














Introduction
Alice is a data engineer taking care of real-time data processing in her company. She found that Flink SQL sometimes can produce update (with regard to keys) events. But, with the early versions of Flink, those events can not be written to Kafka directly because Kafka is an append-only messaging system essentially. Fortunately, the Flink community released the connector upsert-kafka in a later version that supports writing update events. Later, she found that the Flink SQL jobs that read upsert-kafka events for join operations occasionally produce errors. This made her doubt the reliability of Flink SQL. She reported the problem to the community and it was confirmed to be a changelog event out-of-orderness issue, which was subsequently resolved in the new version. Finally, she can continue to work with Flink SQL happily again.
From Alice's experience with Flink SQL, we can learn that real-time data processing is not always smooth and straightforward. To make Flink SQL more understandable, this article tries to solve the mystery around the changelog event out-of-orderness issue in Flink SQL. We will start with the introduction of changelog in Flink SQL, followed by the demonstration of the changelog event out-of-orderness issue and the solution to it. In the end, we will present the best practices with regard to this issue to help you better understand and use Flink SQL for real-time data processing.
Changelog in Flink SQL
Changelog is not a new concept invented by Flink SQL. In the relational database world, MySQL uses the well-known binlog (binary log) to record all modification operations in the database, including INSERT, UPDATE, and DELETE operations. Similarly, changelog in Flink SQL is also used to record these data changes in order to achieve incremental data processing.
In MySQL, binlog can be used for data backup and recovery, synchronization, and replication. Incremental data synchronization and replication can be achieved by reading and parsing the operation records in binlog. Change Data Capture (CDC) is a commonly used data synchronization technology that monitors data changes in the database and converts those changes into event streams for real-time processing. CDC tools can be used to transfer data changes in relational databases to other systems or data warehouses in real-time to support real-time analysis and reporting. Common CDC tools include Debezium and Maxwell. Flink’s CDC support, added via FLINK-15331, allows integration with external systems' CDC data in real-time and achieves real-time data synchronization and analysis through Flink.
Produce and Process Changelog Events in Flink SQL
While the aforementioned binlog and CDC are external changelog data sources that are integrated with Flink, Flink SQL internally also generates changelog data. To distinguish whether an event is an update event, we refer to the changelogs that contain only INSERT-type events as append streams, while the changelogs that additionally contain other types (e.g., UPDATE) of events are referred to as update streams. Some operations in Flink such as group aggregation and deduplication can produce update events. Operators that generate update events typically maintain state, and we generally refer to them as stateful operators. It is important to note that not all stateful operators support processing update streams as input. For example, over-window aggregation and interval join currently do not support update streams as input (yet).
Here is a table showing Flink SQL operations, the corresponding runtime streaming operators, and whether they support consuming or producing update streams, as of Flink 1.16.1:
|
SQL Operation |
Runtime Operator |
Use State |
Support consuming update streams |
Produce update streams |
Comment |
|
SELECT & WHERE |
Calc |
N |
Y |
N |
Stateless operator, pass-through input event type |
|
Lookup Join |
LookupJoin |
*N |
Y |
N |
Stateless operator(except under try_resolve mode for NDU problem), pass-through input event type |
|
Table Function |
Correlate |
N |
Y |
N |
Stateless operator, pass-through input event type |
|
SELECT DISTINCT |
GroupAggregate |
Y |
Y |
Y |
|
|
Group Aggregation |
GroupAggregate LocalGroupAggregate GlobalGroupAggregate IncrementalGroupAggregate |
*Y |
Y |
Y |
except LocalGroupAggregate |
|
Over Aggregation |
OverAggregate |
Y |
N |
N |
|
|
Window Aggregation |
GroupWindowAggregate WindowAggregate LocalWindowAggregate GlobalWindowAggregate |
*Y [1] |
*Y[2] |
*N [3] |
[1] except LocalWindowAggregate [2] the legacy GroupWindowAggregate support consuming update, but the new Window TVF Aggregation doesn’t support [3] when enable early/late firing |
|
Regular Join |
Join |
Y |
Y |
Y |
|
|
Interval Join |
IntervalJoin |
Y |
N |
N |
|
|
Temporal Join |
TemporalJoin |
Y |
Y |
N |
|
|
Window Join |
WindowJoin |
Y |
N |
N |
|
|
Top-N |
Rank |
Y |
Y |
Y |
|
|
Window Top-N |
WindowRank |
Y |
N |
N |
|
|
Deduplication |
Deduplicate |
Y |
N |
*Y |
first row with proctime will not generate updates |
|
Window Deduplication |
WindowDeduplicate |
Y |
N |
N |
Note: Stateless operators only pass through event types and do not actively generate update events, that is, the output event type remains the same as the input one.
Flink SQL Changelog's Event Types
Flink SQL introduced the retraction mechanism via FLINK-6047. It implemented the incremental update algorithm for streaming SQL operators. The corresponding events use two physical types: INSERT and DELETE (although the data source only supports INSERT events). When an event needs to be updated after processing by the operator, the update event is physically split into two independent events DELETE and INSERT. From then on, Flink has always been using two physical event types to express the three operation requirements of INSERT, UPDATE, and DELETE. Since FLINK-16987, the changelog event type was refactored into four types which form a complete changelog event type that eases the connection to the CDC ecosystem.
/**
* A kind of row in a changelog.
*/
@PublicEvolving
public enum RowKind {
/**
* Insertion operation.
*/
INSERT,
/**
* Previous content of an updated row.
*/
UPDATE_BEFORE,
/**
* New content of an updated row.
*/
UPDATE_AFTER,
/**
* Deletion operation.
*/
DELETE
}Users who are familiar with Debezium data format (or the database binlog parsing) may wonder why Flink does not use a composite UPDATE event type (like what databases do) that includes both UPDATE_BEFORE (UB) and UPDATE_AFTER (UA) and is more compact. In fact, we have carefully evaluated this option when designing and implementing Flink's retraction mechanism. Composite UPDATE events are indeed more compact in some scenarios and can solve specific problems (e.g., FLINK-9528), but the reasons we choose not to use it are mainly due to the following two aspects:
- The split events have the same event structures regardless of event types (only RowKind is different) which makes serialization simpler. If composite UPDATE events are used, either the events are heterogeneous or INSERT/DELETE are also modeled as UPDATE events (e.g., INSERT events have only UA, DELETE events have UB only)
- In distributed environments, data shuffling operations (e.g., join, aggregate) are frequently involved. Even if composite UPDATE events are used, they still have to be split into separate DELETE and INSERT events when shuffling in some scenarios.
Here's an example showing a scenario where composite UPDATE events have to be split into DELETE and INSERT events. The remainder of this blog post will use this example SQL job to discuss the out-of-orderness issue and present the corresponding solution.
-- CDC source tables: s1 & s2
s1: id BIGINT, level BIGINT, PRIMARY KEY(id)
s2: id BIGINT, attr VARCHAR, PRIMARY KEY(id)
-- sink table: t1
t1: id BIGINT, level BIGINT, attr VARCHAR, PRIMARY KEY(id)
-- join s1 and s2 and insert the result into t1
INSERT INTO t1
SELECT
s1.*, s2.attr
FROM s1 JOIN s2
ON s1.level = s2.idAssuming the changelog of the record with id=1 in the source table s1 is at time t0, '(id=1, level=10)' is inserted, and then at time t1, the row is updated to '(id=1, level=20)'. This corresponds to three split events:
+I (id=1, level=10) // +I: INSERT
-U (id=1, level=10) // -U: UPDATE_BEFORE
+U (id=1, level=20) // +U: UPDATE_AFTER
Looking at the SQL statement in the example, the primary key of the source table s1 is id, but the join operation needs to be shuffled by column level (see the ON clause).
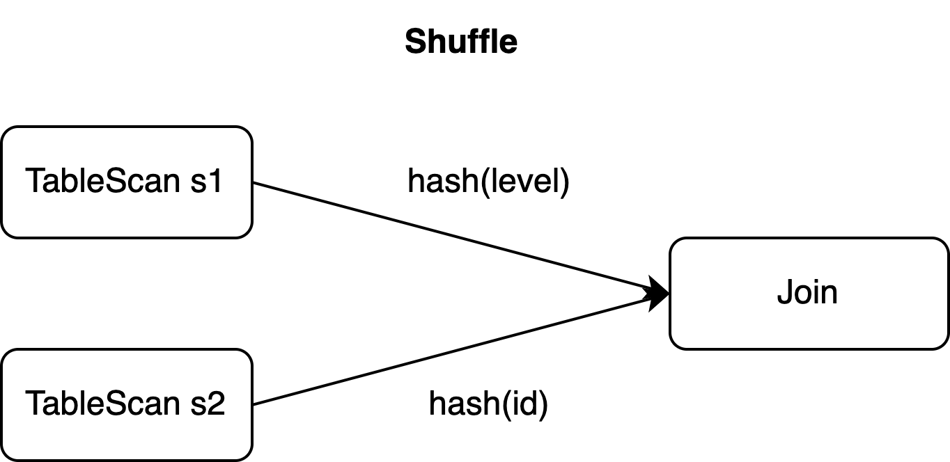
In this example, if the join operator runs with a parallelism of two, the above three events could be sent to two tasks. In this case, even if composite UPDATE events are used, they still need to be split in order to be shuffled to different tasks for parallel processing.
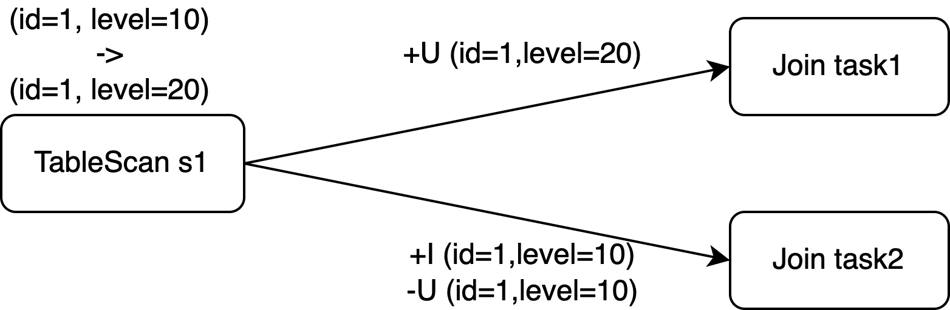
The Changelog Event Out-of-Orderness Issue
How the Issue Occurs
Continuing with the previous example, suppose there are two rows in table s2:
+I(id=10, attr=a1)
+I(id=20, attr=b1)
The join operator receives the following three changelog events from table s1:
+I(id=1, level=10)
-U(id=1, level=10)
+U(id=1, level=20)
In a distributed environment, the actual join is processed in parallel on two tasks. See the figure below. The sequence of the events received by the downstream operator (Sink task in this case) has a few possibilities as indicated at the bottom of the figure. While the sequence of events in (1) is the same as the one in sequential processing, (2) and (3) show the scenarios where the changelog event arrives out-of-order at the Sink operator in Flink SQL.
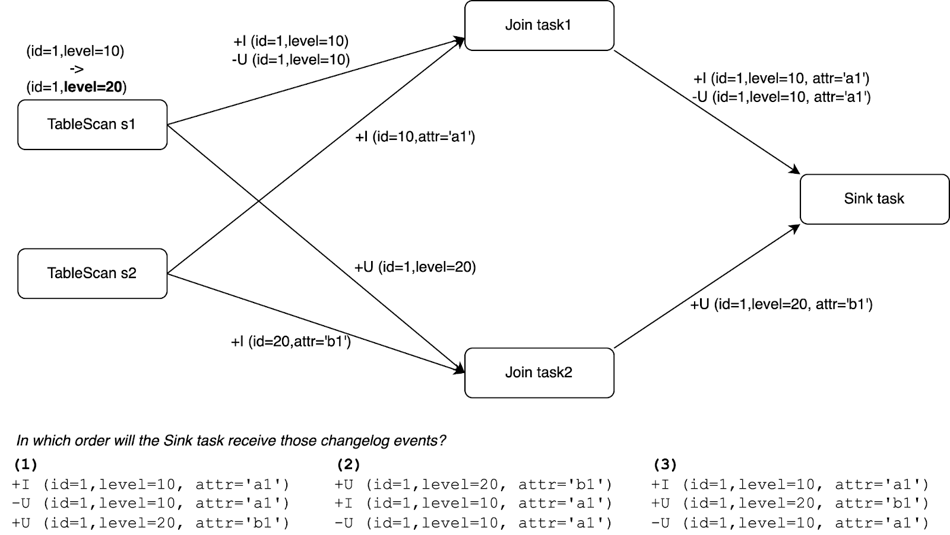
If the downstream operator does not take the out-of-ordermess into account in its implementation, it may lead to incorrect results. For example, if the primary key declared by the Sink table is id, and the external storage is updated by upsert. In scenarios (2) and (3), without additional countermeasures, the row with id=1 will be deleted from the external storage incorrectly while the expected result is '(id=1, level=20, attr='b1')'.
Fix the Issue with SinkUpsertMaterializer
The join operator in the aforementioned example SQL job produces an update stream because its output contains not only INSERT-style events (+I), but also UPDATE-style events (-U and +U). As mentioned before, out-of-orderness can cause a correctness issue if it is not handled properly.
Before presenting the solution, we will briefly introduce two terms first. Unique keys denote the column or the combination of columns guaranteed to meet the UNIQUE constraint after an SQL operation. In the SQL world, unique keys help to determine whether to update an existing row or insert a new row when a row comes. For example, the following three sets of keys are all unique keys of the joining output in the example SQL job:
(s1.id)
(s1.id, s1.level)
(s1.id, s2.id)
In the traditional relational database world, binlog (or something similar) maintained a sequential and ordered update history for a primary key of a table. Flink SQL's changelog mechanism is based on the same idea but has a simplified implementation. Flink does not record the timestamp of each update like binlog. Instead, Flink determines the ordering of update history received on the primary key through a global analysis in the planner. If the ordering on some unique keys is maintained, the corresponding keys are called upsert keys. In the presence of upsert keys, downstream operators can correctly tell the update history of the upsert keys in the order of reception. If a shuffle operation breaks the ordering of unique keys, upsert keys will be empty. In this case, downstream operators need to use an algorithm such as a counting algorithm to achieve the final consistency.
In the example SQL job, the rows in table s1 are shuffled based on column level, and the join operator will produce multiple rows with the same s1.id. As a result, the upsert key of the join output is empty (meaning no ordering exists on a unique key after joining). What Flink does, in this case, is to store all input records, then check and compare all columns to distinguish between update and insertion.
Furthermore, the sink table has column id as its primary key. This leads to a mismatch between the upsert keys of the join output and the primary key of the sink table. It is clear that something has to be done here to correctly convert the rows from the join output to the rows needed by the sink table.
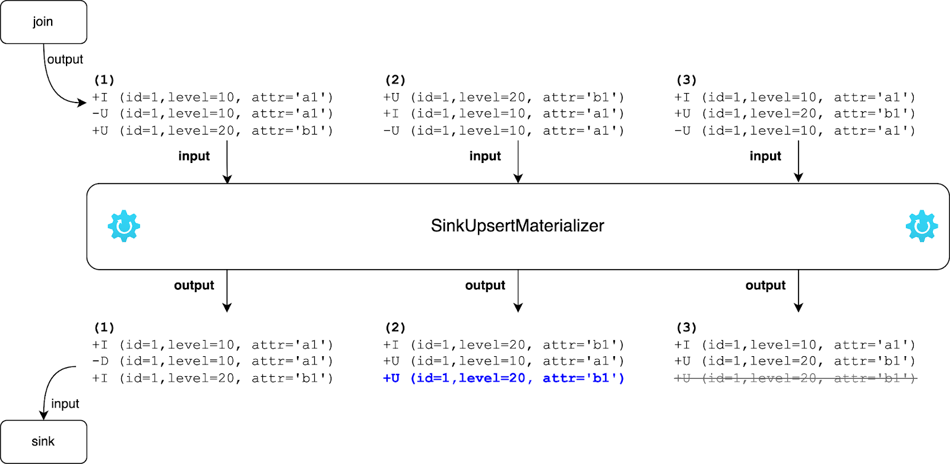
Based on what we discussed so far when the output of the join operator (or another SQL operation) is an update stream and its upsert key is different from the primary key of the sink table, an intermediate step is needed to (1) eliminate the effect caused by out-of-orderness, and (2) produce new output changelog events based on the primary key of the sink table. Flink’s answer to this is adding the operator SinkUpsertMaterializer between the join operator and the sink operator (FLINK-20374). Looking at the changelog events illustrated in the figure before, we can see that the out-of-orderness of the changelog events follows this rule: for a given upsert key (or all columns if the upsert key is empty), the ADD events (+I, +U) always occur before its RETRACT events (-D, -U) and they are always processed by the same task even if a data shuffle is involved. This also explains why there are no other combinations of those three changelog events except for three cases as illustrated before. SinkUpsertMaterializer was implemented based on this rule and works as follows:
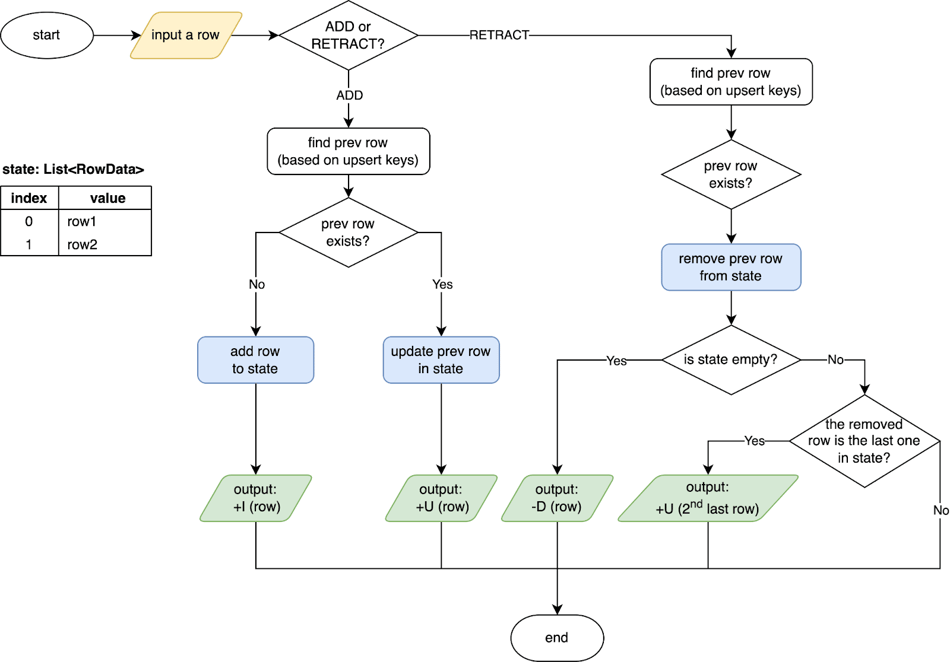
SinkUpsertMaterializer maintains a list of RowData in its state. When a row enters this operator, depending on whether it is an ADD or RETRACT event, it checks its internal state for this row based on the deduced upsert keys or the entire row if the upsert key is empty (the step “find prev row”), then it adds/updates the row in the state in case of ADD or removes it from the state in case of RETRACT. Finally, it emits the changelog events based on the primary key of the sink table. See the source code of SinkUpsertMaterializer for more details.
The figure below shows how the output changelog events from the join operator are processed and transformed into the input changelog events to the sink table. Particularly, in the second scenario, when the row removed from the state is the last row, it emits the 2nd last row downstream. In the third scenario, when +U (id=1,level=20, attr='b1') is processed, SinkUpsertMaterializer emits it as it is. When -U (id=1,level=10, attr='a1') comes, it removes the row from the state without emitting any event as the required output has already been omitted before.
Best Practices
As shown in the previous section, SinkUpsertMaterializer maintains a list of RowData in its state. Potentially, this can lead to a large state size thereof the state access I/O overhead and the reduced job throughput. Therefore, we should try to avoid using it if possible.
Proactively Avoid Using SinkUpsertMaterializer
The addition of SinkUpsertMaterializer is controlled by the configuration option table.exec.sink.upsert-materialize which has a default value of “auto”. This means, by default, Flink’s SQL engine deduces the existence of out-of-orderness from the correctness perspective and adds SinkUpsertMaterializer if necessary. Note that the automatic addition of SinkUpsertMaterializer does not necessarily mean that the actual data are out-of-order. For example, in some user queries, when the SQL planner deduces the upsert keys, there may not be targeted optimization, such as using the grouping sets syntax combined with coalesce to convert null values. In this case, the planner cannot determine whether the upsert key generated by grouping sets combined with coalesce can match the primary key of the sink table. For the reasons of correctness, Flink will add SinkUpsertMaterializer. But if a job can produce the correct output without using SinkUpsertMaterializer, then it is better to run the job with table.exec.sink.upsert-materialize: non to force Flink not to add SinkUpsertMaterializer.
Other ways to avoid using SinkUpsertMaterializer include:
- Make sure the partition key used for deduplication, group aggregation, etc. is the same as the sink table's primary key.
- If the sink operator and the upstream deduplication/group aggregation/other operators are chained together and there is no data correctness issue in Flink 1.13.2 or earlier, you can refer to the original resource configuration and change
table.exec.sink.upsert-materializetononeto migrate the job to Flink 1.13.3 or later.
If SinkUpsertMaterializer has to be added:
- Avoid adding columns generated by non-deterministic functions (such as CURRENT_TIMESTAMP or NOW) to the data written to the sink, as this can cause abnormal inflation in the state of SinkUpsertMaterializer in Flink 1.14 or earlier.
- Try to increase the job parallelism if the state of SinkUpsertMaterializer is already large and causes performance issues.
Known Issues of SinkUpsertMaterializer
While SinkUpsertMaterializer fixes the changelog event out-of-orderness issue, it can potentially lead to a continuous state increase. This is mainly due to two factors:
- The state retention time is too long (no state TTL or a very long one is set). Note that Enabling TTL can impact data integrity. A short TTL can lead to the problem described in FLINK-29225 where dirty data that should have been deleted remain in the state. This occurs when the time interval between the DELETE event of a message and its ADD event exceeds the configured TTL. In this case, Flink produces a warning message in the logs:
int index = findremoveFirst(values, row); if (index == -1) { LOG.info(STATE_CLEARED_WARN_MSG); return; } - Flink may not deduce the upsert keys correctly before Flink 1.16 in some scenarios. For example, when there are non-deterministic columns in the input update stream, it will not be able to correctly delete historical data (that is, “prev row exists” always return “False” in the flow chart). This results in a continuous state increase. This has been fixed by FLINK-28569 in Flink 1.16 or later.
Summary
This article provided answers to several changelog-related questions that Flink SQL users frequently encounter in real-time data processing:
- What is a changelog stream? How does it relate to the binlog in the relational database?
- How does changelog event out-of-orderness occur?
- How does Flink SQL solve the out-of-orderness issue?
- What are the best practices to deal with the changelog event out-of-orderness issue?
Acknowledgments
Thanks to community users for their feedback on the related issues and to Jingsong Lee for his contribution to fixing the out-of-orderness issues in Flink and numerous sessions of offline discussions.

You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
