provide additional credentials as part of the flinkConfiguration map in order to store Flink application state such as checkpoints or savepoints in AWS S3.
flinkConfiguration:
s3.access-key: yourAccessKey
s3.secret-key: yourSecretKey
The official Flink documentation on savepoints gives more details on how savepoints are configured.You can find out more details and information on the Ververica Platform documentation.
Next Steps
Download the Ververica Platform Trial for Kubernetes to benefit from 10 non-production CPU cores for 30 days. The Platform documentation will give you a detailed view of what’s possible with Application Manager to deploy, manage and debug your Apache Flink streaming applications.Do not hesitate to reach out to Ververica for feedback, questions or requests or for larger trial licenses.



You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
