














During Flink Forward Virtual 2020, GoDaddy demonstrated to the Flink community how our Data Platform Team uses Apache Flink for running real time streaming pipelines. In this post, I will describe our process for building a streaming data platform from the ground-up and discuss how our choice of Apache Flink helped us get up and running in record time.
Why build a streaming data platform
Before diving into the specifics of our approach to building a streaming data platform, I would like to briefly explain the main reason why an organization like us, with tens of product offerings, dealing with more than 19 million customers worldwide might need a streaming data platform in the first place. In our case, it was of the utmost importance to be able to identify opportunities and service our customers with the best set of products and services right at the moment when they engage with our website. Doing that with a data platform based on batch processing would historically mean that our customer care and business analytics teams would need to wait up to one day before such data becomes available to them. In order for us to best serve our customers, it was necessary for the Data Platform team at GoDaddy to build a streaming data platform delivering such valuable insights to our internal teams in a low latency manner.

We hence decided to build our data platform based on a Kappa architecture, that comes with a streaming-first principle in mind, while at the same time being flexible enough to allow running batch jobs if necessary. This is where Apache Flink came in as the best option for our streaming data platform, since it comes with a streaming-first approach to data processing of unbounded streams, handling any batch jobs as bounded streams of events.
Streaming Data Platform Architecture at GoDaddy
Let’s now describe our Streaming Data Platform architecture at GoDaddy. As illustrated in Figure 1 below, our infrastructure comprises of three main layers; on the left, we start with our data ingress layer that acts as the place where we gather all data before it enters our data platform. Making a purchase on GoDaddy, as an example, will add such data to a SQL Server database. With CDC (change data capture) enabled on tables, we built a process that streams data from CDC and writes it to Amazon Kinesis, a service to collect streaming data. Since the data is retained in Kinesis for seven days, we have enabled a persistent storage layer — accessed via firehose — with Amazon S3 in order to have the data available for future use or querying.
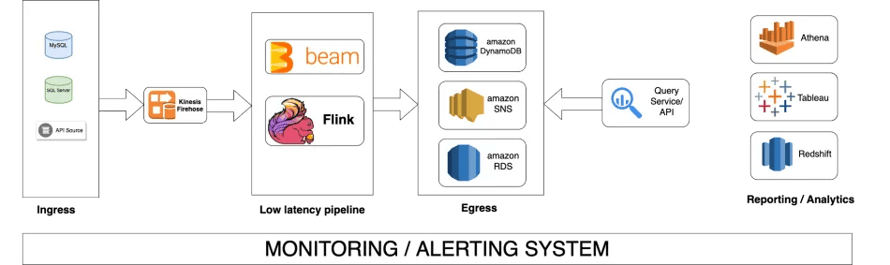 Figure 1: Streaming Data Platform at GoDaddy
Figure 1: Streaming Data Platform at GoDaddy
The second layer of our platform includes the stream processing engine responsible for handling the actual processing of events. With Apache Flink, there are multiple ways of writing your streaming pipelines: you can program either against Flink’s APIs directly or use an abstraction language like Apache Beam. In our case, we write our business logic in Beam (such as performing aggregations or data transformations) and then run our pipelines on Flink. This brings us the necessary set of abstractions that ensure an easy onboarding of new pipelines to our system, making it frictionless for pipeline authors to benefit from the platform itself as illustrated in Figure 2 below.
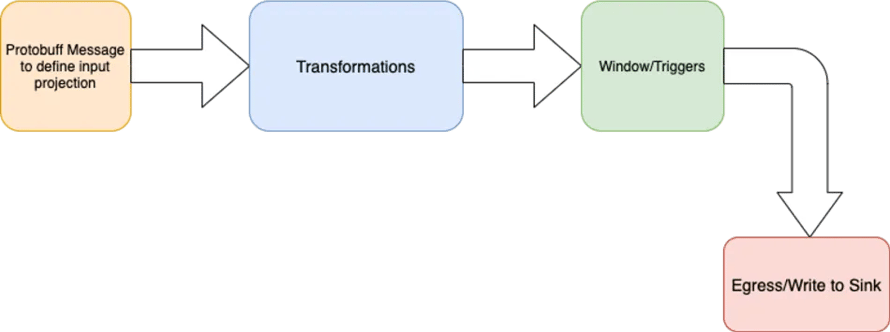 Figure 2: Set of abstractions in GoDaddy’s Streaming Data Platform
Figure 2: Set of abstractions in GoDaddy’s Streaming Data Platform
-
You firstly define your input sources through a Protobuf message
-
Once you know which input source you are consuming data from, you apply your transformation in Beam, something incredibly valuable since pipeline authors know what business logic to apply to this layer
-
Once the transformation is complete you then define your own time window (how long you want to accumulate the results) and trigger conditions for your pipelines
-
You finally send the events downstream to an egress service that is writing data to a sink, such as a database, file system, notification service or any other supported egress services.
The third layer of our infrastructure includes the data egress or the output of our data. This could be any relational database (this is Amazon RDS in our case) or any other notification service. For example, at GoDaddy, we write all the transformed events into Amazon SNS so that when a customer completes a purchase on the site, all such data is available to our marketing and customer care teams for triggering email notifications with the customer receipt or executing other forms of customer communication in a real time fashion.
The final elements of our data platform include a set of data analytics tools (shown at the far right of Figure 1 above) such as Amazon Athena, Tableau and Amazon Redshift for our marketing and data analytics teams. We have end-to-end monitoring on our entire stack that can easily help us figure out problems in a certain component.
Deployment Lifecycle of Streaming Pipelines at GoDaddy
We will now describe what a typical deployment lifecycle looks like when deploying a new pipeline in GoDaddy’s streaming data platform. When creating new pipelines, pipeline authors use Beam’s abstraction language and our own SDKs to write the pipeline. They then create an uber jar including the pipeline code and all its dependencies and dockerize it. We then spin up a Flink cluster on Kubernetes to deploy the pipeline. The number of task manager pods used by a pipeline varies depending on how much data a pipeline is ingress-ing and a few other factors. Pipeline authors then submit the uber jar to the Job Manager on a Kubernetes pod enabling incremental checkpoints using RocksDB as a state backend in Flink. We do have a security requirement to make sure our pods have the latest security patches. In order to be able to do node rotation — essentially patching our EKS cluster with security updates and then spin up new pods to run pipelines — we use Flink’s ability to take savepoints, allowing us to take a point-in-time snapshot of the pipeline and then restoring the pipeline reading data from that specific snapshot instead of processing all the data over and over again.
Releasing new pipelines to our streaming data platform follows a Blue/Green deployment approach on Kubernetes. This means that there is always a running cluster (Blue cluster) and for every new set of pipeline changes we spin up a new cluster (Green cluster). We have the Green cluster catch-up to the current events that we are processing, we then perform a cluster validation to ensure that everything is correct before finally performing a DNS switch to point to the new cluster. In case of an error, rolling back is pretty easy as you simply need to change the DNS to point to the old (Blue) cluster and continue from there with pretty much zero downtime.
Key Learnings
Some of the key learnings that we had while building our streaming data platform was first and foremost how important it is to ensure that the platform comes with the right set of abstractions. This is fundamental in securing that the platform itself has wider adoption in the organization. A second key point for us was being able to use Flink with RocksDB as the state back for running streaming pipelines at scale. Especially in our case, where we are joining events from tens to hundreds of different event streams at the same time, being able to have some persistent storage to store all the data is very important. Additionally, Flink provides a great stream processing choice for running platforms that need to work with both real time (streaming) and batch data sets because it provides a streaming-first with batch as a special case of streaming approach to processing data. Finally, using Beam on top of Flink allowed us to execute the same pipeline code both on our own clusters in Spark as well as running the streaming pipelines on Flink in Kubernetes in AWS.
If you are interested in finding out more about the use of Flink at GoDaddy, we encourage you to watch the recording of our session on the Flink Forward YouTube channel or even to go ahead and pre-register for the upcoming Flink Forward Global 2020 conference taking place in October 2020. For a behind-the-scenes view of our use of different technologies at GoDaddy, you can visit the GoDaddy Engineering blog or contact us for more information.




From Kappa Architecture to Streamhouse: Making the Lakehouse Real-Time

Fluss Is Now Open Source

Announcing Ververica Platform: Self-Managed 2.14
