














This is a guest post written by Mohamed Amine Abdessemed from Bouygues Telecom
About Bouygues Telecom
 Bouygues Telecom is a full-service communication operator (mobile, fixed telephony, TV, Internet, and Cloud computing) and one of the largest providers in France, with over 11 million mobile subscribers and 2.5 million fixed customers, generating a revenue of 5.43 billion euros (2014). At Bouygues Telecom we stand for our innovative products, services and award-winning customer relations: We are pioneers in Ultra High Speed Mobile with over 72% of the population covered in 4G/4G+, we offer the first TV box running Android and more. Our team is in charge of providing systems and applications to our telecom engineers in order to create, develop, and maintain our network; to provide the best services for our customers. We came to know Apache Flink™ during a Hadoop User Group meetup in Paris. Since then, we have been using Flink internally for a variety of use cases with very good results.
Bouygues Telecom is a full-service communication operator (mobile, fixed telephony, TV, Internet, and Cloud computing) and one of the largest providers in France, with over 11 million mobile subscribers and 2.5 million fixed customers, generating a revenue of 5.43 billion euros (2014). At Bouygues Telecom we stand for our innovative products, services and award-winning customer relations: We are pioneers in Ultra High Speed Mobile with over 72% of the population covered in 4G/4G+, we offer the first TV box running Android and more. Our team is in charge of providing systems and applications to our telecom engineers in order to create, develop, and maintain our network; to provide the best services for our customers. We came to know Apache Flink™ during a Hadoop User Group meetup in Paris. Since then, we have been using Flink internally for a variety of use cases with very good results.
LUX: Logged User Experience
But first, a bit of context: At Bouygues, our customers experience is a top priority, that’s why we’ve invested in using Big Data solutions to provide a new network-oriented vision of our Data and give our engineers real-time insight about:
- The customer's experience on our network.
- Global & detailed picture on what’s happening on the network.
- The network evolutions and operations.
The goal of the LUX (Logged User Experience) system is to produce Quality of Experience indicators using massive log data from network equipment and joining this data with internal reference data, e.g., equipment’s referential, error codes, manufacturers, current operations, interventions, etc. The system should be able to be used for real-time diagnostics and alarming with latency less than 60 seconds, and it should generate automated Business Intelligence reporting functionality pushed to upstream users. Internally, LUX consists of four major components:
- The Planck system is responsible for data collection, and is implemented using Apache Camel.
- The Vortex system, responsible for gathering all collected data in a central bus, and is implemented using Apache Kafka.
- The Candela system is responsible for providing real-time diagnostics to upstream users, and is based on Elasticsearch.
- Finally, the Lumen system is responsible for data transformation, alarming, reporting and analytics, and is implemented using several components of Cloudera’s Hadoop distribution (in particular Apache Flume, Apache Spark, Apache Hive, Apache Oozie), as well as Apache Flink™, the focus of this post.
Real-time data integration
LinkedIn pioneered a design pattern for using Kafka as a central component to collect streams to solve its data integration problem. The idea is to collect all the organization’s data and put it into a central log for real-time data subscription. We have tried to put this design pattern to work at Bouygues as well. Early on, we ran into the following problem: lots of data comes in a raw format, even in binary encoding with no visible business logic information. This renders this data virtually unusable. We explored three possible solutions to this problem:
- Each data source processes its own data before pushing it into Kafka. We rejected this solution as not viable for our case. Data sources have really limited computation resources assigned to log collection, so they need to push the data in raw format.
- Each Kafka consumer decodes the raw data. This is problematic, as every consumer implements the same business logic wasting resources and makes code deployment and maintenance too hard to achieve.
- Inject an intermediate processing pipeline that processes the raw data in Kafka and feeds the data back to Kafka in decoded and enriched format. This seemed like the best solution for our case. However, this processing pipeline needs to be very fast in order to respect our SLAs.
In order to implement the third solution, we have been looking for a data processing framework that is (1) fast, (2) reliable, and (3) scalable. In particular, fast for us meant the ability to deliver results with low latency and keep the data moving in real time. Flink proved to be the best match for these requirements. Our data ingestion and transformation pipeline implemented with Kafka and Flink now looks as follows:
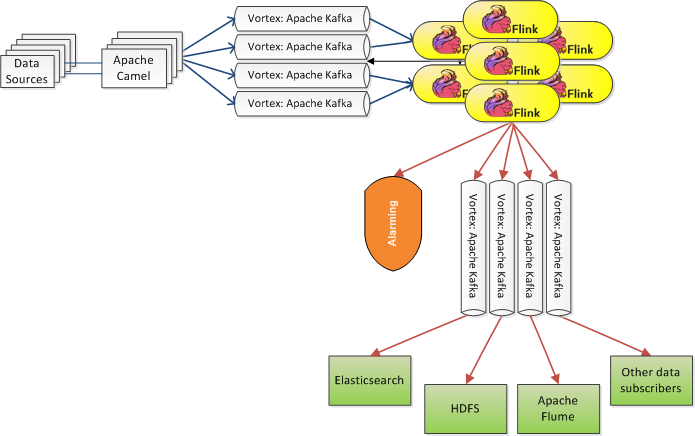
Apache Camel collects raw log data from the sources and forwards it to Kafka with an average rate of 20K event per second (and up to 40K events per second in busy hours). Then, a Flink data transformation streaming topology with exactly-once guarantees that uses Flink’s persistent Kafka source is transforming the raw data into a usable and enriched form on the fly and pushing it back to Kafka. Upstream systems (such as Elasticsearch) consume the transformed data that have been fed back to Kafka. Additionally, Flink is used to implement our alarming functionality, consuming directly the data from the previous Flink topology. There, a sliding window is used to create counters and push them to a specialized metric system to keep track of failure occurrences over time, and forwards alarms to an alarming system if a certain threshold of failures is detected.
Why Flink?
Currently, we are employing a data transformation pipeline (from and to Kafka) in pre-production, as well as the alarming functionality in testing. After evaluating streaming frameworks, we ended up with Flink because the system supports true streaming - both at the API and at the runtime level, giving us the programmability and low latency that we were looking for. In addition, we were able to get our system up and running with Flink in a fraction of the time compared to other solutions, which resulted in more available developer resources for expanding the business logic in the system. Other strong points of the framework was the good support for debugging (e.g., seamless switch to local execution, program visualization), and APIs that were attractive to both our developers and data scientists. Over time, we saw other teams at Bouygues picking up Flink for different use cases, including batch data analysis. To summarize, Bouygues now happily Flinks, and we are looking forward to continue working together with the Flink community, and expand the range of our Flink applications. And or course, we are looking forward to the upcoming Flink Forward.

You may also like

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica

Maximize Efficiency: How Ververica's BYOC Deployment Optimizes CAPEX and OPEX
