














This is a guest post from Xiaowei Jiang, Senior Director of Alibaba’s search infrastructure team. The post is adapted from Alibaba’s presentation at Flink Forward 2016, and you can see the original talk from the conference here
Alibaba is the largest e-commerce retailer in the world. Our annual sales in 2015 totalled $394 billion--more than eBay and Amazon combined. Alibaba Search, our personalized search and recommendation platform, is a critical entry point for our customers and is responsible for much of our online revenue, and so the search infrastructure team is constantly exploring ways to improve the product. What makes for a great search engine on an e-commerce site? Results that, in real-time, are as relevant and accurate as possible for each user.
At Alibaba’s scale, this is a non-trivial problem, and it’s difficult to find technologies that are capable of handling our use cases. Apache Flink® is one such technology, and Alibaba is using Blink, a system based on Flink, to power critical aspects of its search infrastructure and to deliver relevance and accuracy to end users.
In this post, I’ll walk through Flink’s role in Alibaba search and outline the reasons we chose to work with Flink on the search infrastructure team. I’ll also discuss how we adapted Flink to meet our unique requirements with Blink and how we are working together with data Artisans and the Flink community to contribute these changes back to Flink. We are actively transitioning our system from Blink to vanilla Apache Flink once we have successfully merged our modifications into the open source project.
Part 1: Flink in Alibaba Search
Document Creation
The first step in providing users with a world-class search engine is building the documents that will be available for search. In Alibaba’s case, the document is made up of millions of product listings and related product data. Search document creation is a challenge because product data is stored in many different places, and it’s up to the search infrastructure team to bring together all relevant information to create a complete search document. Generally speaking, this is a 3-stage process:
-
Synchronize all product data from disparate sources (e.g. MySQL, distributed file systems) into one HBase cluster.
-
Join data from different tables together using business logic to create a final, searchable document. This is an HBase table that we call our ‘Result’ table.
-
Export this HBase table as a file or as a set of updates.
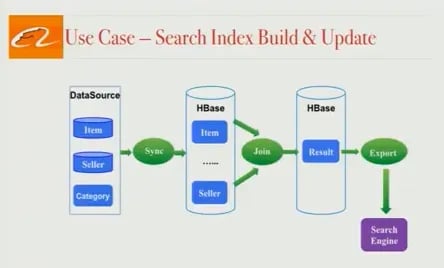
All 3 of these stages actually run on 2 different pipelines in a classical ‘lambda architecture’: a full-build pipeline and an incremental build pipeline.
-
In the full-build pipeline, we process all data sources, and this is traditionally a batch job.
-
In the incremental pipeline, we process updates that occur after the batch job is finished. For instance, sellers can modify price or description or inventory availability might change. This information must be reflected in search results as quickly as possible. The incremental-build pipeline is traditionally a streaming job.
Real-time A/B testing of search algorithms
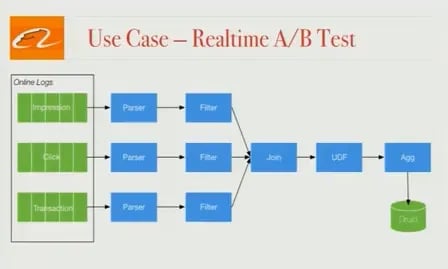
Our engineers test different search algorithms on a regular basis and need to be able to evaluate performance as quickly as possible. Right now, this evaluation happens once a day, but we’d like to do the analysis in real-time, and so we used Blink to build a real-time A/B testing framework. Online logs (impressions, clicks, transactions) are collected and processed by a parser and filter then later joined together using some business logic. Next, the data is aggregated, and the aggregated result is pushed to Druid; inside Druid, it’s possible to write a query to perform complex OLAP analysis on the data and see how well different algorithms are performing.
Online machine learning
There are a couple of applications here, and first, we’ll discuss real-time feature updates. Some of the features used in Alibaba’s search ranking are product CTR, product inventory, and total number of clicks. These data change over time, and if we can use the most recent data available, we’ll be able to offer a more relevant search ranking to our users. Our Flink pipeline provides us with online feature updates and has given a significant boost on conversion rate.
Second, there are specific days of the year (such as Singles Day) where products are heavily discounted--sometimes up to 50%--and therefore, user behavior changes dramatically. Transaction volume is huge, often many times higher than what we see in a normal day. Our previously-trained models are useless in this scenario, and so we use our logs and a Flink streaming job to power online machine learning, building models that take into account the real-time data. The result is a much higher conversion rate on these uncommon, but very important, sale days. 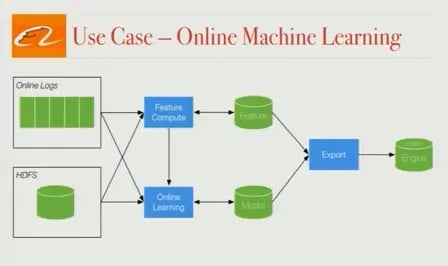
Part 2: Choosing a framework to solve the problem
When we chose Flink to power our search infrastructure, our evaluation included the following four categories. Flink met our requirements in all four.
-
Agility: It was our goal to be able to maintain one codebase for our entire (2-pipeline) search infrastructure process. And we wanted an API that was high-level enough for us to express our business logic.
-
Consistency: Changes to the seller or product databases must be reflected in final search results, and so the search infrastructure team requires at-least-once semantics (and for some other Flink use cases in the company, we have exactly-once requirements).
-
Low latency: When inventory availability changes, this must be reflected in search results very quickly; for example, we don’t want to give a high search ranking to a sold-out product.
-
Cost: Alibaba processes lots of data, and at our scale, an efficiency improvement results in significant cost savings. We need a framework that handles high-throughput efficiently.
More broadly speaking, there are 2 ways to think about unified batch and stream processing. The first approach is to use batch as a starting point then try to build streaming on top of batch. This likely won’t meet strict latency requirements, though, because micro-batching to simulate streaming requires some fixed overhead--hence the proportion of the overhead increases as you try to reduce latency. At our scale, 1000s of tasks would need to be scheduled for each microbatch, the connection re-established, and state reloaded. So at some point, the micro-batch approach becomes too costly to make sense.
Flink, on the other hand, uses streaming as a fundamental starting point and builds a batch solution on top of streaming, where a batch is basically a special case of a stream. With this approach, we don’t lose the benefit of our optimizations in batch mode--when a stream is finite, you can still do whatever optimization you’d like to do for batch processing.
Part 3: What is Blink?
Blink is a forked version of Flink that we have been maintaining to fit some of the unique requirements we have at Alibaba. At this point, Blink is running on a few different clusters, and each cluster has about 1000 machines, so large-scale performance is very important to us. Blink’s improvements generally cover two areas:
-
Making the Table API more complete so that we can have the same SQL for batch and streaming
-
A more robust YARN mode that’s still 100% compatible with Flink’s API and broader ecosystem
Table API
We first added support for user-defined functions to make it easy to bring our unique business logic into Flink. We also added a stream-to-stream join, which is a non-trivial task but relatively straightforward in Flink due to Flink’s first-class support for state. Next, we added a few different aggregations, the most interesting one probably being distinct_count, as well as windowing support. (Editor’s note: FLIP-11 covers a range of Table API and SQL improvements for Flink related to the features listed above and is recommended reading for anyone interested in the topic.) 
Next, we’ll cover runtime improvements, which we can break into four separate categories.
Blink on Yarn
When we started our project, Flink supported 2 cluster modes: standalone mode and Flink on YARN. In YARN mode, a job couldn’t request and release resources dynamically and instead needed to grab all required resources up front. And different jobs might share the same JVM process, which favored resource utilization over resource isolation. Blink includes an architecture where every job has its own JobMaster to request and release resources as the job requires. And different jobs can’t run in the same Java process, which yields the best isolation between jobs and tasks. The Alibaba team is currently working with the Flink community to contribute this work back to the open source, and the improvements are captured in FLIP-6 (which extends to other cluster managers in addition to YARN).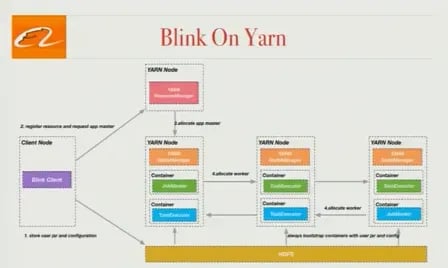
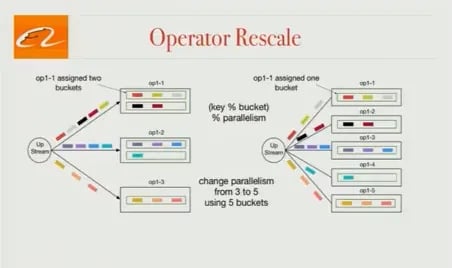
Operator Rescale
In production, our clients might need to change the parallelism of operators, but at the same time, they don’t want to lose state. When we started working on Blink, Flink did not support changing the parallelism of operators while maintaining state. Blink introduced the concept of “buckets” as the unit of state management. There are many more buckets than tasks, and each task will be assigned multiple buckets. When the parallelism changes, we’ll reassign buckets to tasks. Using this method, it’s possible to change the parallelism of operators and maintain state.
(Editor’s note: the Flink community has concurrently solved this issue for Flink 1.2 - the feature is available in the latest version of the master branch. Flink’s notion of “key groups” is largely equivalent with “buckets” mentioned above, but the implementation differs slightly in how the data structures back these buckets. For more information, check out FLINK-3755 in Jira.)
Incremental Checkpointing
In Flink, checkpointing happens in 2 stages: taking a snapshot of state locally, then persisting the snapshot of state to HDFS (or another storage system), and the entire snapshot of state is stored in HDFS with each snapshot. Our state was too large for this approach to be acceptable, and so Blink only stores the modified state in HDFS, and we’ve been able to improve checkpointing efficiency greatly. This modification enabled us to use large state in production. 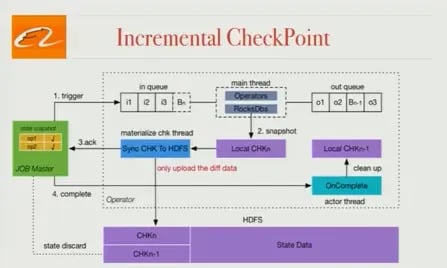
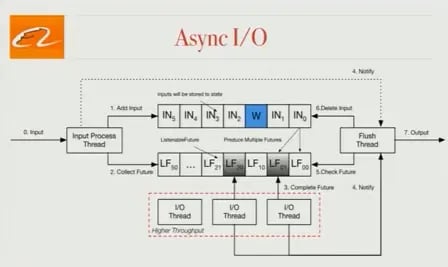
Asynchronous I/O
The production bottleneck for many of our jobs is accessing external storage like HBase. To solve this problem, we introduced Asynchronous I/O, which we’ll be working to contribute to the community and is described in detail in FLIP-12. (Editor’s note: data Artisans thinks that FLIP-12 is substantial enough to have its own, separate writeup at some point in the near future. So we’ll only briefly introduce the idea here, and for the time being, you should check out the FLIP writeup if you’d like to learn more. At the time of publishing, the code has already been contributed to Flink.)
Part 4: What’s next for Flink at Alibaba?
We’ll continue to optimize our streaming jobs, specifically, better handling of temporary skew and slow machines without negating the positive aspects of backpressure and faster recovery from failure. As was discussed by a number of different speakers at Flink Forward, we believe that Flink has great potential as a batch processor as well as a stream processor. We’re working to fully leverage Flink’s batch processing capabilities and hope to have a Flink batch mode in production in a couple months.
Another popular conversation topic from the conference is streaming SQL, and we’re continuing to add further SQL support and Table API support in Flink. And Alibaba’s business continues to grow, meaning that our jobs get larger and larger--it becomes increasingly important to make sure we can scale to even larger clusters. Very importantly, we look forward to continued collaboration with the community in order to contribute our work back to the open source so that all Flink users can benefit from the work we’ve put into Blink. We look forward to updating you on our progress at Flink Forward 2017.






