














This post is an adaptation of Piotr Nowojski’s presentation from Flink Forward Berlin 2017. You can find the slides and a recording of the presentation on the Flink Forward Berlin website.
Apache Flink 1.4.0, released in December 2017, introduced a significant milestone for stream processing with Flink: a new feature called `TwoPhaseCommitSinkFunction` (relevant Jira here) that extracts the common logic of the two-phase commit protocol and makes it possible to build end-to-end exactly-once applications with Flink and a selection of data sources and sinks, including Apache Kafka versions 0.11 and beyond. It provides a layer of abstraction and requires a user to implement only a handful of methods to achieve end-to-end exactly-once semantics.
If that’s all you need to hear, let us point you to the relevant place in the Flink documentation, where you can read about how to put TwoPhaseCommitSinkFunction to use. Or you can go straight to the docs for the Kafka 0.11 producer with exactly-once semantics, which is implemented on top of the `TwoPhaseCommitSinkFunction` as well.
But if you’d like to learn more, in this post, we’ll share an in-depth overview of the new feature and what's happening behind the scenes in Flink.
Throughout the rest of this post, we’ll:
-
Describe the role of Flink’s checkpoints for guaranteeing exactly-once results within a Flink application
-
Show how Flink interacts with data sources and data sinks via the two-phase commit protocol to deliver end-to-end exactly-once guarantees
-
Walk through a simple example on how to use TwoPhaseCommitSinkFunction to implement an exactly-once file sink
Exactly-once Semantics Within an Apache Flink Application
When we say “exactly-once semantics,” what we mean is that each incoming event affects the final results exactly once. Even in case of a machine or software failure, there’s no duplicate data and no data that goes unprocessed.
Flink has long provided exactly-once semantics within a Flink application. Over the past few years, we’ve written in depth about Flink’s checkpointing, which is at the core of Flink’s ability to provide exactly-once semantics. The Flink documentation also provides a thorough overview of the feature.
Before we continue, here’s a quick summary of the checkpointing algorithm because understanding checkpoints is necessary for understanding this broader topic.
A checkpoint in Flink is a consistent snapshot of:
-
The current state of an application
-
The position in an input stream
Flink generates checkpoints on a regular, configurable interval and then writes the checkpoint to a persistent storage system, such as S3 or HDFS. Writing the checkpoint data to the persistent storage happens asynchronously, which means that a Flink application continues to process data during the checkpointing process.
In the event of a machine or software failure and upon restart, a Flink application resumes processing from the most recent successfully-completed checkpoint; Flink restores application state and rolls back to the correct position in the input stream from a checkpoint before processing starts again. This means that Flink computes results as though the failure never occurred.
Before Flink 1.4.0, exactly-once semantics were limited to the scope of a Flink application only and did not extend to most of the external systems to which Flink sends data after processing. But Flink applications operate in conjunction with a wide range of data sinks, and developers should be able to maintain exactly-once semantics beyond the context of one component.
To provide end-to-end exactly-once semantics--that is, semantics that also apply to the external systems that Flink writes to in addition to the Flink application--these external systems must provide a means to commit or roll back writes that coordinate with Flink's checkpoints.
One common approach for coordinating commits and rollbacks in a distributed system is the two-phase commit protocol. In the next section, we’ll go behind the scenes and discuss how Flink’s `TwoPhaseCommitSinkFunction` utilizes the two-phase commit protocol to provide end-to-end exactly-once semantics.
End-to-end Exactly Once Applications with Apache Flink
We’ll walk through the two-phase commit protocol and how it enables end-to-end exactly-once semantics in a sample Flink application that reads from and writes to Kafka. Kafka is a popular messaging system to use along with Flink, and Kafka recently added support for transactions with its 0.11 release. This means that Flink now has the necessary mechanism to provide end-to-end exactly-once semantics in applications when receiving data from and writing data to Kafka.
Flink’s support for end-to-end exactly-once semantics is not limited to Kafka and you can use it with any source / sink that provides the necessary coordination mechanism. For example, Pravega, an open-source streaming storage system from Dell/EMC, also supports end-to-end exactly-once semantics with Flink via the `TwoPhaseCommitSinkFunction`.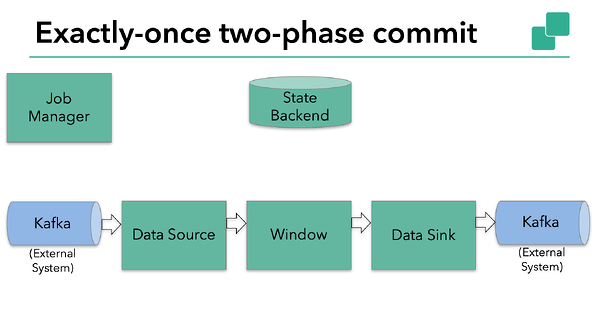
In the sample Flink application that we’ll discuss today, we have:
-
A data source that reads from Kafka (in Flink, a KafkaConsumer)
-
A windowed aggregation
-
A data sink that writes data back to Kafka (in Flink, a KafkaProducer)
For the data sink to provide exactly-once guarantees, it must write all data to Kafka within the scope of a transaction. A commit bundles all writes between two checkpoints. This ensures that writes are rolled back in case of a failure.
However, in a distributed system with multiple, concurrently-running sink tasks, a simple commit or rollback is not sufficient, because all of the components must “agree” together on committing or rolling back to ensure a consistent result. Flink uses the two-phase commit protocol and its pre-commit phase to address this challenge.
The starting of a checkpoint represents the “pre-commit” phase of our two-phase commit protocol. When a checkpoint starts, the Flink JobManager injects a checkpoint barrier (which separates the records in the data stream into the set that goes into the current checkpoint vs. the set that goes into the next checkpoint) into the data stream.
The barrier is passed from operator to operator. For every operator, it triggers the operator’s state backend to take a snapshot of its state. 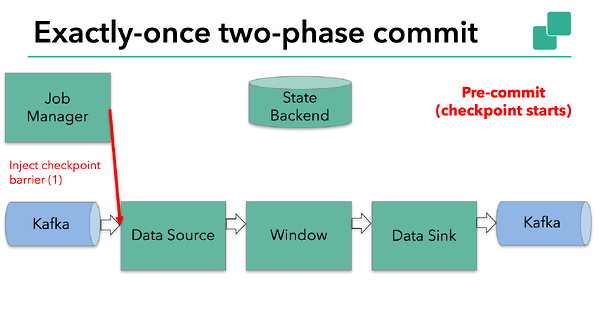 The data source stores its Kafka offsets, and after completing this, it passes the checkpoint barrier to the next operator.
The data source stores its Kafka offsets, and after completing this, it passes the checkpoint barrier to the next operator.
This approach works if an operator has internal state only. Internal state is everything that can be stored and managed by Flink’s state - for example, the windowed sums in the second operator. When a process has only internal state, there is no need to perform any additional action during pre-commit aside from writing to defined state variables. Flink takes care of correctly committing those writes in case of checkpoint success or aborting them in case of failure. 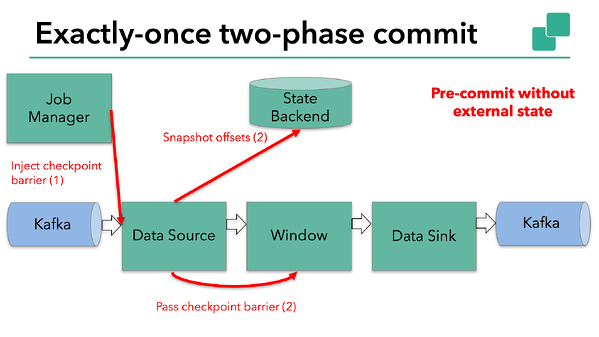 However, when a process has external state, this state must be handled a bit differently. External state usually comes in the form of writes to an external system such as Kafka. In that case, to provide exactly-once guarantees, the external system must provide support for transactions that integrates with a two-phase commit protocol.
However, when a process has external state, this state must be handled a bit differently. External state usually comes in the form of writes to an external system such as Kafka. In that case, to provide exactly-once guarantees, the external system must provide support for transactions that integrates with a two-phase commit protocol.
We know that the data sink in our example has such external state because it’s writing data to Kafka. In this case, in the pre-commit phase, the data sink must pre-commit its external transaction in addition to writing its state to the state backend.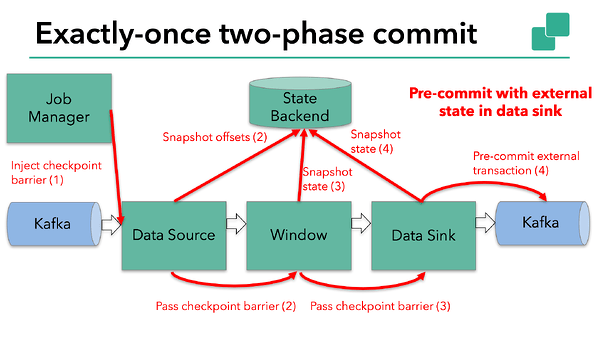 The pre-commit phase finishes when the checkpoint barrier passes through all of the operators and the triggered snapshot callbacks complete successfully. All of the triggered state snapshots are considered part of that checkpoint. The checkpoint is a snapshot of the state of the entire application, including pre-committed external state. In case of a failure, we can roll back to the point of time of the last successfully-completed snapshot.
The pre-commit phase finishes when the checkpoint barrier passes through all of the operators and the triggered snapshot callbacks complete successfully. All of the triggered state snapshots are considered part of that checkpoint. The checkpoint is a snapshot of the state of the entire application, including pre-committed external state. In case of a failure, we can roll back to the point of time of the last successfully-completed snapshot.
The next step is to notify all operators that the checkpoint has succeeded. This is the commit phase of the two-phase commit protocol and the JobManager issues checkpoint-completed callbacks for every operator in the application.
The data source and window operator have no external state, and so in the commit phase, these operators don’t have to take any action. The data sink does have external state, though, and it’s at this point that the external transaction should be committed: 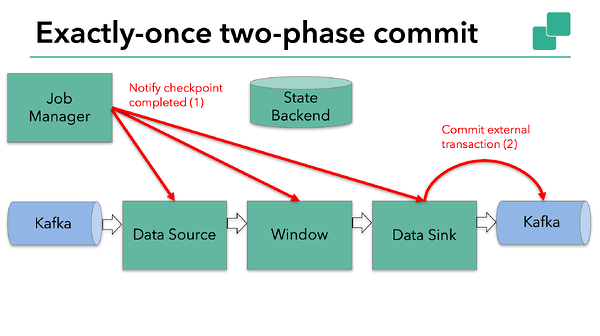 So let’s put all of these different pieces together:
So let’s put all of these different pieces together:
-
Once all of the operators complete their pre-commit, they issue a commit .
-
If at least one pre-commit fails, all others are aborted, and we roll back to the previous successfully-completed checkpoint.
-
After a successful pre-commit, the commit must be guaranteed to eventually succeed -- both our operators and our external system need to make this guarantee. If a commit fails (for example, due to an intermittent network issue), the entire Flink application fails, the application restarts according to the user’s restart strategy, and there is another commit attempt. This process is critical because if the commit does not eventually succeed, data loss occurs.
Therefore, we can be sure that all operators agree on the final outcome of the checkpoint: all operators agree that the data is either committed or that the commit is aborted and rolled back.
Implementing the Two-Phase Commit Operator in Flink
This can be a little bit complicated to manage, and that’s why Flink extracts the common logic of the two-phase commit protocol into the abstract `TwoPhaseCommitSinkFunction` class.
Let’s discuss how to extend a `TwoPhaseCommitSinkFunction` on a simple file-based example. We need to implement only four functions and present their implementations for an exactly-once file sink:
-
beginTransaction - to begin the transaction, we create a temporary file in a temporary directory on our destination file system. Subsequently, we can write data to this file as we process it.
-
preCommit - on pre-commit, we flush the file, close it, and never write to it again. We’ll also start a new transaction for any subsequent writes that belong to the next checkpoint.
-
commit -on commit, we atomically move the pre-committed file to the actual destination directory. Please note that this increases the latency in the visibility of the output data.
-
abort - on abort, we delete the temporary file.
As we know, if there’s any failure, Flink restores the state of the application to the latest successful checkpoint. One potential catch is in a rare case when the failure occurs after a successful pre-commit but before notification of that fact (a commit) reaches our operator. In that case, Flink restores our operator to the state that has already been pre-committed but not yet committed.
We must save enough information about pre-committed transactions in checkpointed state to be able to either abort or commit transactions after a restart. In our example, this would be the path to the temporary file and target directory
TwoPhaseCommitSinkFunction takes this scenario into account, and it always issues a preemptive commit when restoring state from a checkpoint. It is our responsibility to implement a commit in an idempotent way. Generally, this shouldn’t be an issue. In our example, we can recognize such a situation: the temporary file is not in the temporary directory, but has already been moved to the target directory.
There are a handful of other edge cases that `TwoPhaseCommitSinkFunction` takes into account, too. Learn more in the Flink documentation.
Wrapping Up
If you’ve made it this far, thanks for staying with us through a detailed post. Here are some key points that we covered:
-
Flink’s checkpointing system serves as Flink’s basis for supporting a two-phase commit protocol and providing end-to-end exactly-once semantics.
-
An advantage of this approach is that Flink does not materialize data in transit the way that some other systems do--there’s no need to write every stage of the computation to disk as is the case is most batch processing.
-
Flink’s new `TwoPhaseCommitSinkFunction` extracts the common logic of the two-phase commit protocol and makes it possible to build end-to-end exactly-once applications with Flink and external systems that support transactions
-
Starting with Flink 1.4.0, both the Pravega and Kafka 0.11 producers provide exactly-once semantics; Kafka introduced transactions for the first time in Kafka 0.11, which is what made the Kafka exactly-once producer possible in Flink.
-
The Kafka 0.11 producer is implemented on top of the `TwoPhaseCommitSinkFunction`, and it offers very low overhead compared to the at-least-once Kafka producer.
We’re very excited about what this new feature enables, and we look forward to Flink supporting additional data sinks with the TwoPhaseCommitSinkFunction in the future.

You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
