














We are delighted to see that the Apache Flink™ community has announced the availability of Apache Flink™ 0.10. The 0.10 release is one of the largest Flink releases ever, with about 80 individuals resolving more than 400 JIRA issues.
While these numbers are impressive on their own, in Flink 0.10, the whole is truly greater than the sum of its parts. The combination of new features advances Flink to be a data stream processor that truly stands out in the open source space and that significantly eases the effort to bring streaming jobs into production. While the official release announcement provides an extensive list of new features, this blog post focuses on those features that jointly improve the experience of developing and operating stream processing applications.
New DataStream API
Flink 0.10 features a completely revised DataStream API, which is now graduated from beta to fully supported. As organizations are transitioning their infrastructure from batch-based to streaming-based architectures, developers need a programming API that is as easy to use as batch processing APIs, and at the same time powerful enough to control the two main tenets of stream processing, namely time and state. Today, the majority of open source stream processing frameworks provide lower-level APIs that shift a lot of responsibility of dealing with time and state to the application developer.
The new DataStream API is straightforward to use for developers who are familiar with modern batch processing tools. At the same time, it offers powerful primitives to deal with time and state. Let us look at a simple example application that processes a stream of sensor events representing the number of vehicles that pass through a location:
case class Event(location: Location, numVehicles: Long, timestamp: Long)
val stream: DataStream[Event] = env
.addSource(new FlinkKafkaConsumer082("topic", new EventSchema(), properties))
Simple record-by-record transformations can be performed with the same code as in batch programs, e.g., extracting events that belong to an intersection:
val filteredStream = stream.filter { evt => isIntersection(evt.location) }
To count the number of vehicles that pass through each intersection, we need to (1) organize the data stream by event location (the intersections) and (2) define finite sections on the infinite data stream over which the counts can be computed.
Such a finite section is called a window and can for example be defined as a period of time. In the following example, we count all cars that passed during the last 15 minutes, emitting a count every 5 minutes (this is called a sliding window):
val counts = filteredStream
.keyBy("location")
.timeWindow(Time.minutes(15), Time.minutes(5))
.sum("numVehicles")
For something more powerful, assume that we want to receive early alerts when the traffic is heavy (e.g., when more than 200 vehicles passed through an intersection). We can define a custom trigger, that emits early counts without waiting for 5 minutes:
val countsWithTrafficAlert = filteredStream
.keyBy("location")
.timeWindow(Time.minutes(15), Time.minutes(5))
.trigger(new Threshold(200))
.sum("numVehicles")
Finally, we might want to continuously train a model for each intersection to predict future traffic situations. Flink provides the necessary tools to define and update partitioned operator state, which in our use case could be a dedicated model for each intersection. Flink will automatically back up the operator state while processing the streaming job and consistently restore the state in case of a failure. With Flink 0.10, we can partition the data stream by location and apply a stateful map function that updates the models and forwards a 60 minute traffic prediction:
val predictions = filteredStream
.keyBy("location")
.mapWithState { (evt, state: Option[Model]) => {
val model = state.orElse(new Model())
(model.predict(evt, 60), Some(model.update(evt)))
}}
To summarize, the new DataStream API of Flink has a smooth learning curve for programmers familiar with batch processing tools, but also provides powerful tools to control time and state, the two main principles of stream processing. For a detailed overview, check out the documentation of the new DataStream API.
Out-of-order streams and event time
Time is a fundamental concept in data streams. Many data streaming applications such as our traffic example above ingest events with associated timestamps and group and process these events by time. The way that stream processors interpret and handle time inevitably defines the semantics of such data streaming applications. In fact, many data streaming applications suffer from ill-defined semantics due to inappropriate handling of time in stream processors.
Flink 0.10 offers three different kinds of time semantics: processing time, ingestion time, and event time. With processing time semantics, events are processed with respect to the time at which they arrive at an operator. In the previous example, a processing-time operator would collect traffic events for 15 minutes and compute the sum of vehicle observations every five minutes based on the wall clock time of the machine that executes the operator.
At first sight, processing time looks OK. However, it is important to understand that in practice it is almost never guaranteed that events arrive in order of their associated timestamps. This is especially true in distributed systems and whenever events are collected from several sources such as sensor networks or mobile devices. Systems that ignore the fact that events arrive out-of-order and only offer processing time semantics will very likely produce incorrect and inconsistent results when being applied to out-of-order streams because events which should be processed together are easily separated. Out-of-order stream processing is increasingly important for many emerging use cases, such as Internet of Things applications where data comes from geo-distributed sensors.
Until now, application developers were forced to either ignore the reality of out-of-order events (accepting incorrect and inconsistent results) or to implement functionality for handling out-of-order streams in the application code. Flink 0.10 brings system support for event time, i.e., Flink processes events based on their associated timestamps, rather than the time they arrive at the system or operator. The third option, ingestion time, offers an intermediate solution with more accuracy than processing time for applications that process streams with no associated timestamp information. In this mode, Flink assigns timestamps to elements as their arrive at its sources, i.e., when they enter the stream processor, and treats these elements from there on exactly as in event time processing.
Of course not all applications require the precision of event time processing. Therefore, developers can switch between processing time, ingestion time, and event time in Flink by changing a few lines of code. By default, Flink processes streams with processing time which can also be explicitly specified as
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(ProcessingTime)
val stream = env.addSource (...)
val counts = stream
.keyBy("location")
.timeWindow(Time.minutes(15), Time.minutes(5))
.sum("numVehicles")
This will group events based on the time measured by the clock in each individual operator instance. While this is very fast, it is not very accurate. To get more accurate results, we can switch to ingestion time, grouping events by the time they arrive at the Flink data sources by changing one line of code:
env.setStreamTimeCharacteristic(IngestionTime)
Finally, we can switch to event time, grouping events by their own timestamps, which reflects the time they actually happened in the real world. For that, we need to additionally extract the timestamps from the records:
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(EventTime)
val stream = env.addSource (...)
val counts = stream
.extractAscendingTimestamp (evt => evt.timestamp)
.keyBy("location")
.timeWindow(Time.minutes(15), Time.minutes(5))
.sum("numVehicles")
Event time processing in Flink, as well as the windowing mechanisms including triggers and evictors, are highly inspired by the Dataflow Model, also implemented by Google Cloud Dataflow. Together with Google, we are working to extend the existing open source Dataflow Flink runner to streaming, and continue to collaborate and innovate on stream programming models. Learn more about working with time in Flink 0.10.
High availability and improvements to fault tolerance
Data streaming applications tend to run for very long periods of time. A strict requirement for any system that is designed for such workloads is the resilience with respect to failures. It is crucial that streaming applications do not terminate if a process dies or a random machine goes down.
Flink 0.10 introduces a high availability mode for cluster and YARN setups that eliminates all single points of failure of Apache Flink™. The HA mode relies on Apache Zookeeper for leader (JobManager) election and to persist metadata of running programs, such as state backend pointers to the data flow and completed checkpoints.
In addition, Flink 0.10 brings improvements to Flink’s state checkpointing mechanism and Flink’s exactly-once Kafka consumer.
Online metrics and improved monitoring
Flink 0.10 comes with a completely reworked monitoring dashboard. The dashboard significantly improves the experience of tracking the progress of running jobs, analyzing the performance of completed jobs, as well as monitoring the system as a whole. Real-time updated counters for the data volume and the number of records consumed and produced by each operator help to monitor the execution of batch and streaming programs. For completed jobs, the dashboard visualizes the processing time of each operator and any exceptions that occurred during processing. The following screenshot shows the job details of the DataSet API Triangle Enumeration example program.
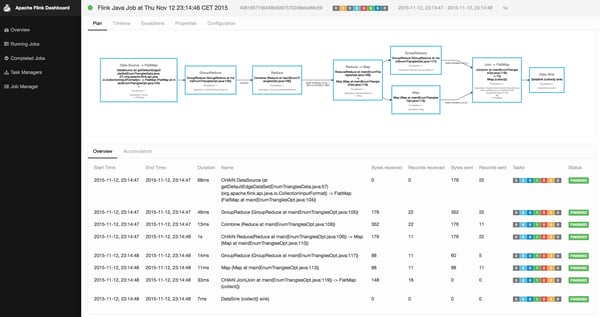
In addition to detailed job information, the web dashboard shows memory and JVM statistics for TaskManagers. This can help to monitor memory consumption and garbage collection overhead of Flink’s worker processes. In the future, the monitoring capabilities of the dashboard will be extended to provide even more details about the system and job executions.
Additional connectors
Flink 0.10 also comes with a bunch of new and updated connectors to get data streams in and out of the system. These connectors include an HDFS rolling file sink with exactly-once delivery guarantees. Even in presence of process or machine failures, the rolling file sink consistently and reliably writes a data stream as a sequence of files to a filesystem, such as HDFS or S3. Furthermore, Flink 0.10 includes a data sink for Elasticsearch, a data source for Apache Nifi, and improved Kafka consumers and producers.
What’s next?
The new features brought by Flink 0.10 are both operational (e.g., high availability and improved monitoring), as well as functional (event time, out-of-order streams, new DataStream API). From these, event time semantics is unique in the open source world, and also crucial to achieve meaningful and consistent results when processing out of order streams. Overall, we believe that Flink is a truly outstanding solution in the open source for real-time stream processing, as well as a system that is ready for large-scale production use.
If you are looking for a stream processing solution, you can download Apache Flink™ 0.10 and check out the documentation. Feedback through the Flink mailing lists is, as always, very welcome. We are looking forward to working together with the community for the next Flink releases!

You may also like

Maximize Efficiency: How Ververica's BYOC Deployment Optimizes CAPEX and OPEX

Zero Trust Security with Ververica's Bring Your Own Cloud Deployment. Part Two: Practical Security Improvements

Zero Trust Security with Ververica's Bring Your Own Cloud Deployment. Part One: the road to Zero Trust
