














At Flink Forward Europe 2019, the Google team will be presenting a keynote about “Building and operating a serverless streaming runtime for Apache Beam in the Google Cloud”. This comes along with Google’s latest contribution to the Apache Flink™ community, a bridge to Kubernetes. Kubernetes is a platform that provides a set of standards that helps you run applications and ensure that they can handle varying traffic. Kubernetes can also help with day-two Apache Flink operations such as upgrading, monitoring, and logging. The Apache Flink™ Operator for Kubernetes provides a control plane in Kubernetes that makes it easy for you to jump directly into managing Flink clusters and jobs without having to build your own deployment architectures and integrations.
Open Data Analytics on Google Cloud Platform
Open source has always been a core pillar of Google Cloud’s data and analytics strategy. Starting with the map reduce paper in 2004, to more recent open source releases of Tensorflow for ML, Apache Beam for data processing and even Kubernetes itself, Google has built communities around its technology in the open source and across company boundaries.
To accompany these popular open source technologies, Google Cloud Platform offers managed versions of the most popular open source software applications. For example, Cloud Dataproc is a fully managed Apache Hadoop and Apache Spark platform, and Cloud Dataflow provides a fully-managed environment for Apache Beam. Recently, the Cloud Dataproc team has taken a hard look at the OSS big data ecosystem to identify the challenges that are faced today. When talking to customers about how they run Flink on Cloud Dataproc, customers expressed pain points that included:
-
Management can be difficult and often requires skills like YARN expertise
-
Clusters can have a complicated OSS software stack that makes version and dependency management hard.
-
Isolation is tricky. To optimize performance, you have to think about jobs and cluster IaaS as one entity.
Looking at these three challenges, it was clear that Kubernetes was well positioned to address them. With Kubernetes, you can have a unified management layer for resources, more isolation of OSS jobs and a resilient infrastructure.
Multiple K8s Options
The challenge is that many of these OSS data analytics components were not originally designed with Kuberentes in mind. For Google Cloud Dataproc to provide customers the best possible managed service, the Google team first needed to make enhancements to the existing open source functionality.
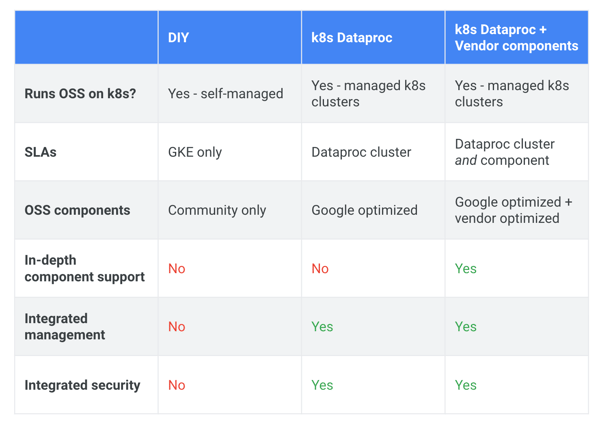
The result was setting forth a strategy that offered multiple layers of K8s options.
-
DIY: A fully open source option that provides a K8s control plane and application APIs based on Google’s experience running data systems at scale.
-
k8s Dataproc: A fully managed version of the open source via the Google Cloud Dataproc service.
-
k8s Dataproc + Vendor components: The ability for Google’s partners to extend the Cloud Dataproc managed service with their own customizations but without having to worry about the underlying cloud infrastructure integration and management.
The first step towards this strategy was the release of the open source Spark on K8s Operator which was quickly followed up with a managed Dataproc option.
Next Up: Flink on K8s Operator
Before jumping into Beam specifics, let’s first take a step back and explain the method Google (and many others) are using to deploy k8s management tools in the open source. i.e. the DIY method.
To run a complex application on Kubernetes, we usually end up with creating an application control plane which abstracts the low-level details of Kubernetes and provides a simple domain-specific API / language for the user. Operators are a method of packaging, deploying and managing those Kubernetes applications. The operator provides a set of cohesive APIs to extend in order to service and manage the applications that run on Kubernetes.
An architecture for the Google Cloud Flink on K8s Operator looks like this:
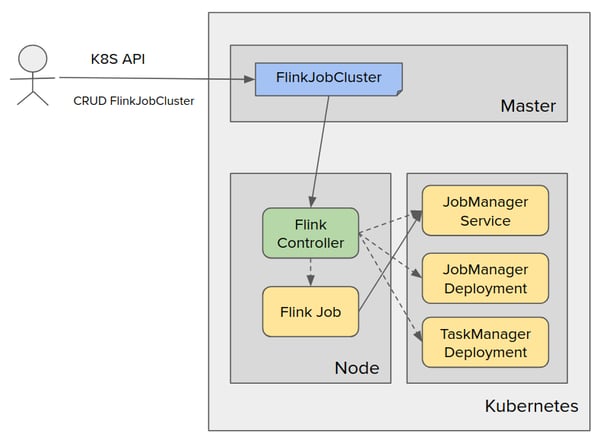
With the operator installed in a cluster, you can obtain the fully configured deployment depicted above. This lets you easily communicate with the cluster through the Kubernetes API and Flink custom resources, making it possible to start managing Flink clusters and jobs without having to learn the inner workings of Kubernetes or manage infrastructure.
The full source code and additional details about this operator can be found at Apache Flink™ Operator for Kubernetes.
Beam on Flink Runner
Apache Beam is an open source, unified model for defining both batch and streaming data-parallel processing pipelines. Using one of the open source Beam SDKs, you build a program that defines the pipeline. The pipeline is then executed by one of Beam’s supported distributed processing back-ends, which includes Apache Flink.
Apache Beam backed by Beam’s Flink runner is a great option if you want to use Python for your pipeline development. For example, if you have machine learning libraries written in Python, you can use the Beam-on-Flink runner to build pipelines using these libraries.
This combination has been gaining traction at data savvy companies such as Lyft, who is using this setup to do dynamic pricing of rides and Yelp, who is using it for a real-time indexing pipeline.
Getting Started
We hope that the possible combination of Beam, Kubernetes and Flink which is now available in the open source excites you to explore the possibilities of what can be done with this merger.
You can get started today by following the developer guide for The Apache Flink™ Operator for Kubernetes. We look forward to your feedback and pull requests.
About the author:

Christopher Crosbie has been building and deploying data and analytics applications for the past 15+ years and is currently a Product Manager at Google, focused on building data lake tools for the Google Cloud platform.
Chris came to Google from Amazon where he held two different positions. The first was a solutions architect for AWS, where he was awarded the 2015 solutions architect of the year distinction. The second and more recent position was as a Data Engineering Manager for an R&D group known as "Grand Challenges". Previous to joining Amazon, he headed up the data science team at Memorial Sloan Kettering Cancer Center where he managed a team of statisticians and software developers. He started his career as a software engineer at the NSABP, a not-for-profit clinical trials cooperative group supported by the National Cancer Institute. He holds an MPH in Biostatistics and an MS in Information Science.
"Apache", "Apache Flink", and their logos are registered trademarks or trademarks of The Apache Software Foundation in the U.S. and/or other countries.

You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
