














Time is a critical element in stream processing since data is processed as it arrives and must be processed quickly to avoid delays. The ubiquity of time in stream processing means that data processing must be designed to take into account the time factor. Time-based windowing is a common technique used in stream processing to ensure that data is processed in a timely manner.
Stream processing can be used for a variety of applications, such as monitoring systems, fraud detection, and any application that wants to provide real-time insights. The ubiquity of time in stream processing presents challenges and opportunities for data processing. With the right design, stream processing can be used to provide real-time insights into data streams.
In this post, we will take a look at how time can be taken into account when using Flink SQL.
Timestamps and Queries
In stream processing, timestamps are used to record when an event occurred. This information can be used to determine how long it took for an event to be processed, or to monitor the performance of a stream processing system. Timestamps can also be used to order events that happened at the same time.
Examples:
- User interactions: clicks, (mobile) apps
- Logs: applications, machines
- Transactions: credit cards, ad serving
- Sensors: mobile phones, cars, IoT
Queries involving time in stream processing are typically used to analyze data over a period of time. This could involve finding trends or patterns in the data, or comparing data from different time periods. Stream processing systems typically provide ways to window the data, so that only data from a certain time period is considered. This makes it possible to perform real-time analysis of data as it comes in, or to perform analysis on historical data.
Examples:
- Average over the last minute
- Join with most recent exchange rate
- Alert after 3 unsuccessful attempts within 5 minutes
Time Attributes
There are a few different types of time attributes in stream processing. These are event time, processing time, and ingestion time. Event time is the timestamp of when an event happened. Processing time is the timestamp of when the event was processed. Ingestion time is the timestamp of when the event was ingested into the system.
Event time is the only time attribute that is completely under the control of the user. All other time attributes are controlled by the system. Event time allows the user to control when an event happens, which can be very important in some situations.
Processing time can be affected by the speed of the system. In some cases, the system might be slow and processing time might be delayed. In other cases, the system might be fast and processing time might be earlier than expected.
Ingestion time is completely out of the control of the user. Ingestion time is controlled by the system and is dependent on the speed of the system.
Event time attributes
An event time attribute is a TIMESTAMP or a TIMESTAMP_LTZ with an associated watermark. The watermarking uses a bounded-out-of-orderness watermarking strategy
A TIMESTAMP is a data type that records a date and time down to the fractional seconds, while a TIMESTAMP_LTZ (Local Time Zone) is a data type that stores the date, time, and local time zone of the client. Visit the official Flink documentation website to learn more.
CREATE TABLE clicks (
user STRING,
url STRING,
cTime TIMESTAMP_LTZ(3),
WATERMARK FOR cTime AS cTime - INTERVAL '2' MINUTE
)Processing time attributes
A processing time attribute is a computed column and does not hold data; the local machine time is queried whenever the attribute is accessed. A processing time attribute can be used like a regular TIMESTAMP_LTZ
CREATE TABLE clicks (
user STRING,
url STRING,
cTime AS PROCTIME()
)As time moves forward, state can be expired, for example, counting clicks per user in hour-long windows.
Event time windows
- clicks are counted toward the hour in which they occurred
- watermarks trigger closing windows and discarding their state
Processing time windows
- clicks are counted toward the current hour as they are processed
- the local system clock triggers closing windows and discarding their state
Without a time attribute in the input table, the window operator wouldn't know when windows are complete.
Timestamps vs. time attributes
There are two common ways to represent time in stream processing: timestamps and time attributes. A timestamp is a point in time that is associated with an event, while while time attributes can be present in each table schema. Timestamps are more precise, but time attributes are more flexible and can be used to represent complex temporal relationships.
The values in a timestamp column are fixed to specific moments in time with no guarantee that the column is (even roughly) ordered by time.
A time attribute column is connected to the forward progress of time:
- a processing time attribute is connected to the system clock via PROCTIME()
- an event time attribute is connected to the watermarks
Temporal Operators
In stream processing, temporal attributes are often used to identify patterns and trends over time. For example, if a stream of data contains a series of values that increase or decrease over time, a temporal attribute could be used to identify this trend. Similarly, if a stream of data contains a series of values that fluctuate over time, a temporal attribute could be used to identify the period of time during which the fluctuations occur.
Temporal attributes can be used to identify patterns and trends not only in the data itself, but also in the relationships between different data streams. For example, if two streams of data are correlated, a temporal attribute could be used to identify the time lag between the two streams.
The use of temporal attributes in stream processing can be a powerful tool for identifying patterns and trends that would otherwise be difficult to detect.
Temporal operators use time attributes to associate records with each other and are a way of handling time-based data in stream processing. There are a few different types of temporal operators:
Windows:
- GROUP BY windows
- OVER windows
- window table-valued functions (since Flink 1.13)
Joins:
- interval JOIN
- JOIN with a temporal table (versioned joins)
Pattern matching (CEP with MATCH_RECOGNIZE)
Temporal operators track progress in time to decide when input is complete. They emit final result rows that can not be updated and are able to discard state (records and results) that is no longer needed.
Window examples
GROUP BY window aggregation
Below, you will find a query to count clicks per hour and users with TUMBLE and TUMBLE_END as built-in window functions. These window functions are using cTime, our table's time attribute.
SELECT
user,
TUMBLE_END(cTime, INTERVAL '1' HOUR) AS endT,
COUNT(url) AS cnt
FROM clicks
GROUP BY
TUMBLE(cTime, INTERVAL '1' HOUR),
userTypes of GROUP BY windows
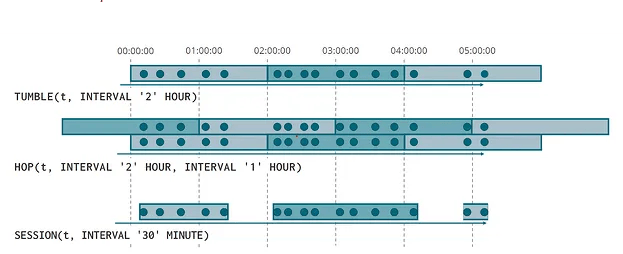
Tumbling: In tumbling windows, the windows are non-overlapping and of a fixed size. For example, if we have a stream of data and we want to calculate the average value of the data points in that stream over the last five minutes, we would use a tumbling window of size five minutes.
Hopping: In hopping windows, the windows are overlapping and of a invariable size. For example, if we have a stream of data and we want to calculate the average value of the data points in that stream over the last five minutes, but we want that calculation to be updated every minute, we would use a hopping window of size five minutes with a one-minute hop.
Session: In session windows, the windows are based on the activity of the data stream. A session window opens with an input and automatically extends if a subsequent input is received within the ensuing gap time. When there is a static gap duration and no input is received within the specified time following the latest input, the session window shuts.
Selecting window boundaries
|
These functions return TIMESTAMPs |
These functions return time attributes |
|
|
|
|
|
These timestamps are useful in reports, but can't be used as inputs to other temporal operators because they are not time attributes. |
These time attributes can be used wherever a time attribute is needed, e.g., GROUP BY windows, OVER windows, window table-valued functions, interval, and temporal joins. |
Window table-valued functions
A conceptual example
SELECT * FROM TABLE(
TUMBLE(TABLE clicks, DESCRIPTOR(cTime), INTERVAL '1' HOUR));|
user |
cTime |
url |
window_start |
window_end |
window_time |
|
Mary |
12:00:00 |
./home |
12:00:00.000 |
13:00:00.000 |
12:59:59.999 |
|
Bob |
12:00:00 |
./cart |
12:00:00.000 |
13:00:00.000 |
12:59:59.999 |
|
Mary |
12:02:00 |
./prod?id=2 |
12:00:00.000 |
13:00:00.000 |
12:59:59.999 |
|
Mary |
12:55:00 |
./home |
12:00:00.000 |
13:00:00.000 |
12:59:59.999 |
SELECT
user, window_start, window_end, count(url) AS cnt
FROM TABLE(
TUMBLE(TABLE clicks, DESCRIPTOR(cTime), INTERVAL '1' HOUR))
GROUP BY
user, window_start, window_end;|
user |
window_start |
window_end |
cnt |
|
Mary |
12:00:00.000 |
13:00:00.000 |
3 |
The window table-valued functions (WTVF) are a special class of functions that return a table. Below, you can see some examples:
- TUMBLE(TABLE data, DESCRIPTOR(timecol), size)
- HOP(TABLE data, DESCRIPTOR(timecol), slide, size [, offset ])
- CUMULATE(TABLE data, DESCRIPTOR(timecol), step, size)
- Session windows are not yet supported (FLINK-24024)
If we compare window TVFs to GROUP BY windows, window TVFs are better optimized as they use mini-batch aggregation and two phase (local-global) aggregation. Window TVFs support grouping by GROUPING SETS, ROLLUP, and CUBE. Also, you can apply Window Top-N to the results, e.g. find the top 3 users with the most clicks every hour.
Conclusion
In summary, streaming applications often have a requirement to process events in a specific order based on the time they occurred. Time attributes, such as event time and processing time, are essential for making SQL viable in this context and are defined in the table schema. Temporal operations, which rely on these time attributes to associate related input rows, allow for the real-time analysis and processing of data. The results of these operations are final and emitted rows are never updated. The state of these operations is managed automatically, simplifying the development process. Overall, time attributes and temporal operations are crucial for working with streaming data in SQL.
Check out part 2 of this article series, where we provide a more in-depth look at how to create different time windows.
Follow us on Twitter to get updates on our next articles and/or to leave us feedback. :)

You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
