













A common requirement in the area of data engineering is to first process existing historical data before processing continuously live data. Processing existing data first is also referred to as bootstrapping the system.
How to easily achieve this with Apache Flink? In this blog-post we will look at Flink's HybridSource which is specifically designed for such a task. If you want to clone the repository with the code from this blog post, use
git clone https://github.com/ververica/lab-flink-hybridsource.git
Dataflow
As a demo example, we will implement the following data pipeline as a Flink Job.
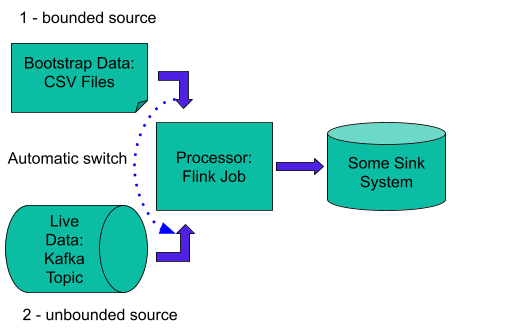
Fig. 1 - Flink job graph which consumes data from CSV files and then switches to Kafka topic.
In order to process data sources sequentially and switch from one to another as per the job graph topology, we will first add a FileSource with CSV data files and then a KafkaSource which is going to provide an unbounded source of data.
Data Preparation
In order to prepare data files in CSV format, we will write a special one-time Flink Job.
For all code examples we will use Scala and its awesome scala-cli tool. Please install the latest version of it in your environment, if you want to reproduce code examples yourself.
Create file gen-data.sc with the following code:
//> using dep "org.flinkextended::flink-scala-api:1.17.1_1.0.0"
//> using dep "org.apache.flink:flink-clients:1.17.1"
//> using dep "org.apache.flink:flink-csv:1.17.1"
//> using dep "org.apache.flink:flink-connector-files:1.17.1"
//> using dep "org.apache.flink:flink-table-runtime:1.17.1"
//> using dep "org.apache.flink:flink-table-planner-loader:1.17.1"
import org.apache.flink.table.api._
import org.apache.flink.connector.datagen.table.DataGenConnectorOptions
import org.apache.flink.api._
import org.apache.flink.api.serializers._
import _root_.java.lang.{Long => JLong}
val env = StreamExecutionEnvironment.getExecutionEnvironment
val settings = EnvironmentSettings.newInstance.inStreamingMode.build
val table = TableEnvironment.create(settings)Then append this block of code which represents record schema:
val schema = Schema.newBuilder
.column("id", DataTypes.INT())
.column("bid_price", DataTypes.DOUBLE())
.column("order_time", DataTypes.TIMESTAMP(2))
.buildAs you can see, our record contains three columns: id, bid_price and order_time.
Then append one more block of code which is using Table API and datagen connector to store data in CSV format into a specific file system path:
table.createTemporaryTable(
"SourceTable",
TableDescriptor
.forConnector("datagen")
.schema(schema)
.option(DataGenConnectorOptions.NUMBER_OF_ROWS, JLong(1000))
.option("fields.id.kind", "sequence")
.option("fields.id.start", "1")
.option("fields.id.end", "10000")
.build
)
val currentDirectory = _root_.java.io.File(".").getCanonicalPath
table.createTemporaryTable(
"SinkTable",
TableDescriptor
.forConnector("filesystem")
.schema(schema)
.option("format", "csv")
.option("sink.rolling-policy.file-size", "124 kb")
.option("path", s"file://$currentDirectory/sink-table")
.build
)
table.executeSql("insert into SinkTable select * from SourceTable").printAssuming that gen-data.sc file is in your current shell directory, run scala-cli via the following command:
scala-cli gen-data.sc
Once this script is executed, we get the following set of CSV files in the current shell sink-table directory:

Below are data records in one of the CSV files:
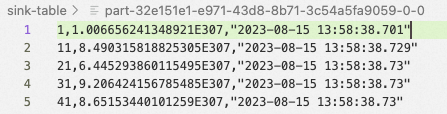
Each file is part of the generated data set. The number of files can be controlled by changing the values of sink.rolling-policy.file-sizeand DataGenConnectorOptions.NUMBER_OF_ROWS in the gen-data.sc code.
Now let’s generate similar data for the second source, which is the Kafka topic. For that you would need to have a Kafka cluster which you can use for further steps in this blog post. The Kafka version used to test all code examples in this blog-post is 2.7. One Kafka broker will be enough for testing.
In the same Scala file that we used for CSV data generation, replace SinkTable with the following:
val brokers = "<put-your-kakfa-host-here>:9092"
table.createTemporaryTable(
"SinkTable",
TableDescriptor
.forConnector("kafka")
.schema(schema)
.option("properties.bootstrap.servers", brokers)
.option("topic", "bids")
.option("format", "csv")
.option("value.format", "csv")
.buildEnter your Kafka broker hostnames as a comma-separated list. The hostname(s) must be accessible from the machine where the Scala script is executed. After running the updated script, we get data in the Kafka topic “bids”. Below we can see an example of data stored in the topic:
# kafka-console-consumer --bootstrap-server $BOOTSTRAP_SERVER --topic bids --from-beginning
10002,1.312920916299031E308,"2023-08-15 14:37:35.411"
10012,2.495268527292221E307,"2023-08-15 14:37:35.412"
10022,3.9478571741612126E307,"2023-08-15 14:37:35.412"Flink Job Implementation
Create one more Scala script called hybridSouce.sc and paste below content into it:
//> using dep "org.flinkextended::flink-scala-api:1.17.1_1.0.0"
//> using dep "org.apache.flink:flink-clients:1.17.1"
//> using dep "org.apache.flink:flink-csv:1.17.1"
//> using dep "org.apache.flink:flink-connector-files:1.17.1"
//> using dep "org.apache.flink:flink-connector-kafka:1.17.1"
import org.apache.flink.api._
import org.apache.flink.api.serializers._
import org.apache.flink.connector.file.src.FileSource
import org.apache.flink.connector.file.src.reader.TextLineInputFormat
import org.apache.flink.connector.file.src.impl.StreamFormatAdapter
import org.apache.flink.connector.kafka.source.KafkaSource
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer
import org.apache.flink.connector.base.source.hybrid.HybridSource
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.common.eventtime.WatermarkStrategy
import org.apache.flink.core.fs.Path
val currentDirectory = _root_.java.io.File(".").getCanonicalPath
val fileSource = FileSource
.forBulkFileFormat(
StreamFormatAdapter(TextLineInputFormat()),
Path(s"$currentDirectory/sink-table")
)
.build
val switchTimestamp = -1L
val brokers = "<put-your-kakfa-host-here>:9092"
val kafkaSource = KafkaSource
.builder[String]()
.setBootstrapServers(brokers)
.setTopics("bids")
.setStartingOffsets(OffsetsInitializer.timestamp(switchTimestamp + 1))
.setValueOnlyDeserializer(SimpleStringSchema())
.build
val hybridSource = HybridSource
.builder(fileSource)
.addSource(kafkaSource)
.build
val env = StreamExecutionEnvironment.getExecutionEnvironment
env
.fromSource(hybridSource, WatermarkStrategy.noWatermarks(), "combined")
.print()
env.execute()Let’s review this code to understand what it does:
- First of all we define two Flink sources: one for files and one for the Kafka topic. The Kafka topic offset is eventually set to 0, but it can be based on some user-defined offset in case the production pipeline needs to skip some historical data when starting to consume a Kafka topic.
- Then we combine both sources via HybridSource builder. There can be as many sources as needed. The main idea here is that all sources are bounded and the last source in the chain should be unbounded. Such composition allows Flink to switch data consumption once a bounded data source is fully consumed.
- Finally, we use the hybrid source to create a DataStream via the “fromSource” method.
There is an important point that the hybrid source API requires all combined sources to be based on the same type T; in the above example it is String type. If you have different record types among the sources these can be tackled by still using String as the input type and adding a “map” operator right after the hybrid source, to convert the string value into some typed value based on Scala case class or Java class.
Change the “brokers” variable value by setting your real Kafka hostname into it. Now let’s run this Flink Job via the following command:
> scala-cli hybridSource.scThis results in the following console output:
…
2> 935,1.3486879258636198E308,"2023-08-15 13:58:38.741"
2> 945,1.2010058239019397E308,"2023-08-15 13:58:38.741"
2> 955,4.153541843468437E307,"2023-08-15 13:58:38.741"
…
9> 10970,2.2001341438733312E307,"2023-08-15 14:37:35.414"
9> 10980,1.129258179257586E308,"2023-08-15 14:37:35.414"
9> 10990,1.3994484424740486E308,"2023-08-15 14:37:35.414"
9> 11000,1.6970222740482843E308,"2023-08-15 14:37:35.414"We can see that at the beginning of the data output we have the “id” column (first column from the left) within a range of 1 … 10000, which comes from the CSV files. Closer to the end of the output there is data with the “id” column in the range of 10001 … 20000, which comes from the Kafka topic.
Conclusion
Using HybridSource we can easily bootstrap a Fink Job state from different data sources before switching to the main data source. HybridSource was introduced in Flink v1.14. Before that you needed to implement a source switch somewhere in the user space by writing some tricky SourceFunction, which increased the overall Flink job complexity.
For more information on HybridSource see Flink Improvement Process Page FLIP-150
You may also like

Zero Trust Theater and Why Most Streaming Platforms Are Pretenders

No False Trade-Offs: Introducing Ververica Bring Your Own Cloud for Microsoft Azure

Data Sovereignty Is Existential Most Platforms Treat It Like a Feature
