














This Fall I became more active with the Apache Flink community in my role as Technical Evangelist at data Artisans, after almost 8 years in Big Data. At October’s Bay Area Flink Meetup, I discussed my impressions of Flink from the point of view of a technical practitioner who is new to Flink but has been working in the Big Data space for a while. As I was speaking, I was struck by the focus, investment, and curiosity in the room. In retrospect, this fits with my overall impressions of Apache Flink and the Apache Flink community. Below I’d like to cover 5 early impressions of Apache Flink and why companies should explore Flink early in their stream processing journey.
- Stream Processing has been an elusive end-point of Big Data projects for long.
I got involved in Big Data in 2010 when the state of the art was Distributed File Systems, MapReduce, Hive, Pig, Flume, and HBase. In reality, however, processing data with as low latency as possible has been a challenge for a long time. For example, within my first few months of working in the space, a customer asked me how to produce an up-to-date aggregation over a tumbling five-minute window of a growing table using Hive. It’s an extremely difficult query, which the customer and I never figured out. MapReduce, Hive, Pig and later Spark addressed the ability to process high volumes of disparate data with the use of smaller and smaller batch operations to approximate low latency results. Some frameworks like Flume and later Kafka allowed easier ingestion, encapsulation, and transport of data. Other query systems such as HBase, Cassandra, Presto, and Impala gave interactive access to freshly ingested data in approximately real-time. However, all of these projects miss the mark for what the customer and business user really need: a representation of data as a stream and the ability to do in-stream complex/stateful analytics. Customers and end-users wrangle with the latency gap in all kinds of interesting and expensive ways.
- The growth of Apache Flink in 2018 has been nothing short of phenomenal.
A recent Qubole survey placed Apache Flink as the fastest growing engine in the Big Data / Hadoop ecosystem in 2018 with a whopping 125% increase in adoption in comparison to the same survey in 2017. This adoption bump has made such an impression that Datanami couldn’t help but mention it in two articles that are not even about Flink. This article laments the increasing complexity of the Big Data ecosystem, touching on the proliferation of projects, and the risk involved in adopting the wrong technology for the use case, but goes out of its way to call out Flink’s incredible growth in adoption. This piece on Cloudera’s Mike Olson discusses the evolution of the space away from “zoo animal wrangling” to solving problems of the enterprise, but it nonetheless tips a hat to Flink’s squirrel with adoption growth that Cloudera’s favorite (and darn good query engine) Impala cannot beat. Sometimes the best animal in the zoo isn’t just what you expect.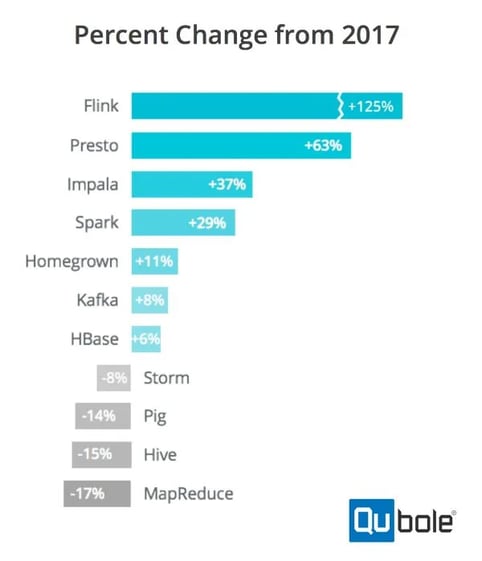 It’s worth noting that while data Artisans supports Flink, sells products around Flink, and employs many of its original creators and committers, most of the adoption and use of Flink today happens outside the scope of data Artisans in companies such as Netflix, Alibaba, Uber andLyft, among others.
It’s worth noting that while data Artisans supports Flink, sells products around Flink, and employs many of its original creators and committers, most of the adoption and use of Flink today happens outside the scope of data Artisans in companies such as Netflix, Alibaba, Uber andLyft, among others.
- Flink’s layered abstractions are extremely expressive and enable you to naturally conceptualize your data.
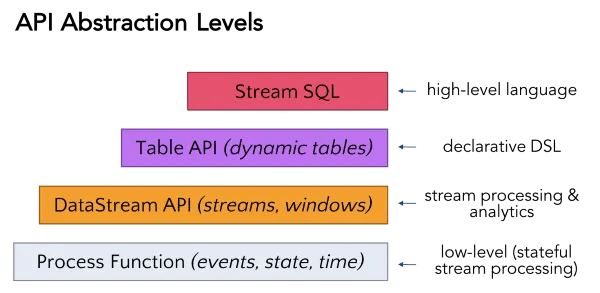
After years of working with customary Hadoop projects such as MapReduce, it’s refreshing to be given constructs of stream, state, time and snapshots as the building blocks of event processing rather than incomplete concepts of keys, values, and execution phases. My impression is that Flink is far and away the most expressive in terms of interfaces and how those interfaces tie to the capabilities of the underlying platform. The SQL interface, for example, supports tumbling windows and now complex event processing. As shown on the slide below, the tumbling time window example — that I had a hard time with all those years ago — can be expressed in simple SQL. The slide also shows similar expressiveness at both the streaming API and processFunction levels of abstraction.
- We’re seeing an emergence of encoded best practices.
One of the places a vendor can add significant and appropriate value to an active open source project is to encode expertise and best practice in a well-built product. Well-adopted open source projects tend to become broad and expansive in choices and configurability as they’re run in specific production environments.
data Artisans has encoded some of its opinions backed by their own experience and best practices established by Flink’s user community. As an example, for deployment Apache Flink supports YARN, Mesos, Kubernetes and Standalone deployments. Similarly, end users of Flink tend to run Flink-based applications rather than Flink jobs, which is the highest execution abstraction available in the project. For the Application Manager of data Artisans Platform, the company introduces the concept of an Application to Flink, and it settles on Kubernetes for deployment of Flink, encoding a useful and scalable best practice of one application per job per cluster. These kinds of simple decisions and encoded best practices serve to reduce the time to value of new adoptions of Flink, saving users the hassle of having to settle these kinds of issues over and over again. Since it encodes best practices, data Artisans Platform Application Manager isn’t just for production deployments: it’s good for getting started with Flink as well.
Download your data Artisans Platform VM trial here or check the data Artisans Platform for Kubernetes here.
- Flink succeeds in use cases where other projects fall short.
There are many great production uses of Flink for stream processing. You can find in-depth discussions from Alibaba, Netflix, Lyft, Uber, DriveTribe and others on their adoption of Flink to address the stream processing needs of their business. One thing I noted about many of these discussions is that they always tried something else first.
In a reference to another project’s micro-batching paradigm, Alibaba writes, “The first approach is to use batch as a starting point then try to build streaming on top of batch. This likely won’t meet strict latency requirements, though, because micro-batching to simulate streaming requires some fixed overhead–hence the proportion of the overhead increases as you try to reduce latency.”
In the description of their Flink Forward talk, Shriya Arora from Netflix writes “Historically we have done this joining of large volume data-sets in batch. However we asked ourselves if the data is being generated in real-time, why must it not be processed downstream in real-time?”
Likewise, in their discussion of their Flink-based platform AthenaX, Uber writes that they went through Apache Storm and Apache Samza before adopting Flink: “These solutions, however, were not yet ideal. Users were either forced to implement, manage, and monitor their own streaming analytics applications or were limited to fetching answers for a pre-defined set of questions.”
It seems to me that at first glance, architectures such as micro-batching, lambda architectures, and adjunct stream processing technologies and alternative stream processing projects, all seem adequate... until one discovers through painful experience that requirements around low latency processing and complex analysis cannot be met in an inexpensive, scalable and fault-tolerant way.
My suggestion is therefore not to subject yourself to the pain of adopting the wrong technology first, and to give Flink an early try on your stream processing problem. The pattern of adoption demonstrates people go too far down the wrong paths first.
I’m looking forward to further participating in Apache Flink’s emergence worldwide as the most significant and preeminent stream processing technology choice. Please stay interested and engaged, as we’re going to continue the effort to bring Flink to the world through a combination of blogs like this one, public and private training, and conference talks.



You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
