














Batch processing and stream processing are two very different models for processing data. Both have their strengths but suit different use cases. In this post we cover the differences, provide examples of use cases, and look at the ways the two models can work together.

Technology Evolution
Batch processing has its roots in the early days of computing. Batch systems automate repetitive tasks by periodically processing large numbers of records in a single batch. This opened the way for business process and office automation.
This kind of data processing is still relevant; the “payroll run” hasn’t gone away, but today you’re just as likely to find a batch processing system being used to assemble, move, and ingest data collections within a data pipeline.
The emergence of those data pipelines has brought an alternative model to center stage: stream processing. Instead of batching records, stream processing handles data as it comes in, in real time. In contrast to the predictable sources of batch data, stream data arrives from real-world sources, driven by real-world behaviors.
The modern data processing landscape is very different to the one from which batch systems emerged. Two key challenges dominate the technology choices:
- The need to manage and store massive volumes of data.
- The need to process massive volumes of data in real time.
Batch Processing
Batch processing operates in a relatively slow cycle, typically measured in hours, days or weeks. A typical batch job processes stored data and persists the results as newly stored data – whether making updates in place, as in database processing, or generating new files or records, as in a billing system. Updates or changes are applied immediately to all selected records, files or bytes in the batch. Efficient storage management is typically more critical than processing time, as long as the job can be performed within the designated period; daily jobs should complete within 24 hours, weekly jobs can’t take longer than a week.
Batch systems are common across retail, banking, and other service industries, where they manage order and transaction reconciliation, for example overnight matching of orders, accounts, and despatch. Conventional batch processing also drives reporting cycles within businesses, as well as longer term business trend analysis.
Modern Batch Processing
Alongside those more conventional functions, batch processing is important in modern data processing, where it is used to collect, assemble, and move data. Data pipelines rely heavily on cloud data stores, and batch processes are often at the heart of data management within and between cloud storage silos.

Batch processing can also play more than a back-end role; batch windows might sit alongside stream transaction windows in hybrid pipelines that perform backend reconciliation, while delivering real-time status updates to end users. Think of credit card swipes, online purchases, delivery tracking notifications, or inventory updates for warehouse workers – or robots!
Stream Processing
Stream processing emerged as a technology in the early years of this millennium. The typical use cases that drove it centered on financial market data, telecoms, and IP network traffic from the still-emerging World Wide Web, all of which generated massive volumes of dynamically changing time-series data. Most of the techniques used today can be traced back to those beginnings.
Stream Data Analytics
Unlike batch systems which wait for data to be collected and assembled before processing it, stream processing systems process data as soon as it is produced, generating real-time outputs from real-time data sources.

Think of a FinTech company detecting fraudulent transactions in real time, or a streaming service mining real-time insights from stream data analytics – the Netflix “You might also like…”.
The Modern Data Context
Across both private and public sectors, “Data Driven” has become the new mantra – from telecoms to healthcare, finance to transport, energy to entertainment – not just your favorite movie channel, but your kids’ favorite multiplayer online games.
Take a look at the graph of worldwide data volumes over the last decade and a half. The numbers are startling:
- Data volumes doubled roughly every two years, from two zettabytes in 2010 to 64 zettabytes in 2020.
- In the following decade, the numbers are on track to slow somewhat to between 20% and 25% growth year-on-year, to a predicted 181 zettabytes or more by 2030.
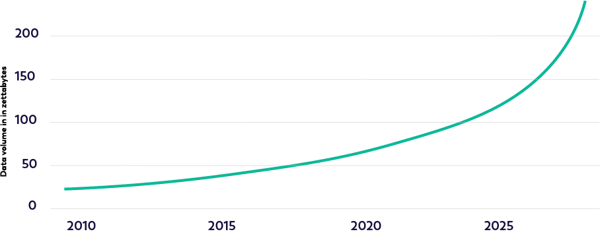
These are big numbers. A zettabyte is 1021 bytes, or a billion trillion bytes.
Let’s note too how little of that data survives beyond temporary storage: the same report estimates that just two percent of data was retained. Modern data is overwhelmingly transient. It's not a new idea that data has a half-life, where the decay rate measures data relevance. It's a useful way to understand what drives the streaming data model.
Transient Data
Transient data arises in real time from our everyday actions, and from the technologies we embed in our environment. We touch in and touch out of locations (transport systems), swipe cards (shops), click online (shopping, searching), trigger checkpoints (urban low emissions zones and tolls for drivers), install smart meters and even smart doorbells. We use our smartphones to initiate and take calls, and send and read messages, but we also use them to browse the web, shop, do our banking, and generally manage our online and real-world existence. All these interactions generate huge trails of data. Our life stories are in our data.
Technology Head to Head
All technologies have an upside and downside and everything has its place. If you are instrumenting a particle accelerator, a batch job is not your primary tool. But if you are googling the science, batch jobs have likely built the index.
Pros and Cons of Batch Processing
Pros
- Simplicity
- Scales efficiently
- Lossless, there’s no inherent time bound after which data is lost
- Deeper analysis – huge datasets can be processed and complex/deep calculations performed
- Schedule for cost, efficiency, or convenience – run in quiet times to reduce the load on your systems, or off-peak when electricity is cheap
- Requires minimal human interaction
Cons
- Timebound – large scale computation and large scale ingestions are slow
- Potential peak loads – batch windows are peaky and can push systems to their limits
Pros and Cons of Stream Processing
Pros
- Real-time results – modern stream platforms drive processing latencies to milliseconds for highly time-critical data
- More uniform loads – streams may have cycles, but overall loads are more uniform and predictable
Cons
- Complexity – real time anything is more complex, from design through developing and testing to support
- Potentially lossy – data not processed inside the given real-time bounds is lost by default
- One-touch – no multi-stage processing
- No rollbacks – failures can be difficult to troubleshoot, and the data may be gone
One Size Doesn’t Fit All
There is no one-size-fits-all solution for any data processing requirement, but asking the right questions will help you focus on the critical choices.

In practice batch and stream processing are often complementary and can be mixed and matched. For example, a modern retail business might use stream processing to capture real time purchase data, batch processing for overnight inventory management, and batch processing for monthly billings.
Even within a single data pipeline, as we saw from the example of cloud data management, batch and stream processing are not mutually exclusive. But it’s useful to identify the basic characteristics of each and match them against the data requirements.
Is real-time processing really needed?

If you don’t need to make real-time decisions – maybe overnight is good enough – batch processing might be your best option.
Is the loss of one record critical?

Stream processing may skip or miss data. Collect-and-batch offers greater resilience.
Do you have many concurrent data sources?
Concurrency flags a potential streaming requirement. Batch processing can handle multiple data sources, but not simultaneously.
Is your data unpredictable, unshaped, or unbounded?

Batch processing expects uniform and finite data. It excels at the ordinary. Extraordinary requirements need extraordinary solutions. Stream processing is your friend.
Welcome to Ververica!
Ververica Platform and Ververica Cloud are built on award winning Apache Flink®. Whether your data applications depend on pure batch or stream processing or require a mixed processing model, Ververica combines proven open source technologies with proprietary enhancements based on our expertise in powering massive scale data and transaction processing applications.
Ververica Platform
Ververica Platform is the leading private cloud solution for high data throughput stateful streaming applications and hybrid stream/batch processing. Streamline and simplify your Flink deployments and enjoy the speed advantage of our highly optimized processing engines compared to vanilla Apache Flink®.
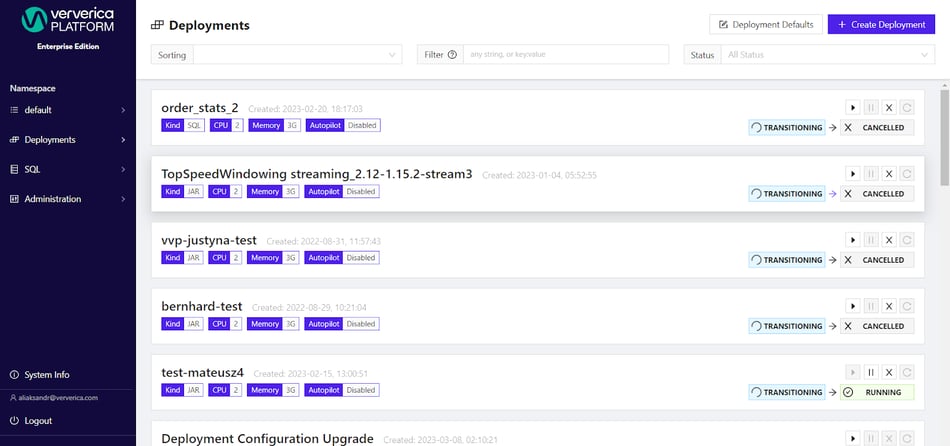
Ververica Platform powers production systems across the spectrum to enable global businesses from ecommerce and fintech to cloud IoT and more.
Ververica Cloud
Ververica Cloud builds on the same core Ververica technologies to deliver a fully managed cloud-native service, designed for easy deployment and management of your Flink applications.
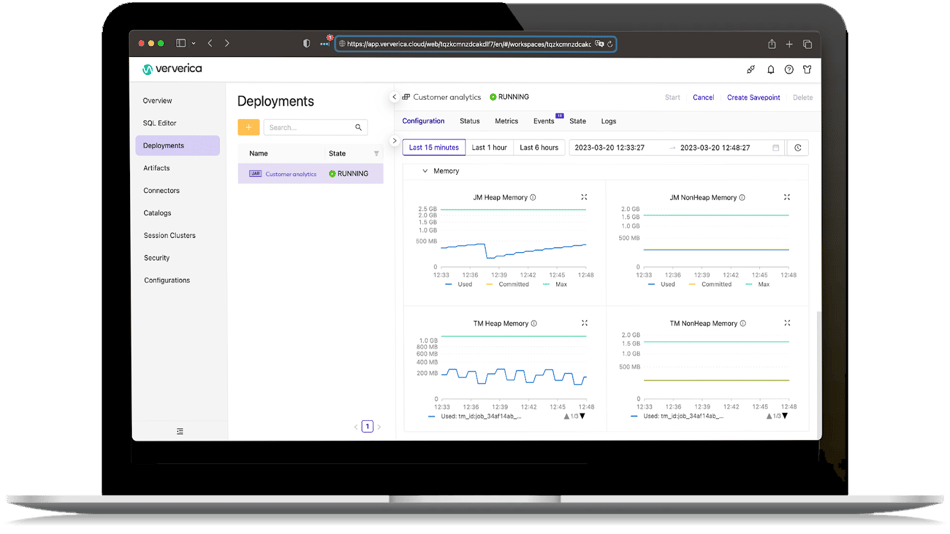
With all the advantages of Ververica Platform, it offers a turnkey cloud solution for maximum ease and speed of deployment.

You may also like

Meet the Flink Forward Program Committee: A Q&A with Lorenzo Affetti

Outrun Fraudsters with Agentic AI and Ververica

KartShoppe: Real-Time Feature Engineering With Ververica
