














Note: This article is a summary of the more detailed article How to factorize a 700 GB matrix with Apache Flink™.
Recommender Systems and Matrix Factorization
Recommender Systems are a very successful application of large scale data processing. They are used to recommend new items of interest to users of a service, such as new movies on Netflix, or shopping articles on Amazon. Recommender systems have become an essential part of most web-based services to enhance the user experience. A powerful approach for implementing recommenders are the so called "latent factor models", a special case of the collaborative filtering techniques, which exploit the similarity between user tastes and item characteristics: If user A andB are similar, then items liked by user A make good recommendations for userB. These latent factor models have become known to a wider audience as the most successful technique in the Netflix Prize competition (see here for a good summary). The central step is to compute a low-rank factorization of the sparse rating matrix into a user- and an item matrix:

The result of this computation is a set of factors for each user and item that express how high the user and item score in a certain dimension (sometimes these dimension can be found to correlate with intuitive concepts, like movie/music genres). If a user and an item score high in the same factors, the user probably likes the item.
Implementing Matrix Factorization in Apache Flink™
We implemented the popular Alternating Least Squares (ALS) algorithm for matrix factorization on top of Apache Flink™'s Scala API. ALS is an iterative algorithm that alternatingly assumes one of the factor matrices as fixed and computes the other matrix, minimizing the Root Mean Square Error (RMSE) of the solution over the iterations. A good introduction to ALS and can be found in this paper. ALS is a computation- and communication-intensive algorithm. Various different flavors of implementing ALS on top of general-purpose data processing frameworks have been published in the recent years. We choose a variant that operates on sub-blocks of the matrices (rather than individual vectors) which has been shown to reduce overall network communication costs. This is also the variant used in Apache Spark's MLLib, which we based our implementation on. Flink's data flow plan of the ALS iteration is shown in the figure below. We will post a follow-up article with more details and our experience with implementing other variants of ALS. The code of the implementation is available in this Github repository, and we plan to contribute this to the Flink codebase in the near future together with a suite of other Machine Learning algorithms.

Experiments on Google Compute Engine
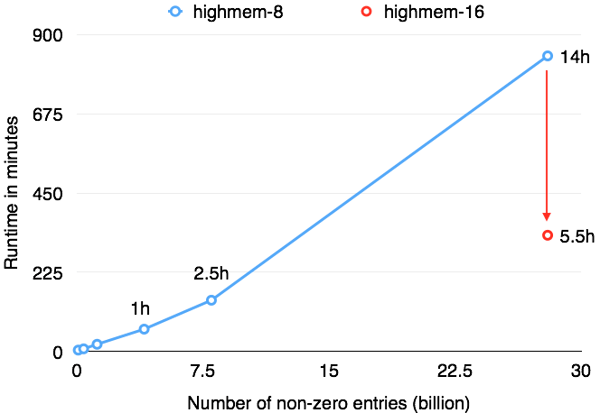
We ran a series of experiments with our ALS implementation on Google Compute Engine. We scaled the matrix to a size of 40 million users, 5 million items, and an average of 700 ratings per user, making it a total of 28 billion ratings. We ran all experiments with 50 latent factors, for 10 iterations. For comparison: Netflix reported to have 5 billion ratings 2012. While 700 explicit ratings per user can be considered overly many, implicit ratings (products viewed, songs played, ...) can easily become that many and more. For the experiments, we used two cluster setups:
-
40 medium instances ("n1-highmem-8" - 8 cores, 52 GB RAM)
-
40 large instances ("n1-highmem-16" - 16 cores, 104 GB RAM)
Both cluster setups use HDFS on disks for the rating matrix input, and Google Compute Engine's local SSDs for spilling intermediate results, sorts, and hash tables. The following figure shows how Flink’s performance scales with the data size using either 40 medium GCE machines (blue line), or 40 large GCE machines (red line). For a small dataset (4 million users, 500k items), Flink was able to run 10 iterations of ALS in just about 20 minutes. For the full dataset of 28 billion ratings (40 million users, 5 million items), Flink was able to finish the job in 5 hours and 30 minutes. This means a fresh recommendation model daily, even for an extremely large corpus of ratings.
Note that while both the input data size (700 GB) and the sizes of the low-rank matrices (8.5 GB and 1.5 GB) are well below the aggregate memory of the cluster, the intermediate results (the vectors and factors exchanged between the user/item blocks) are several terabytes in size. In addition, two copies of the ratings matrix are cached - one partitioned by user, one partitioned by item. Many of the operations hence heavily rely on robust shuffling and out-of-core capabilities and use the local SSD storage.
What are the secrets?
To support the above algorithm implementation efficiently on the given cluster setup, we relied heavily on Flink’s pipelined shuffles (that avoid materializing intermediate results) and its robust and efficient de-staging from in-memory to out-of-core processing. Furthermore, we found four new crucial features which we added to the system:
-
Handling very large records (FLINK-1296): While many data processing programs work on a large number of small records (billions of records of a few bytes to megabytes), this ALS implementation works on comparatively few records of large size (several 100 MB). We added extra code paths to the internal sort algorithms to support memory efficient external sorting and merging of such large records.
-
Pipelined group operations / group sorting (FLINK-658): Building the matrix info blocks requires reduce functions to work on large groups of data. Flink supports streaming such groups through reduce functions to avoid collecting all objects, scaling to groups that are exceeding memory sizes. We added support to have the objects within the group stream sorted on additional fields.
-
Memory sensitive network stack: We tuned the network stack code that serializes records and breaks them into frames for network transfer, making sure that the subsystem does not hold onto many large objects concurrently.
-
Custom partitioning (FLINK-1249): Flink now supports user specified partitioners which allow to control how the data is distributed across the cluster. This is especially important if the user operates on few data items and wants to guarantee that it is evenly distributed.
Code and further reading
For our experiments, we used a slightly modified version of the Apache Flink 0.8 development branch, which had all of the above additions. Most of the modifications have been released as part of Flink’s 0.8.0 release. The remaining ones are going into the 0.9 releases.
References:

You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
